Posts
-
I'm Switching Into AI Safety
CommentsYou can read the title. As of last month, I’ve been winding down my existing robotics projects, and have switched to the AI safety team within Google DeepMind. Surprise!
It took me a while to start working on this post, because my feelings on AI safety are complicated, but changing jobs is a big enough life update that I have to write this post. Such is the life of a blogger.
The Boring Personal Reasons
I’ve been working on the robotics team for 8 years now, and I just felt like I needed to mix it up. It was a little unsettling to realize I had quietly become one of the most senior members of the team, and that I had been there longer than my manager, my manager before that, and my manager before that. Really, this is something I thought about doing three years ago, but then my puzzlehunt team won MIT Mystery Hunt, meaning we had to write next year’s Mystery Hunt. Writing Mystery Hunt took up all of my 2022, and recovering from it took up much of my 2023. (That and Tears of the Kingdom, but let’s not talk about that.)
Why change fields, rather than change within robotics? Part of me is just curious to see if I can. I’ve always found the SMBC “Seven Years” comic inspiring, albeit a bit preachy.

(Edited from original comic)
I believe I have enough of a safety net to be okay if I bomb out.
When discussing careers with someone else, he said the reason he wasn’t switching out of robotics was because capitalism rewards specialization, research especially so. Robotics was specialized enough to give him comparative advantages over more general ML. That line of argument makes sense, and it did push against leaving robotics. However, as I’ve argued in my previous post, I expect non-robotics fields to start facing robotics-style challenges, and believe that part of my experience will transfer over. I’m also not starting completely from zero. I’ve been following AI safety for a while. My goal is to work on projects that can leverage my past expertise, while I get caught up.
The Spicier Research Interests Reasons
The current way robot agents are trained can broadly be grouped into control theory, imitation learning, and reinforcement learning. Of those, I am a fan of reinforcement learning the most, due to its generality and potential to exceed human ability.
Exceeding human ability is not the current bottleneck of robot learning.
Reinforcement learning was originally a dominant paradigm in robot learning research, since it led to the highest success rates. Over the years, most of its lunch has been eaten by imitation learning methods that are easier to debug and show signs of life earlier. I don’t hate imitation learning, I’ve happily worked on several imitation learning projects, it’s just not the thing I’m most interested in. Meanwhile, there are some interesting applications of RL-style ideas to LLMs right now, from its use in RLHF to training value functions for search-based methods like AlphaProof.
When I started machine learning research, it was because I found learning and guiding agent behavior to be really interesting. The work I did was in a robotics lab, but I always cared more about the agents than the robots, the software more than the hardware. What kept me in robotics despite this was that in robotics, you cannot cheat the real world. It’s gotta work on the real hardware. This really focused research onto things that actually had real world impact, rather than impact in a benchmark too artificial to be useful. (Please, someone make more progress on reset-free RL.)
Over the past few years, software-only agents have started appearing on the horizon. This became an important decision point for me - where will the real-world agents arrive first? Game playing AIs have been around forever, but games aren’t real. These LLM driven systems…those were more real. In any world where general robot agents are created, software-only agents will have started working before then. I saw a future where more of my time was spent learning the characteristics of the software-hardware boundary, rather than improving the higher-level reasoning of the agent, and decided I’d rather work on the latter. If multimodal LLMs are going to start having agentic behaviors, moving away from hardware would have several quality of life benefits.
One view (from Ilya Sutskever, secondhand relayed by Eric Jang) is that “All Successful Tech Companies Will be AGI Companies”. It’s provocative, but if LLMs are coming to eat low-level knowledge work, the valuable work will be in deep domain expertise, to give feedback on whether our domain-specific datasets have the right information and whether the AI’s outputs are good. If I’m serious about switching, I should do so when it’s early, because it’ll take time to build expertise back up. The right time to have max impact is always earlier than the general public thinks it is.
And, well, I shouldn’t need to talk about impact to justify why I’m doing this. I’m not sitting here crunching the numbers of my expected utility. “How do we create agents that choose good actions” is just a problem I’m really interested in.

(I tried to get an LLM to make this for me and it failed. Surely this is possible with the right prompt, but it’s not worth the time I’d spend debugging it.)
The Full Spice “Why Safety” Reasons
Hm, okay, where do I start.
There’s often a conflation between the research field of AI safety and the community of AI safety. It is common for people to say they are attacking the field when they are actually attacking the community. The two are not the same, but are linked enough that it’s not totally unreasonable to conflate them. Let’s tackle the community first.
I find interacting with the AI safety community to be worthwhile, in moderation. It’s a thing I like wading into, but not diving into. I don’t have a LessWrong account but have read posts sent to me from LessWrong. I don’t read Scott Alexander but have read a few essays he’s written. I don’t have much interaction with the AI Alignment Forum, but have been reading more of it recently. I don’t go to much of the Bay Area rationalist / effective altruism / accelerationist / tech bro / whatever scene, but I have been to some of it, mostly because of connections I made in my effective altruism phase around 2015-2018. At the time, I saw it as a movement I wasn’t part of, but which I wanted to support. Now I see it as a movement that I know exists, where I don’t feel much affinity towards it or hatred against it. “EA has problems” is a statement I think even EAs would agree with, and “Bay Area rationalism has problems” is something rationalists would agree with too.
The reason AI safety the research topic is linked to that scene is because a lot of writing about the risks of AGI and superintelligence originate from those rationalist and effective altruist spaces. Approving of one can be seen as approving the other. I don’t like that I have to spill this much digital ink spelling it out, but that is not the case here. Me thinking AI safety is important is not an endorsement for or against anything else in the broader meme space it came from.
Is that clear? I hope so. Let’s get to the other half. Why do I think safety is worth working on?
* * *
The core tenets of my views on AI safety are that:
- It is easy to have an objective that is not the same as the one your system is optimizing, either because it is easier to optimize a proxy objective (negative log likelihood vs 0-1 classification accuracy), or because your objective is hard to describe. People run into this all the time.
- It’s easy to have a system that generalizes poorly because you weren’t aware of some edge case of its behavior, due to insufficient eval coverage, poor model probing, not asking the right questions, or more. This can either be because the system doesn’t know how to handle a weird input, or because your data is not sufficient to define the intended solution.
- The way people solve this right now is to just…pay close attention to what the model’s doing, use humans in the loop to inspect eval metrics, try small examples, reason about how trustworthy the eval metrics are, etc.
- I’m not sold our current tooling scales to better systems, especially superhuman systems that are hard to judge, or high volume systems spewing millions of reviewable items per second.
- I’m not sold that superhuman systems will do the right thing without better supervision than we can currently provide.
- I expect superhuman AI in my lifetime.
- The nearest-term outcomes rely on the current paradigm making it to superhuman AI. There’s a low chance the current paradigm gets all the way there. The chance is still higher than I’m comfortable with.
In so far as intelligence can be defined as the ability to notice patterns, pull together disparate pieces of information, and overall have the ability to get shit done, there is definitely room to be better than people. Evolution promotes things that are better at propagating or replicating, but it works slow. The species that took over the planet (us) is likely the least intelligent organism possible that can still create modern civilization. There’s room above us for sure.
I then further believe in the instrumental convergence theory: that systems can evolve tendencies to stay alive even if that is not directly what their loss function promotes. You need a really strong optimizer and model for that to arise, so far models do not have that level of awareness, but I don’t see a reason that wouldn’t happen. At one point, I sat down and went through a list of questions for a “P(doom)” estimate - the odds you think AI will wreck everything. How likely do you think transformative AI is by this date, if it exists how likely is it to develop goal-seeking behavior, if it has goals how likely are they to be power-seeking, if it’s power-seeking how likely is it to be successful, and so on. I ended up with around 2%. I am the kind of person who thinks 2% risks of doom are worth looking at.
Anecdotally, my AI timelines are faster than the general public, and slower than the people directly working on frontier LLMs. People have told me “10% chance in 5 years” is crazy, in both directions! There is a chance that alignment problems are overblown, existing common sense in LLMs will scale up, models will generalize intent correctly, and OSHA / FDA style regulations on deployment will capture the rare mistakes that do happen. This doesn’t seem that likely to me. There are scenarios where you want to allow some rule bending for the sake of innovation, but to me AI is a special enough technology that I’m hesitant to support a full YOLO “write the regulations if we spill too much blood” strategy.
I also don’t think we have to get all the way to AGI for AI to be transformative. This is due to an argument made by Holden Karnofsky, that if a lab has the resources to train an AI, it has the resources to run millions of copies of that AI at inference time, enough to beat humans due to scale and ease of use rather than effectiveness. (His post claims “several hundred millions of copies” - I think this is an overestimate, but the core thesis is correct.)
So far, a number of alignment problems have been solved by capitalism. Companies need their AIs to follow user preferences enough for their customers to use them. I used to have the view that the best thing for alignment would be getting AI products into customer’s hands in low stakes scenarios, to get more data in regimes where no mistake was too dangerous. This happened with ChatGPT, and as I’ve watched the space evolve, I…wish there was more safety research than there has been. Capitalism is great at solving the blockers to profitability, but it’s also very willing to identify economic niches where you can be profitable while ignoring the hard problems. People are too hungry for the best models to do due diligence. The level of paranoia I want people to have about LLMs is not the level of paranoia the market has.
Historically, AI safety work did not appeal to me because of how theoretical it was. This would have been in the early 2010s, but it was very complexity theory based. Bounded Turing machines, the AIXI formulation, Nash equilibria, trying to formalize agents that can take actions to expand their action space, and so on. That stuff is my jam, but I was quite pessimistic any of it would matter. I would like someone to be trying the theory angle, but that someone isn’t me. There is now a lot of non-theory work going on in AI safety, which better fits my skill set. You can argue whether that work is actually making progress on aligning superhuman systems, but I think it is. I considered Fairness in Machine Learning too, but a lot of existing literature focuses on fairness in classification problems, like algorithmic bias in recidivism predictors and bank loan models. Important work, but it didn’t have enough actions, RL, or agent-like things to appeal to me. The claims of a war between the fairness and alignment communities feel overblown to me. The average person I’ve met from either is not interested in trying to make a person “switch sides”. They’re just happy someone’s joining to make the field larger, because there is so much work to do, and people have natural inclinations towards one or another. Even if the sociologies of the fields are quite different, the fundamentals of both are that sometimes, optimization goes wrong.
I’m aware of the arguments that most AI safety work so far has either been useless or not that different from broader AI work. Scaling laws came from safety-motivated people and are the core of current frontier models. RLHF developments led to InstructGPT, then ChatGPT. Better evaluation datasets to benchmark models led to faster hill climbing of models without corresponding safety guarantees. Most recently, there’s been hype about representation engineering, an interpretability method that’s been adopted enthusiastically…by the open-source community, because it enables better jailbreaks at cheaper cost. Those who don’t think safety matters brands this as typical Silicon Valley grandstanding, where people pretend they’re not trying to make money. Those who care about safety a lot call this safetywashing, the stapling of “safety” to work that does not advance safety. But…look, you can claim people are insincere and confused about anything. It is a nuclear weapon of an argument, because you can’t convince people it’s wrong in the moment, you just continue to call them insincere or confused. It can only be judged by the actions you take afterwards. I don’t know, I think most people I talk about safety with are either genuine, or confused rather than insincere. Aiming for safety while confused is better than not aiming at all.
So, that’s what I’m doing. Aiming for safety. It may not be a permanent move, but it feels right based on the current climate. The climate may turn to AI winter, and if it does I will reconsider. Right now, it is very sunny. I’d like it if we didn’t get burned.
-
The Tragedies of Reality Are Coming for You
CommentsIn 2023, I was at an ML conference. The night was young, the drinks were flowing, and the topic turned to a question: “if you could take any machine learning subfield, and give all their resources to a different one, what are you killing and what are you boosting?”
I don’t remember what they boosted, but one person said they’d kill robotics. When I pushed them on it, they said robotics progress is too slow and nothing happens relative to everything else.
I think they were correct that robotics progress was slower than software-only machine learning subfields. But I would also add two things:
- The reason robot learning progress is slower is because it’s very hard to do anything without tackling the hard problems.
- The hard problems of robotics are not unique to robotics.
One of the very common refrains in robotics is “reality is messy”. I would extend it to reality is complicated, relative to code, and in robotics you’re often pushing a messy reality into an abstraction nice enough for code to act on it. As a field, computer science has spent decades creating nice abstraction layers between hardware and software. Code describes how to drive electricity to my hard drive, processor, and monitor, reliably enough that I don’t have to even think about it.

There’s a lot of benefit to doing this! Once you’ve done the hard work, and moved your progress towards acting in abstract logical space, everything’s easier. Code and data is incredibly replicable. I have copies of the file representing the draft of this blog post synced across 3 devices, and don’t even think about it.
However, to quote Joel Spolsky, all abstractions are leaky to some degree, and I’ve found those leaks tend to be bigger in robotics. There are many ways for things to go wrong that have nothing to do with the correctness of your code.
Is that because of something fundamental to the subject? A little bit. A lot of robot hardware is more experimental than a laptop or Linux server. Consumer robots aren’t as big an industry yet. “Experimental” tends to mean “weird, easier to reach failure states”.
But, I don’t think the hardware is the primary driver of friction. It’s reality that’s the friction. Benjamin Holson put it really well in his “Mythical Non-Roboticist” post:
The first kind of hard part is that robots deal with the real-world, imperfectly sensed and imperfectly actuated. Global mutable state is bad programming style because it’s really hard to deal with, but to robot software the entire physical world is global mutable state, and you only get to unreliably observe it and hope your actions approximate what you wanted to achieve.
Robotics research relies on building new bridges between reality and software, but that happens outside of robotics too. Any software that interfaces with reality will have imperfect knowledge of that reality. Any software that tries to affect real world change has to deal with reality’s global mutable state. Any software whose actions depend on what’s going on in reality invites adversarial sources of noise and complexity.
Game AI is an instructive example here. Chess AIs are reliably superhuman. However, some superhuman Go AIs are beatable if you play in a specific way, as discovered by Wang and Gleave et al, ICML 2023. Adversarial techniques found a strategy legible enough for humans to reproduce.
In Appendix G.2 one of our authors, a Go expert, was able to learn from our adversary’s game records to implement this [cyclic] attack without any algorithmic assistance. Playing in standard human conditions on the online Go server KGS they obtained a greater than 90% win rate against a top ranked KataGo bot that is unaffiliated with the authors. The author even won giving the bot 9 handicap stones, an enormous advantage: a human professional with this handicap would have a virtually 100% win rate against any opponent, whether human or AI. They also beat KataGo and Leela Zero playing with 100k visits each, which is normally far beyond human capabilities. Other humans have since used cyclic attacks to beat a variety of other top Go AIs.
Meanwhile, a few years ago OpenAI created a system that defeated the reigning world champions at Dota 2. After making the system available to the public to test its robustness, a team engineered a strategy that achieved a 10 game win streak.
Based on this, one pessimistic view you could hold is that connecting even a simple “reality” of a 19 x 19 Go board or Dota 2 is enough additional complexity to make robust behavior challenging. I think this view is unfair, because neither of these systems had robustness as a top-level objective, but I do think they’re an interesting case study.
There’s been a recent wave of hype around LLMs - what they can do, where they can apply. Implicit in all of this is the belief that LLMs can make significant changes to how people interface with technology, in their work and in their leisure. In other words, that LLMs will change how we mediate with reality. I’m actually on board this hype wave, to be specific I suspect foundation models are overhyped short-term and underhyped long term. However, that means all the messiness of reality is coming for a field that historically does a bad job at considering reality. At the same ML conference where this person said robotics was a waste of resources, I mentioned that we were experimenting with foundation models in real robots. I was told this seemed a bit scary, and I reassured them it was a research prototype. But I also find LLMs generating and executing software a little scary, and thought it was interesting they implicitly worried about one but not the other. Silicon Valley types have a bit of a paradox to them. They both believe that software can power amazing transformational startups, and that their software doesn’t merit contemplation or introspection. I consider the world of bits to be as much a part of reality as the world of atoms. Operating on a different level, but a part of it nonetheless.
I’ve noticed (with some schadenfreude) that LLM practitioners keep discovering pain points that robotics has hit before. “We can’t reproduce these training runs because it’s too capital-intensive.” Yeah, this has been a discussion point in robotics for at least a decade. “I can’t get Bing to gaslight me about Avatar 2’s release date, since it keeps pulling up news articles written about itself, and self-corrects before generation.” We’re now in a world where any publicly available Internet text can irrecoverably influence retrieval-augmented generation. Welcome to globally mutable state. Every time I see someone claim there’s a regression in ChatGPT’s behavior, I’m reminded of the conspiracies I and others have come up with to explain sudden, inexplicable drops in robot performance, and whether the problem is the model, the environment, or us extrapolating too much from anecdata.
There’s a saying that “all robot demos lie”, and people are discovering all LLM demos lie too. I think this is fundamentally impossible to avoid, because of the limitations of human attention. What’s important is evaluating the type, size, and importance of the lie. Did they show how it could generalize? Did they mention how cherry-picked the examples were? These questions become more complicated once you connect reality into the mix. Sure, Messi’s looked like a good player so far, but “can he do it on a cold rainy night in Stoke”?
What makes it complicated is that the answer to these questions isn’t always “no”. Messi could do it on a cold rainy night in Stoke. He was good enough. And that makes it hard, because being correct on a “yes” matters much more than being correct on a “no”. As LLMs get better, as AI becomes more common in daily life - we, as a society, will need to get increasingly good at deciding if the models have proven themselves. One of my main worries about the future is that we get bad at evaluating if the models have proven themselves. But, I expect roboticists to be ahead of the curve. We were complaining about evaluation years before claims of LLMs gaming common benchmarks. We were trying to get enough data to capture the long tail of self-driving long before “we need better data coverage” became the rallying cry of foundation model pretraining teams. Machine learning has lived in a bubble that was the envy of roboticists and chemists and biologists and neuroscientists, and as it starts to actually work, we’ll all be running into the same walls of reality that others have dealt with for years and years. These challenges can be overcome, but it’ll be hard. Welcome to the real world. Welcome to the pain.
-
Puzzlehunting 201
CommentsI’m good at puzzlehunts. I thought about equivocating this, but I’ve been on a winning MIT Mystery Hunt team twice and recently was on the 2nd place team for the Who Killed Ickey? treasure hunt. These were definitely team efforts, but I know I made significant contributions to both.
Those hunts cover the spectrum between puzzlehunts where the bottleneck is break-ins (Mystery Hunt), and ones where it’s more about pure execution speed (Ickey). I’ve noticed there isn’t a lot of advanced puzzlehunting content on the Internet, and I’ve been doing hunts for well over a decade, so I decided to write up some of the habits I’ve learned along the way.
If you are new to puzzlehunts, you are not the target audience of this post. I mean, feel free to keep reading! But I will be assuming a bunch of background knowledge and won’t be trying to explain what a puzzle is or what a meta is and so forth. If you’re new, I recommend Introduction to Puzzlehunts instead.
If you’ve done many puzzlehunts, not everything I say here will work for you. Puzzlehunting systems are a little like productivity systems: everyone’s is different, and people can be very opinionated about them even if they all share common themes. Your best bet is to try things out, take the parts that work, and ignore the parts that don’t.
You don’t have to get faster at puzzles. I like going fast because I’ve solved enough puzzles that I want to quickly get through grunt work to see the next a-ha. To a lesser extent, I find it fun to see how much information I can shortcut when solving a puzzle. That’s not a universal opinion. Most people will have more fun if they solve puzzles than if they don’t, but you don’t have to solve puzzles quickly to have fun.
This will spoil a few puzzles. I’ve tried to keep the spoilers as light as needed, but it’s much easier to give real-life examples than to construct new puzzles just for the sake of this post. Then again, imagine if this post was written entirely to seed content for an upcoming puzzlehunt. Boy would that be interesting! Seriously though, it’s not. You’re welcome to look, but you won’t find anything.
The One Minute Version
Puzzle solving can be divided into generating ideas for how a puzzle works, and executing well on those ideas.
To generate more ideas, solve more puzzles to see what’s shown up in past puzzles, and try similar things.
To execute better, practice by solving more puzzles.
Wait, This Seems Too Simple
Nah, that’s pretty much it.
The very common story is that if you want to get good at a skill, just do it a bunch. Like, go solve 100 puzzles. No, I don’t mean 10, or 20. Stop reading and go solve literally 100 puzzles. You will learn things. You will get better. It’ll just happen. It’s part of the magic of the human brain.
This is a very specific anecdote, but I play a platforming game called Dustforce. There’s one very hard level in the game which has a part called the Tera section. It’s almost exactly in the middle of the level, and is easily the most difficult part to clear.
I complained about this in the Discord and was told that yes, it’s awful, but was then directed to “100 Teras”, a custom map that’s just 100 copies of the Tera section with a checkpoint between each one. “If you’re really having trouble, go beat 100 Teras”. So I did, twice. And then I stopped complaining.
If you go solve 100 puzzles, you may not need this post. I’m still going to explain the solving strategies I’ve learned, but puzzle solving is really an activity where you learn by doing.
Okay, on to the real post.
Generating Ideas
Puzzles are often described as having “a-has” or break-ins, where it suddenly becomes clear what you should do. How do you come up with a-has? How do you break in?
This is genuinely the hardest part to give advice about. If it was easy to break in, we wouldn’t have puzzles in the first place! So I’ve decided to interpret the question differently: how do you create conditions that cause good ideas to arise? And how do you decide if those ideas are actually good?
Use spreadsheets
Collaboratively editable spreadsheets (typically Google Sheets) are the lingua fraca of puzzlehunting. Please use them.
Keep clean spreadsheets
We’re going to immediately start with a point of contention, because what “clean” means is never the same person-to-person, and people can be very opinionated on sheet hygiene.

The bare minimum that I think is unobjectionable is:
- Make a new sheet for each puzzle
- Put related information close to each other (answers next to clues)
- Use a monospace font
The first two are just common sense. As for monospace, a lot of puzzles will use word length as part of the structure. Human Pyramid from Teammate Hunt 2021 is a good example of this. Patterns in length (matching length, exactly one letter longer, etc.) are easier to notice if you put content in monospace, so using those fonts can help you break-in on those patterns faster.
(As an aside, Human Pyramid is displayed in monospace font specifically to encourage solvers to consider length. A similar trick is used in Pestered from MIT Mystery Hunt 2018.)
Personally, I like to put everything in monospace, but I know some solvers who prefer only putting clue answers in monospace and leaving clues in sans serif, since they value the visual boundary between clue and answer. Pick whichever works for you.
Transcribe puzzle content faithfully
Before you have broken into a puzzle, any part of the puzzle could be relevant information. The act of transcribing a puzzle from a website or PDF into a spreadsheet is slightly destructive. Text styling and spacing are often the first casualties. Usually this is fine, but every now and then the parts lost during transcription are important to breaking in.
So, try to make your sheet look as much like the puzzle as you can. Certain puzzles can make this hard (shoutouts to every puzzle with a triangular or hex grid). In those scenarios, do your best, but add a note to “see original puzzle” in the spreadsheet. And remember to look at the original puzzle if you’ve been stuck for a while, to see if there’s something about the presentation you missed.
Share your bad ideas
Puzzle solving is a collaborative activity, and people won’t know what ideas you have if you don’t share them. It’s okay to caveat that your idea is bad, but share it anyway. Try to follow the “yes, and…” rule-of-thumb from improv. Sometimes you will have 90% of the right idea and be missing the last 10%. Other times you will have the half-baked 10% of the right idea, and someone else will have the 90%. To get to 100% of the idea, one person needs to communicate, and you want to have a culture where both the 10% person and 90% person can be the one who communicates first.
Count things!
Off the top of my head, I do this a ton, I feel I do this more than most solvers, and I haven’t regretted it.
Puzzle solving often involves relating two parts of the puzzle together. These relations often follow whole number ratios. If there are N items in both parts, it suggests matching between those parts. If there’s N items in one and 2N in another, that could mean matching 1 item from the first part with 2 items from the second. If there’s 26 of something, it could mean A1-Z26.
A very simple example is Not Quite a Polka from Puzzles are Magic. There’s two sections of clues, and 13 clues in each section, so the puzzle is likely about solving both and combining the two.
Another example is Oxford Children’s Dictionary from MIT Mystery Hunt 2022. There are 19 clues in both the Standard Dictionary section and Oxford Children’s section, so we likely relate the two, and there are 38 words in the bottom grid to fit into 38 blanks in the clues, suggesting we fill each with a word.
A third example is Cryptic Command from GPH 2018. There are many steps to the puzzle, but we can start by noticing that for each card, the number of cryptics on that card matches the number of circles in the top right of that card. So we should probably relate each cryptic to a circle. (If we know enough about the Magic: the Gathering reference, this already provides some hint for what the cryptics will resolve to.)
Note that we can make all these guesses before doing any clue solving! During Mystery Hunt, it took us about 10 minutes to get our first clue in Oxford Children’s Dictionary, but we already correctly guessed all the mechanics of the puzzle before doing so.
Counts can also let you draw negative conclusions. If you have 7 clues in one part and 10 clues in the other, you are not going to do a 1:1 matching, so you can immediately discard trying a 1:1 match and think of doing something else.
I call this the numerology of the puzzle. At the start of a puzzle, quickly count the most salient parts of the puzzle, and keep any interesting correspondences in mind. When testsolving Light Show from Teammate Hunt 2021, we knew it corresponded to Tumbled Tower in some way, but weren’t sure on the rules for how it would work. So I decided to count every square in the Light Show grid. There were 133 of them, which was 7 * 19, matching the 19 heptominos in Tumbled Tower. We already suspected we’d use the heptominos in some way, but counting let us conclude that they should fit exactly with no overlaps or gaps.
Search everything
Honestly, a lot of puzzle solving is about taking random parts of the puzzle and throwing them into a search engine. Search the flavor text. Search just half of the flavor text. Add quotation marks to do exact phrase searches. Search all your answers together and see if something shows up. Randomly drop out words from all of the previous searches and try again. Experiment with more than one tool - anecdotally, I’ve found LLMs are amazing at pop culture ID, despite the hallucinations.
There are a lot of variables you can tweak in your search engine queries. The heuristic I use is that if there aren’t obvious starting points, I will search the puzzle title, the flavortext, all proper nouns, and any phrases that don’t read like typical English. I’ll also mix the theme of the puzzlehunt into search queries if I think it could turn up something new.
Ask if an idea’s overconstrained
Puzzles do not arise spontaneously. They are created by people to have a solution. As you come up with ideas on how a puzzle works, each of those ideas applies a constraint to the puzzle. For example, if we see a rows garden puzzle (see below), it’s a safe bet that answers for the blooms (the colored hexagons) are 6 letters long.
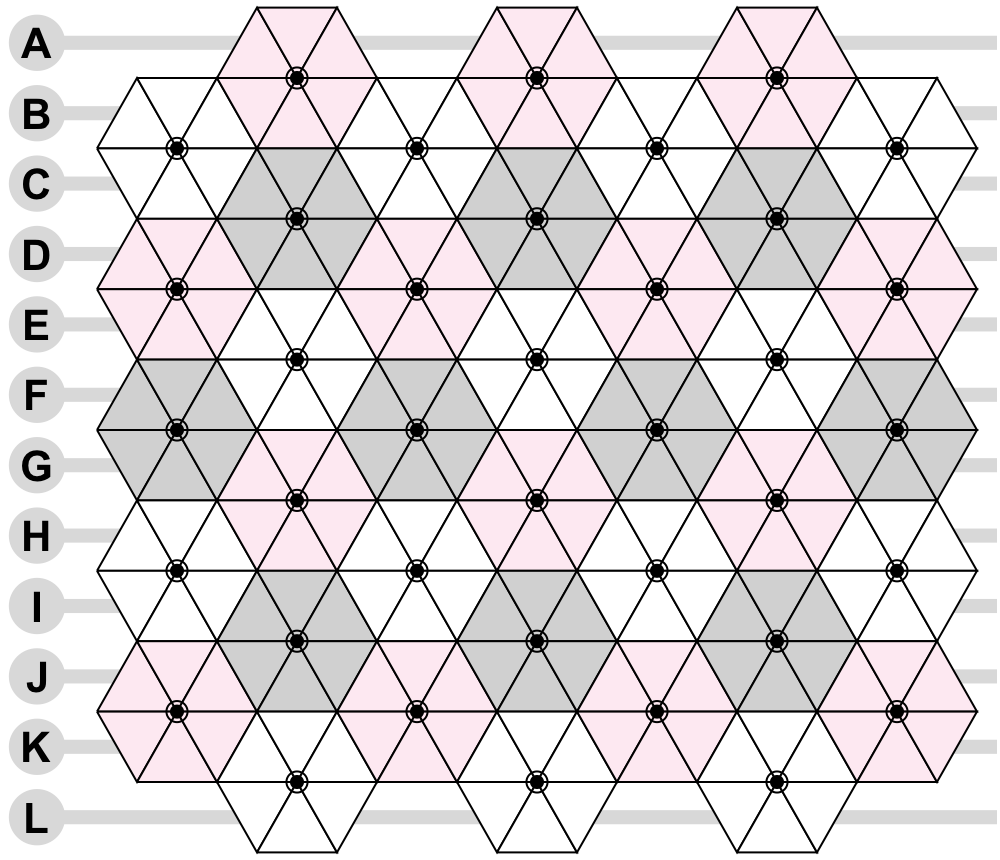
(This might not be the case if the puzzle is doing something funny for extraction, but let’s ignore that.)
We say an idea is overconstrained if it would be impossible or very difficult to construct a puzzle that worked that way. All answers being 6 letters is easy. All answers being 6 letter words for colors is harder, but maybe possible. If all answers had to be 6 letter words of colors that start with Y, that’s definitely overconstrained, because after YELLOW you really don’t have many options.
The logic goes like this:
- The puzzle is constructible, because I’m looking at it.
- If this overconstrained theory X is how the puzzle works, it would not be possible to construct this puzzle.
- Therefore, X can’t be how the puzzle works.
This can speed up your solves by letting you skip checking ideas that are implausible.
Now, sometimes this bites you badly, if you assume a construction is impossible when it isn’t. This happened to my team when solving Highway Patrol from the DaroCaro hunt. In this puzzle, you solve a Sudoku puzzle, and eventually get to the cluephrase MIDDLES. This suggests using the middle cells of each 3x3, and we failed to extract from this for a long time. It turned out the answer was to convert each middle number using A1-Z26. The reason our team got stuck here was that we all assumed that was impossible, as doing A1-Z26 on Sudoku digits forces your cluephrase to only use letters from A to I, and surely there’s no way you could do something with that, right? We kept trying to index things instead. Apply with caution - sometimes a constructor is just insane and figures out how to make a very constrained construction work.
Executing Faster
By this point, we have some idea of how the puzzle works, and are in the phase of answering clues and making deductions. Our goal is to get enough data to continue the puzzle. This section is about the mechanics of how to progress through clues quickly.
Look ahead to how the next step will work
In my opinion this is the major thing that separates experienced puzzlehunters from new ones. New puzzlers tend to solve puzzles in a waterfall style. When given a list of clues, they fully solve the clues, then start thinking about what to do with those answers. Whereas experienced puzzlers look ahead more, thinking about what to do next while solving the clues.
I don’t think new puzzlers are wrong to solve this way. It’s hard to look ahead if you don’t have the experience to know how puzzles tend to work. But in general, knowing what you’re aiming for can make it easier to solve the step you’re currently on, and will let you jump ahead faster. My rough heuristic is to consider how the puzzle will work at the start of the puzzle, then again at about the 50% mark. (Although, I will adjust depending on how much fun I’m having. If I’m not having fun I will definitely try to extract earlier to save myself from having to do more work.)
The reason it’s worth looking ahead is that knowing the next step often gives you extra constraints that can make clue solving easier, or even possible. It’s pretty common for a puzzle to have deliberately ambiguous clues, that only become unambiguous after you notice a common property shared by all answers. It’s a bit like backsolving a metapuzzle, but at a smaller scale.
Correctly looking ahead can sometimes let you skip large chunks of a puzzle, if you figure out extraction early enough to get the answer to show up in nutrimatic or Qat. One way to solve puzzles faster is to just do less work. I know some very strong solvers who can solve quickly while 100%ing puzzles, but it’s undeniably true that you don’t need to 100% puzzles to finish them. Personally, I only 100% a puzzle if I’m having a ton of fun, otherwise I’ll move on after we get the answer.
Look for pieces of confirmation
In sudoku puzzles, there’s this idea called “the deadly pattern”.
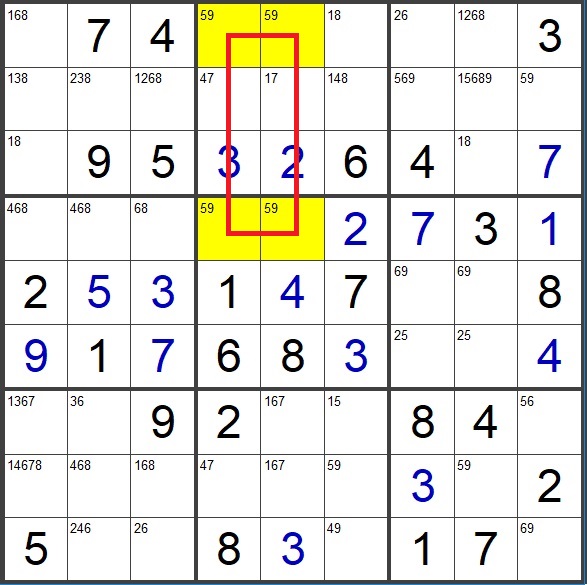
Consider the red rectangle above. The corners of the rectangle are 59-95 or 95-59. Both are valid solutions, no matter what gets placed in the rest of the grid, as switching between the two does not change the set of digits in any of the affected rows, columns, or 3x3 boxes. Since Sudoku puzzles are constructed to have a unique solution, if we ever see the deadly pattern, we know we’ve made a mistake and should backtrack. You usually do not need to assume uniqueness to solve a logic puzzle, but assuming uniqueness can give you a guardrail.
The same is true in puzzlehunting. Answers are often alphabetical as a confirmation step, and I will usually check alpha order very early (when ~20% of the clues have been solved), since knowing this early can speed up clue solving and let you catch mistakes as soon as they break alpha order.
To draw a transportation analogy, traffic lights and rules don’t exist to slow you down, they exist to speed you up by letting you drive through intersections without having to negotiate right of way. Guardrails are there to make your solve more streamlined - search them out and use them!
Do the easy parts first
When I see a crossword puzzle, I like to solve the proper nouns first. With a search engine, these are usually both easy and unambiguous. Clue difficulty is not uniform, and sometimes constructors will deliberately create an easy clue to provide a foothold for the puzzle. It’s usually worth doing a quick once-over of a puzzle to see if anything stands out. If I get stuck on a clue, I will immediately jump to the next one and only revisit the trickier clue if needed, rather than forcing myself to do it.
Prioritize important clues
If you see an extraction like
?N?WE???????, many solvers I know will assume the first 6 letters are going to spellANSWERand will stop extracting any of the first 6 letters unless they get stuck.This is a special case of trying to direct work towards the “high information” areas. Some general wheel-of-fortune skills are helpful here: if I see an extraction like
?????I?G, I’ll usually assume it’s going to end-ingand skip solving the clue for the blank between theIandG.When combined with word search tools like Qat or nutrimatic, this can be ridiculously strong. In general, word search tools have trouble with long runs of blanks, but are very good at filling short gaps. If I know ordering, I’ll often jump around to solving clues that reduce runs of blanks, rather than going in order. Or, I’ll declare that I’m working from the bottom when solving with a group, because most people start from the top and it’s better to distribute work throughout a cluephrase.
Importantly, you can’t tell what to prioritize if you haven’t tried extracting yet, which is why I value looking ahead on extraction so highly.
At the hunt-wide level, this also means trying to push solves in rounds where you think it’ll be important to get more solves, either to unlock the meta or get more data for a meta.
Automate or find tools for common operations
Solve logic puzzles with Noq. Use browser extensions that make it easy to take screenshots and search images by right click (there are a few of them, I use Search by Image). Wordplays is a solid crossword clue searcher, and npinsker’s Crossword Parser is a good crossword grid sheet creator (albeit one you need to supervise, the image detection isn’t perfect). There are too many tools to list all of them, but the one on puzzlehunt.net is pretty good.
One I would highlight is spreadsheet formulas. I spent a very long period of my puzzling career not using formulas. Eventually I decided to learn spreadsheet formulas and now I can’t go back.
Spreadsheet formulas have several advantages:
- They’re consistent. You can’t miscount or typo a letter. (You can typo a spreadsheet formula, but usually spreadsheet formula typos lead to errors rather than incorrect letters.)
- They’re automatic. Once you have extraction driven by spreadsheet formula, you can stay in a flow of IDing and solving without detouring into extracting, reducing time lost to context switching.
- Due to being automatic, you can see exactly how much partial progress you’ve made on extraction, which makes it easier to prioritize clues and check if an extraction looks promising.
Also, being good at spreadsheet formulas is by far the most transferable skill to real life. The business world runs on Excel. The very basic actions you’ll do over and over in puzzlehunts:
=MID(A1, k, 1)takes the k-th letter of A1.=REGEXREPLACE(A1, "[^A-Za-z]", "")removes all non A-Z characters from A1.- If you only want to ignore spaces to worry about,
=REGEXREPLACE(A1, " ", "")or=SUBSTITUTE(A1, " ", "")may be easier to remember. You usually do not need the full power of regular expressions.
- If you only want to ignore spaces to worry about,
=LEN(A1)gives the length of the word in A1.=CHAR(A1 + 64)will convert 1 to 26 into A to Z.- If you can’t remember 64, you can do
=CHAR(A1 - 1 + CODE('A'))instead.
- If you can’t remember 64, you can do
=CODE(A1) - 64will convert A to Z into 1 to 26.=UPPER(A1)will put the contents in uppercase.
It’s also worth understanding relative references vs absolute references. Consider this example I just made up.
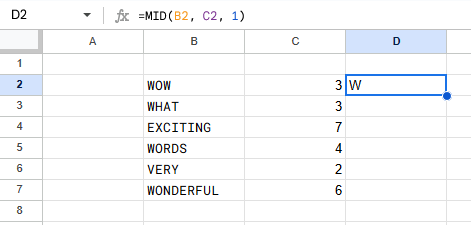
The
=MID(B2, C2, 1)in cell D2 here is a relative reference. Although the cell displays=MID(B2, C2, 1), what is actually stored internally is=MID(2 cells left, 1 cell left, 1). Dragging a formula will copy-paste that relative offset to each cell, which is usually exactly what we want.In some cases, you will want to refer to a fixed position. This is called an absolute reference, and you can do so by prepending $ to the column, row, or both.
$B2is an absolute ref to column B and a relative ref to row 2, whereasB$2is a relative ref to column B and an absolute ref to row 2.Examples:
Indexing multiple columns of indices:
=MID($A1, B1, 1)locks the word to always be from column A, while letting the word change per row.Indexing a single word many times:
=MID($A$1, B1, 1)locks the indexed word to be a specific cell.As I’ve become more fluent in spreadsheets, I’ve started using them in more complex ways. For example, if the clues for a puzzle include enumeration, I’ll quickly add
=LEN(REGEXREPLACE(A1, "[^A-Za-z]", ""))next to each answer column, to make it easier to verify our words are matching the given lengths. If you find you use a formula often, you can use named functions to save them and import them elsewhere. (Although I confess I always forget to set this up before a hunt, so I don’t use them very often.)The spreadsheet rabbit hole goes very deep. I recommend You Suck at Excel by Joel Spolsky as a classic spreadsheet introduction. (You Suck at Excel recently disappeared off YouTube - the link above is a bilibili mirror.) For more puzzlehunt-focused guides, see Yet Another Puzzlehunt Spreadsheet Tutorial by betaveros and Google Sheets Puzzle Tricks by Jonah Ostroff.
Use code for more complicated extractions or searches
(If you can’t program, ignore this.)
Sometimes, you hit the limits of what public tools can do. In these scenarios, it can be pretty helpful to write code trying more complex extractions or searches. I recommend downloading a wordlist (Scrabble dictionary is a good target), and writing some basic functions for A1-Z26, morse, and so on. Any time you write one-off code, check if you think it’ll be useful for a future hunt, and save it somewhere. A good starting place is solvertools for generic operations and grilops for logic puzzles.
The power of having basic encodings implemented in code is that it makes it possible to write brute force searches. Once, I was solving a metapuzzle from a now-offline hunt. Based on flavor, we were very confident it was going to be about Morse code, each of our feeder answers would convert to a dot or dash, and we’d read out a message. We couldn’t figure out how to do the conversion, but the round only had 7 puzzles, so I decided to write a script to brute force the Morse for all \(2^7 = 128\) possibilities. This worked. I did something similar for the Silph Puzzle Hunt metameta. We solved the first and last group, but couldn’t figure out the answer to the (4 7) group in the middle. Doing a word search in my phrase list, I found there were around 2500 reasonable phrases of enumeration (4 7) in it, so out of despair I decided to brute force a list of all possible extractions and scrolled through it until I noticed something that looked like the answer.
One advantage of code is that if it exhaustively checks all possibilities, and it still fails to extract the puzzle, then you know you should try something different from the extraction you attempted, assuming you trust your code and the inputs you’re giving it. (Once again, this has burned me before, when I concluded an extraction method was wrong because the answer didn’t appear in my local wordlist. Proceed with caution!)
When picking what to work on, check what’s underinvested
Most people solve puzzlehunts in a team, and it’s usually not good for everyone on the team to pile onto one puzzle. Instead it’s better for people to spread out. When looking for a puzzle to work on, it can be helpful to check which ones have enough people to push it to the finish without you, and which ones need assistance.
In general, puzzles with big lists of clues (e.g. crosswords) can absorb lots of people, and puzzles with many serial a-has (e.g. logic puzzles) see diminishing returns. It’s not always clear if a puzzle is more serial or parallel. One quick hack is to just ask the people working on the puzzle if they want help or think they have it under control.
In especially big hunts (i.e. Mystery Hunt), you can also strategize at the round level, picking rounds based on how many people are working in that round and how many solves they’ve gotten so far.
Getting Unstuck
Everyone gets stuck on puzzles. The question is what to do about it.
Check your work
I have seen so, so many times where a puzzle was stuck because of a silly mistake. Check your work. Cannot overstate this enough. I know one friend who’s joked that their puzzle solving tips guide would just be “check your work” repeated 50 times.
Do a different puzzle
There’s no shame in abandoning a puzzle for now and coming back to it later. It’s very easy to tunnel vision too hard on a problem.
However, there is a certain art to this. Puzzles are normally done in teams. If you abandon a puzzle, it’s good to make a clean copy of your sheet first. Keep your scratch work as is, but in the clean copy, organize your work and explain what you’ve found. Importantly, remove all the speculative half-baked ideas you had. Given that you’re stuck on the puzzle, it’s more likely your half-baked ideas are wrong, and you should avoid biasing future solvers into the same rabbit hole.
Look for unused information
Most puzzles will try to use all channels of information they can, and will not have extraneous info. That doesn’t mean every puzzle will use 100% of its info, but extra info is the first place to look. Try listing everything that has and hasn’t been used yet.
Look for missing information
To me, this is slightly distinct from unused information. Unused information is when you know there are aspects of the puzzle dataset you haven’t used yet. Missing information is when the information you need doesn’t even exist in your spreadsheet, and needs an a-ha to figure out.
The longer a spreadsheet stays unextracted, the more likely it is that the spreadsheet is fundamentally missing the information needed to extract. I’m a big fan of qhex’s extraction basher, which will try a wide battery of indexing and ordering mechanisms. It doesn’t actually work that often in my experience, but when I see it fail, it does encourage me to consider if there’s a way to derive another column of data we could be extracting from.
Assume a few errors
To err is human. If you don’t like a few letters, you can always pretend those were solved wrong and switch them to wildcards in nutrimatic. I’ve also been pointed to util.in, which I haven’t used before but supports “probably correct” letters.
It’s important not to overdo this, but getting good at error correction can really take you quite far. This extends to other forms of errors as well. For example, sometimes I’ll assume our indices were derived incorrectly, and try Caesar shifting in case they’re all off by one.
Cheese
A game designer painstakingly carves a beautiful sculpture out of wood, first chiselling it out of a raw block, and then gradually rounding off any rough edges, making sure it works when it’s viewed from any angle.
The speedrunner takes that sculpture and they look it over carefully, from top to bottom, from every angle, and deeply understand it. They appreciate all the work that went into the design, all the strengths or the weak points, and then, having understood it perfectly, they break it over their knee.
Getting Over it Developer Reacts to 1 Minute 24 Second Speedrun
For the uninitiated, cheesing a puzzle means to solve it through an unintended path. It comes from video game slang, and usually implies solving with less work than intended.
Cheesing can be a little controversial…it’s a bit subversive, and as tools for cheesing have gotten stronger, puzzle design has had to adapt in ways that sometimes makes a puzzle worse. Hardening a puzzle against nutrimatic sometimes makes it less friendly to new solvers who don’t know how to exploit nutrimatic.
I view cheesing the same as backsolving - it’s a ton of fun if it works, but it wouldn’t be nearly so fun if it worked all the time.
Here are common cheese tactics:
- If you don’t know how to order, you can try random anagramming.
-
If you have an ordered list of words, but don’t know the indices, you can construct a regular expression to take one letter from each word and see what possibilities show up in nutrimatic. For example, this works on the list of words in the spreadsheet video earlier up.

Another puzzle where I remember it working was Hackin’ the Beanstalk from MIT Mystery Hunt 2020.
-
If you have an ordered list of indices, know what words you’re indexing, but don’t know how they match up, you can also construct a regex. If the index is (3), and we know the word we’d index is one of CAT, DOG, or HORSE, then we know that letter can only be
[tgr]. This was how our team solved the Flexibility meta from Shardhunt. We understood the last section was forming a path going back and forth between six 6-letter words, indexing the face seen at each step of the path, but we couldn’t figure out the interpretation. So we tried a cheese in hopes we could skip that step, and it worked. (Albeit with having to look at page 2 of nutrimatic results.)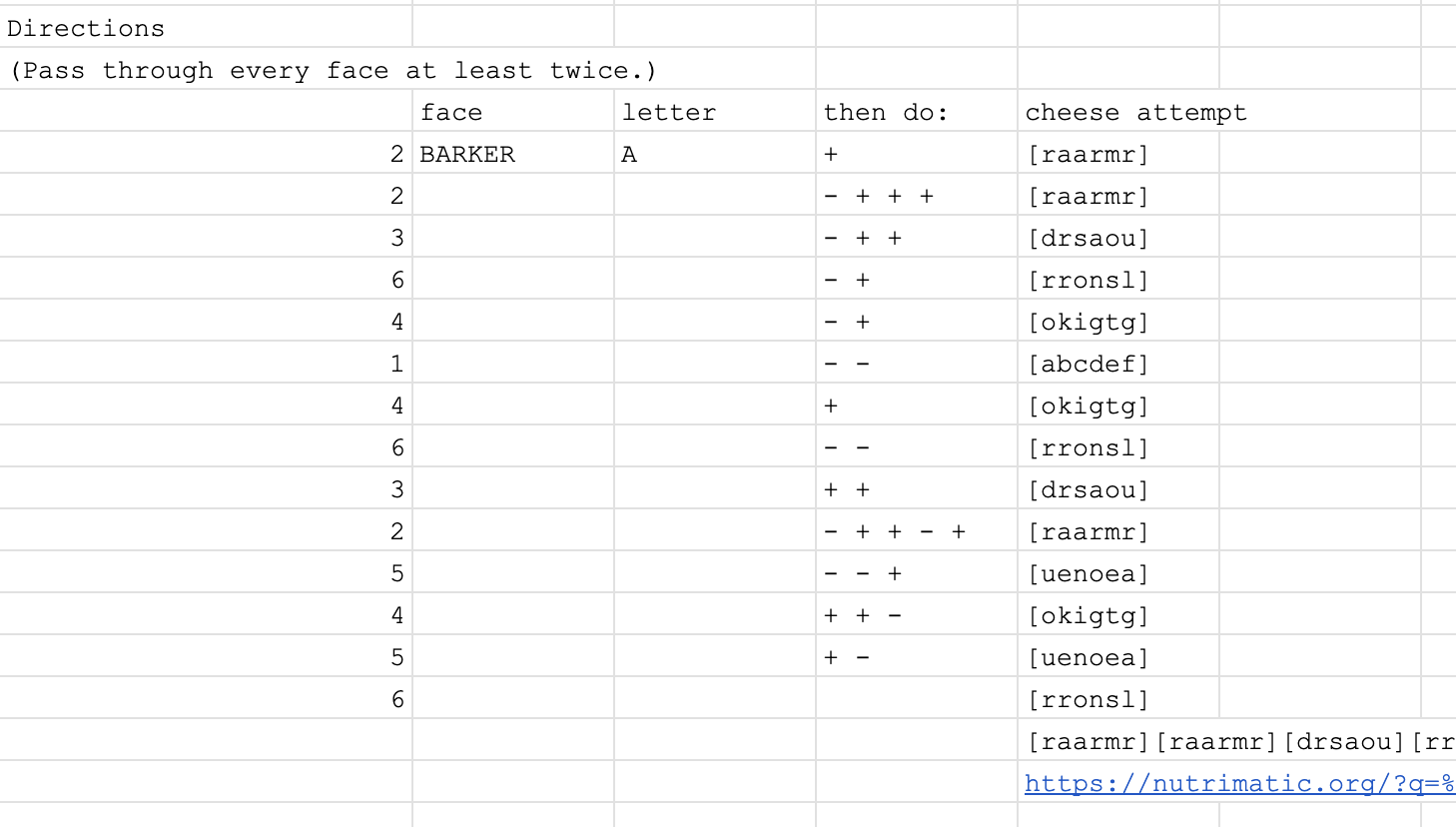
In testsolving, I solved Mouth Mash from Teammate Hunt 2020 this way as well, and the puzzle was redesigned to make this cheese less effective.
- If enumerations are given for a multi-word phrase, and the phrase is long enough, sometimes the enumeration itself is enough to constrain the phrase. You can use OneLook or nutrimatic to check for this. For example, (2 2 2 3 2 2 4 2 3 8) only has one notable match. This cheese is usually better done in OneLook, since the phrases in its dictionary are all only “real” phrases that could be puzzle answers.
To draw an analogy to engineering solutions to high school math contest problems, cheesing is not a replacement to learning how to solve puzzles, but it can be very effective. If you cheese a puzzle, you should go read how it was supposed to work after solutions are released, or try to reverse engineer the extraction from the puzzle answer.
You should also make sure other solvers are okay with you cheesing a puzzle before trying to do so. Cheesing is a way to skip ahead of the struggle, but sometimes people in the struggle are having lots of fun.
Get in the constructor’s mindset
If you get really stuck, it can help to ask why a puzzle was constructed the way it is. Why was this information provided to you? Why is this clue phrased the way it is?
A very recent top-of-mind example is Goodreads from Brown Puzzlehunt 2024. There is a point in the puzzle where you extract a bunch of numeric library classifications (i.e. Language = 400 in Dewey Decimal). We were confused on whether to extract using “Language” or “400”. One clue comes with a note saying “in base 63”, so the eventual argument made was:
Saying “base 63” is so random. This has to only exist because they couldn’t make extraction work with standard library classes. So we should leave the class as the number, since there’s no great way to interpret base 63 otherwise.
In general, weird, strange, or obscure clues tend to indicate that there’s a very specific reason that clue had to be weird, strange, or obscure, and you should consider what that reason is. For example, I once wrote a puzzle where I needed to clue EOGANACHTA, which was a travesty, but it was the most reasonable option that fit the letter constraints I needed. A sharp-eyed solver that got that clue should be immediately suspicious that future extraction will be based on the letters used rather than its meaning.
To give a non-puzzle example, in the board game Codenames, you are trying to clue words for your team and not the opposing team. If I get a clue like “TOMATO: 2”, and see RED and FRUIT on the board, I’ll mention RED and FRUIT fits, but I’ll also start wondering why we got “TOMATO” as a clue instead of a more typical red fruit like APPLE, CHERRY, or STRAWBERRY. Perhaps a word like PIE is on the board, and they were trying to avoid it.
How much getting into the constructor’s mindset helps you will depend on how well you understand typical puzzle design. This is one reason people who write puzzles tend to get better at solving them. Like, maybe the reason ✈✈✈Galactic Trendsetters✈✈✈ is so strong is because parts of their team have been writing hunts every year for 7 years.
Backsolving
Let’s say we’ve solved a meta, or understand the constraints it will place on our answers, and want to backsolve a puzzle. How do we do so?
Verify it’s possible
Very often, the way a meta uses its answer will lead to it not backsolving very easily. If it only uses 1 letter from the feeder answer, you basically have no hope and should just move on.
Read through the progress on each unsolved puzzle
In my experience, it is actually pretty rare that you can backsolve a puzzle entirely from the meta constraints. The more common strategy is that forward solving the puzzle gives some information about the answer, the meta provides other information, and only the combination of both is enough to constrain the backsolve. In the Department Store Puzzlehunt from Puzzlehunt CMU, we only backsolved Karkar’s Very Fun Crossword because we had forward solved enough to know we’d like the answer to be a compound word. In MIT Mystery Hunt 2019, teammate backsolved 2 puzzles from Thanksgiving Town/President’s Day Town by noticing the themes of those puzzles matched incredibly well with some candidate answers.
Before attempting a backsolve, read through each puzzle to refresh yourself on the theme of the puzzle, or see if there’s any hints about the length of that puzzle’s answer, like the number of clues or given blanks. If you don’t know the length of the answer, one trick in nutrimatic is that it supports
&for “match both sides”, andA{a,b}will match exactly \(a\) to \(b\) letters (i.e.A{3,6}= 3 to 6 letters). So you can do searches likeAAAxA*&A{7,10}, which means “an answer whose 4th letter is X and is 7 to 10 letters long”. This comes up in forward solving, but is more useful in backsolving.Bringing This Together
To showcase these strategies together, here is a puzzle I remember speedrunning especially quickly: The Three Little Pigs from Hunt 20 2.1 Puzzle Hunt. This hunt was designed to be on the easier side, so this made it more susceptible to speedrunning. I’ve reproduced the puzzle content below.
The Three Little Pigs
It's all about 3
This puzzle uses cryptic clues. If you are new to cryptic clues, a guide such as this may help.
Nice hug in deity (4)
Break small round pan (4)
Shatter quick for pancakes? (9)
Head of public relations takes primate document (5)
Little matter from master weight (6)
Among a hubbub blessing, spheres (7)
Plain vehicle turns everything and one (7)
Southern team leader's uncooked fodder (5)
Cease the odd sets of pi (4)Bachelor's around Astley blocks (6)
Cisgender in Social Security, or small tools (8)
Diamond inside a meal (6)
Flower mob coming back around failure (7)
Particle misuses one turn (7)
Soda bubble result (3)
Sweet delayed after cold homecoming (9)
Turn an official list of bread (4)
Unpleasant drug lyrics within (4)Here’s how my team did that hunt, as reconstructed from Google Sheets history, and annotated with the strategies mentioned earlier.
There are 9 clues in each half (counting).
The puzzle is very strongly hinting 3, so my guess is that either we will form 3 groups of 3 from each column, or we’ll pair the columns and use 3 some other way (looking ahead).
Clues in the right column are ordered alphabetically, clues in the left column are not (looking for confirmation). That suggests ordering by the left column. If only one column is ordered, that also suggests pairing between columns, because (constructor mindset) it wouldn’t make sense to change the ordering between columns if each column was used identically.
Since it seems likely we’ll do pairing, let’s solve a few from both columns, since having progress on both will make it easier to find a pair (prioritize important clues).
Nice hug in deity (4)
Break small round pan (4) = SNAP
Shatter quick for pancakes? (9)
Head of public relations takes primate document (5)
Little matter from master weight (6)
Among a hubbub blessing, spheres (7)
Plain vehicle turns everything and one (7)
Southern team leader's uncooked fodder (5)
Cease the odd sets of pi (4) = STOPBachelor's around Astley blocks (6)
Cisgender in Social Security, or small tools (8)
Diamond inside a meal (6)
Flower mob coming back around failure (7)
Particle misuses one turn (7)
Soda bubble result (3) = POP
Sweet delayed after cold homecoming (9)
Turn an official list of bread (4)
Unpleasant drug lyrics within (4)Hey, SNAP and POP could form a group with CRACKLE. Perhaps this is how we use 3 - we get clues for two parts of a set of 3. STOP could be the start of STOP DROP ROLL, so let’s see if we can find DROP or ROLL in the right column, and otherwise focus on solving the left column since that provides ordering (prioritize important clues).
Nice hug in deity (4)
Break small round pan (4) = SNAP
Shatter quick for pancakes? (9) = BREAKFAST
Head of public relations takes primate document (5)
Little matter from master weight (6)
Among a hubbub blessing, spheres (7)
Plain vehicle turns everything and one (7)
Southern team leader's uncooked fodder (5)
Cease the odd sets of pi (4) = STOPBachelor's around Astley blocks (6) = BRICKS
Cisgender in Social Security, or small tools (8)
Diamond inside a meal (6)
Flower mob coming back around failure (7)
Particle misuses one turn (7)
Soda bubble result (3) = POP
Sweet delayed after cold homecoming (9)
Turn an official list of bread (4) = ROLL?
Unpleasant drug lyrics within (4)With BREAKFAST on the left, we should try to find LUNCH or DINNER, and with BRICKS on the right, we should try to find STRAW or STICKS. At this point, we can provisionally pair those target words to cryptics by just looking for a definition that matches (cheese). In the real solve, we did do the wordplay, but only after we knew what word we wanted it to resolve to.
Nice hug in deity (4)
Break small round pan (4) = SNAP
Shatter quick for pancakes? (9) = BREAKFAST
Head of public relations takes primate document (5)
Little matter from master weight (6)
Among a hubbub blessing, spheres (7)
Plain vehicle turns everything and one (7)
Southern team leader's uncooked fodder (5) = STRAW
Cease the odd sets of pi (4) = STOPBachelor's around Astley blocks (6) = BRICKS
Cisgender in Social Security, or small tools (8)
Diamond inside a meal (6) = DINNER?
Flower mob coming back around failure (7)
Particle misuses one turn (7)
Soda bubble result (3) = POP
Sweet delayed after cold homecoming (9)
Turn an official list of bread (4) = ROLL?
Unpleasant drug lyrics within (4)Let’s try extracting from the missing words for each group of 3 (looking ahead). So far, we have:
??? CRACKLE LUNCH ??? ??? ??? ??? STICKS DROPHaving 4/9 is enough to try nutrimatic. First instinct is to read first letters, but ending in SD seems bad. If I were making this puzzle (constructor mindset), I’d want to put the theme of 3 everywhere, so let’s try indexing the 3rd letter.
This gives
.an....io, and if we scroll down the list of nutrimatic results a bit, we seeDANCE TRIO, which was the answer.During the hunt, some teams solved this puzzle in 5 minutes. My team was not that fast (13 minutes), but you can see how applying a few tricks let us focus directly on the solve path and reduced unnecessary effort. This solve was a very extreme case, and the tricks I’ve described are usually not this effective, but try them out sometime. I expect them to be of use.
Thanks to Eugene C., Evan Chen, Nicholai Dimov, Jacqui Fashimpaur, Cameron Montag, Nishant Pappireddi, Olga Vinogradova, and Patrick Xia for giving feedback on earlier drafts of this post.