Posts
-
Which Tech CEOs Are Gamers?
CommentsIn a court of law, Satya Nadella said he is not a gamer.
This came out of the Musk vs Altman case about OpenAI. Part of the questioning included the lawyers wanting to lay out context about OpenAI’s DotA 2 efforts. So, they asked Satya Nadella what he understood about DotA 2. To which he said:
“I’m not a gamer,” says Nadella. “And I think it’s a Steam game, if I’m not mistaken.”
I will give props that Satya knows what DotA 2 is and what Steam is, but you heard the man. Satya Nadella is not a gamer. In the face of potential perjury, he admitted it.
There has always been a healthy overlap between tech workers and gamers. Reading Satya testifying about his gamer cred was ridiculous enough to inspire a dumb idea: which tech CEOs are gamers? How does Satya measure up against his peers?
As a gaming project, it seems most appropriate to organize CEOs into a tier list. I will be rating them among four tiers:
- Gamer
- Gamer but Cringe
- Casual Gamer
- Not a Gamer
You’ll see why we need the second category.

Sam Altman, Elon Musk
Let’s start with the other people in the lawsuit. Sam is the former president of Y Combinator and current CEO of OpenAI. Elon is…you know who Elon is.
To put things mildly, these two are no longer on good terms. (See: the lawsuit.) However, in the past they were friendlier. In the Before Times, Y Combinator actually uploaded a clip of the two discussing video games. This was back when YC was trying to appeal to software engineers, rather than Republican masculinity.
If you don’t want to watch,
- Sam and Elon both say they’ve played Overwatch and liked it.
- Elon says he’s played Hearthstone, which Sam hasn’t.
- Elon asks if Sam’s played the new Deus Ex. Based on the timing, this should be Deus Ex: Mankind Divided. Elon says it’s kind of mid, compared to the original Deus Ex.
- Sam says he’s played it a bit, but his favorite recent game is The Last of Us.
The video then turns to a discussion about how older games with weaker graphics had to rely on storytelling to fill the gaps. I’d rate this somewhat true - storytelling has gotten significantly easier with graphics if you care about it. Then Sam comes in saying old Mario games had incredible stories, which I find very weird. When you think of a good story-based game, Mario is far, far down the list. (Although the Mario RPG stories are often good.)
I would have rated both of them as gamers, but Elon’s relationship to videogames is more mixed these days. Shortly after Path of Exile 2 launched, Elon tweeted that he’d made it to rank 59 worldwide. He then livestreamed himself playing PoE 2, and made, shall we say, many suspicious plays that indicated he knew much less than he should have. The list of irregularities is documented well on Reddit. He later acknowledged that he had paid for an account booster to play the game for him, but this is fine because every high ranked player does it. This is, uh, not true? I can’t begin to get into this, I just can’t.
Sam makes it to the Gamer tier, but out of self-respect I must put Elon in the Gamer but Cringe tier.
Larry Page, Sergey Brin
Larry and Sergey are the co-founders of Google. I did not find any mention of either playing video games. There is one NYT article that mentions Elon Musk used to crash at Larry Page’s place after playing video games, but it never says if Page played video games, so I will play it safe and say neither are gamers.
Sundar Pichai
Sundar is the current CEO of Google. Although there is little reporting on the video games Sundar has played, he has mentioned some. Games Developer Conference (GDC) is a yearly conference for the video games industry. At GDC 2019, Sundar took the stage to announce Google Stadia, an upcoming platform where you could stream video games over the cloud.
He started his talk by saying he wasn’t a big gamer, but he did play two games: FIFA 19, and Ashes Cricket. “If you don’t know what cricket is, it’s kind of like baseball, but better.”
To quote the YouTube comments, saying you aren’t a big gamer before debuting a product targeting gamers was certainly a choice. There’s nothing wrong with playing sports games, but there’s certainly some stigma against people who only play those games. Sundar is an archetypal Casual Gamer.
Google Stadia would be shut down a few years later.
Steve Jobs
Steve Jobs is the former CEO of Apple. The main video game related story Steve is tied to is the Atari Breakout debacle, which you probably already know. I’ll repeat it anyways.
Before starting Apple, Steve Jobs was a computer technician at Atari. He was assigned to create a circuit board for the game Breakout in as few chips as possible to reduce cost. Atari offered a bonus of $100 per chip saved. Steve Jobs took the problem to his friend Steve Wozniak, who managed to fit Breakout into many, many fewer chips than anyone at Atari expected. Accordingly, they paid Steve Jobs $5,000. Jobs then lied to Steve Wozniak, saying the bonus was $750, and paid Wozniak $375 while keeping the rest. Wozniak did not learn about the lie until 10 years later. Despite technically being a game developer on Breakout, Steve Jobs is not a gamer.
The Jobs and Wozniak story has long been a part of Silicon Valley folklore. It’s easy to see why, it’s got everything: deception, salesman taking credit for the work of engineers, and the quiet realization that the salesman is the reason anyone cares. I expect the OpenAI board drama of 2023 to become equally folklorish, assuming we live that long.
Tim Cook
Tim Cook is the current CEO of Apple, although he will step down in September of this year.
I don’t think Tim Cook is much of a gamer. In 2017, he did a whistle-stop tour around Europe, and during that trip he visited ustwo, a software consulting studio that entered mobile gaming in 2011. Their breakout hit was Monument Valley, an iOS puzzle game based on manipulating optical illusions. It’s since sold over 26 million copies.
When interviewed by The Independent, Tim had this to say.
Are you a fan of ustwo and Monument Valley?
I love what they’re doing. It’s unique. Most games are shoot-em-up or that kind of stuff. This one feels like there’s more of a core purpose kind of game. I was thinking about the arc of the story, it feels like a Disney story. It has that kind of a pull on the heart string. It clearly appeals to a non-gamer.
One imagines Tim counted himself among that group.

Jeff Bezos
Jeff Bezos is the former CEO of Amazon. There’s little direct mention of him playing any games, but during his tenure, he started an Amazon Games Studio and acquired the livestreaming site Twitch. In a call with CNBC, Kevin Lin (co-founder of Twitch) said that Jeff Bezos played some games, but he wouldn’t call him a gamer. Without any specific citations I’m not willing to count this. He has also historically invested in Second Life and the flash games portal Kongregate, according to a 2008 market intelligence article by Parks Associates. I disagree with the article’s claim that investing in gaming makes you a gamer at heart. That’s like saying Pokemon card scalpers are Pokemon fans at heart. There’s overlap, but they don’t imply each other.

The story is similar with Andy Jassy, the current CEO of Amazon. He posts in support of Amazon’s gaming efforts but there is little reporting of him playing any games.
Demis Hassabis
Demis’s life story is tied to games in many ways, although it initially started with chess rather than video games. He reached a master Elo rating of 2300 as a teenager, then worked at Bullfrog Productions (a game studio) at 16 when taking a gap year before university. You can find an interview with Demis about it in Retro Gamer Magazine.
After graduating, he went back to the games industry, working with Peter Molyneux (designer of the Fable series), before leaving to start his own games company, Elixir Studios. They released Evil Genius, a base management game where you play a supervillain that needs to stop hero spies from stopping your evil plans. This sold well but not amazingly, and following Elixir’s closure, Demis went to grad school, which eventually led to founding DeepMind.
I haven’t been able to find any discussion of recent video games played by Demis, but when asked to name his favorite games on Lex Fridman’s podcast, he names Civilization I and II.
You don’t go into the games industry unless you like video games. It’s an infamously bad industry to work in, because like many entertainment industries, enough people want to work there that you get underpaid and overworked. I feel comfortable saying Demis is a gamer.

Mark Zuckerberg
In 2015, during a town hall, Mark Zuckerberg was asked what his favorite video game as a kid was. He answered Civilization. So there’s one thing Demis and Mark could bond over (although I suspect neither would be interested in doing so).
I cannot express this enough: Mark Zuckerberg really likes Civilization. Like many CEOs, Mark’s profile page on Facebook is a mix of press releases and carefully cultivated relatable content. For Mark, much of the relatable content is about Civ.
When Civ VI launched in 2016, he said he would be playing it non-stop that weekend until he beat it on Deity, the highest difficulty. In 2017, he did a trip around the United States to visit every state, which was interpreted as either an attempt to distract from Cambridge Analytica or a tee-up for running for political office. Neither came to pass, but in his Rhode Island stop, the US Naval War College said he might enjoy their war games because they were like Civilization. In 2021, he shared a photo of his daughter playing Civilization, calling it a “proud dad moment”. And in 2025, he reshared his Civ VI post to announce he was excited that Civ VII was coming to Meta Quest. The man is a Civilization diehard.
His passion is unfortunately overshadowed by him saying in 2024 that he’d be surprised if anyone in the world could beat him at Civilization. He said this shortly after Elon had made a fool of himself over video games, which did not help his case. The Civ community roasted him, saying several Civilization content creators were likely better.
I don’t doubt Mark is good at Civilization, far better than the average player, but it’s also very obvious to me that you can’t have the time to be the best while also running Meta too.
Despite this overbrag, I was willing to give some grace and place Mark in the Gamer tier, until I learned the board games story.
Careless People by Sarah Wynn-Williams is a memoir about the author’s time at Facebook. The book was heavily Streisanded when Meta filed a disparagement lawsuit against her, trying to disrupt its publication. After reading many reviews of the book and discussions of the lawsuit, my read is that Sarah’s account tends to downplay her role in events, and include some light embellishment, but the broad strokes of the stories are true. Which makes the Settlers of Catan story extra wild.
Sarah claims that at a company retreat, she participated in a six player game of Settlers of Catan. As the game continues, she believes the other players are deliberately throwing to make sure Mark Zuckerberg wins.
Everyone’s really into it despite the blatant nerdiness of it all, building their little empires and strategically negotiating. But as the night wears on, it becomes more and more obvious that people are letting Mark win.
Initially, it’s just small things, people not building near his settlements or going soft when they negotiate with him. As the game continues, things become more explicit, with people “stealing” from everyone but him and never placing the “robber” on Mark’s empires. After a particularly egregious move by Dex in which he uses the robber to block Debbie, who’s closest to catching Mark on victory points, I cry out.
“You’re letting him win, Dex and Derick. You’re enabling it.”
I know it’s nerdy and I’m ashamed of myself for caring, but I can’t choke it down anymore. Everyone looks suitably shocked by the accusation. Dex and Debbie flash me looks of “don’t say this in front of Mark.”
“What do you mean?” Dex asks brazenly.
“You know exactly what I mean. You could have placed the robber anywhere but you never place it on any of Mark’s hexes. You always place it on his closest competitor.”
“That’s ridiculous,” Dex says.
“It’s random,” Derick chimes in, offering support.
“No, it’s the parts that aren’t random that you’re swinging his way, the negotiations where you’re saying no to everyone else and then yes whenever he needs a resource, the robber, anything.”
If you have never played Settlers of Catan, first off - good. There are many board games better than Settlers of Catan. But I’ll confirm that what was described could happen, and would be enough to make Mark a lot more likely to win. At one point, the #1 online Catan player was shown to be cheating by using a sockpuppet account to always offer themselves good trades. Having actual puppets works too!
These events were contested by Dex, the one accused of throwing the game. He said Mark did win the game, but he wasn’t trying to throw for Mark.
There’s a story about when I was playing Mark Zuckerberg at Catan. Sarah suggests I was deliberately letting Zuckerberg win the game, and “brazenly” dismissing her strategic guidance. It’s a lovely anecdote that positions our heroic narrator as some sort of principled mind surrounded by a sea of yes men or something, and that we all liked to let Zuckerberg win.
Yeah, except that’s not what happened at all.
I chose to eliminate the weaker players so I could then go after Zuckerberg, who was the toughest player. The game then ended with something more interesting: Zuckerberg said he was tired and wanted to sleep, and convinced the others to gang up on me so he could win! That’s actually a much better story showing his ruthlessness. For years I’ve been telling people Zuckerberg cheated. Except it wouldn’t provide a clunky means for Sarah to focus the narrative on her apparent crisis of conscience.
This was posted to where else but Threads. I find this statement very confusing. Catan is really not the kind of game where you can “eliminate the weaker players”. It is a Eurogame with no direct player elimination where all players’ economies grow over time. You can indirectly fight when racing to the good locations, but it is almost always better to focus on your economy rather than try to deliberately attack someone else’s. This strategy of beating up the weaker players sucks ass.
I do think it’s funny that after all this time, he remembers this game, thinks Mark cheated at the game with out-of-gamesmanship, and he’s been telling this story “for years”. I’m inclined to believe one of two things: Dex was trying to throw and is covering his ass badly, or Dex was earnestly trying to win and is just terrible at Catan strategy. I think the second is funnier, so I’m going with that. Get better at board games Dex!!!
His rebuttal does confirm that this Settlers of Catan game was real, so I believe Sarah when she says Mark accuses her of cheating after she beats him at Ticket to Ride.
Mark broods for much of the flight. When he suggests a board game, I agree to play explicitly on the condition that I don’t have to let him win. He thinks I’m joking. When I trounce him at Ticket to Ride, he accuses me of cheating. This irks me. […] He challenges me to Settlers of Catan. A couple of other staffers join. I win. He does it again.
“You definitely cheated that time,” he says loudly.
She then says that Mark had tunnel visioned on winning Longest Road and would have won if he’d made some different plays on his last turn. This is a pretty plausible Catan endgame to me. I didn’t think we’d need to add someone else to the Gamer but Cringe tier, but saying someone’s cheating at a Eurogame with almost 100% public information is certainly pretty cringe.

Reed Hastings
Reed Hastings is a co-founder of Netflix. As a streaming company, he’s certainly aware of other forms of entertainment. In the 2018 Q4 letter to shareholders, he specifically calls out video games, identifying that Netflix’s competition isn’t against other streaming services, it’s against screen time in general. Their big competitor is Fortnite.
In the US, we earn around 10% of television screen time and less than that of mobile screen time. In 2 other countries, we earn a lower percentage of screen time due to lower penetration of our service. We earn consumer screen time, both mobile and television, away from a very broad set of competitors. We compete with (and lose to) Fortnite more than HBO. When YouTube went down globally for a few minutes in October, our viewing and signups spiked for that time. […] There are thousands of competitors in this highly-fragmented market vying to entertain consumers and low barriers to entry for those with great experiences. Our growth is based on how good our experience is, compared to all the other screen time experiences from which consumers choose. Our focus is not on Disney+, Amazon or others, but on how we can improve our experience for our members.
I’m not sure many people know this, but Netflix does have a games division, as part of their attempt to expand offerings available to Netflix subscribers. It’s really unclear to me how much growth this drives.
I haven’t been able to find any articles saying he’s played video games himself, so I think Reed sees them as a vehicle of screen time rather than something to actually play.

Bill Gates
Bill Gates is the former CEO of Microsoft, and isn’t much of a gamer. Yet he has made a video game. It’s called DONKEY.BAS, and it sucks.
Of all places, the car site The Autopian has the best summary of its gameplay, history, and context. The game is nominally a driving game, but the gameplay is even more limited than Desert Bus. In DONKEY.BAS, you control a car, and can press Space Bar to change lanes. This is the only control you have. Donkeys will appear in the lanes of the road, and your goal is to dodge the donkeys as much as possible.

(Credit: The Autopian)
The story is that it was a tech demo for the IBM PC. Microsoft had been contracted to develop an operating system for the PC, and they needed a game to demonstrate what could be done on the machine. Hence, DONKEY.BAS.
Does this make Bill Gates a gamer? Eh, probably not. It is the other stories around Bill that sells his gamer cred.
Kyle Orland (senior editor at Ars Technica) has written a book about the history of Minesweeper, including an anecdote of Bill getting horribly addicted to the game. When Minesweeper was first launched internally at Microsoft, it became wildly popular. People would send in bug reports, and get sent back an explanation of how their logic was wrong. A product manager on the Minesweeper team (Bruce Ryan) was asked to remove Expert difficulty because it was impossible, and they had to walk into the requester’s office and spend 10 minutes beating an Expert board to convince them it was valid.
Then came Bill. He started by telling Ryan he’d cleared Beginner in 10 seconds, and wanted to know if that was any good. When told the company record was 8 seconds, Bill made it his mission to get the record. This may make him one of the earliest speedrunners. It got so bad that they uninstalled Minesweeper from Bill Gates’s computer. Unfortunately, this didn’t stop him, because Bill walked down the hall and played Minesweeper from the president’s office until he set a new record.
“Because the high scores were [an easy-to-edit] text file, we had a rule that somebody had to put eyes on your [record] score,” Fitzgerald said. “So… it was one Sunday afternoon, and we get email from Bill saying, ‘Hey, I think I just got a new high score. It’s on the machine in [short-lived Microsoft President] Mike Hallman’s office.’ And [we were] like, ‘What?’”
Ryan recalled the surreal experience of being called in by Bill Gates on a random weekend only to cluster around another executive’s computer and confirm a new Minesweeper high score of five seconds on a Beginner board. “This was early evening. So we went over there, seven at night. [Hallman] was a former Boeing executive, and he was not a humorful guy, so… the idea that Bill is sitting there after work, going into the president’s office so he could play Minesweeper, it was just weird imagery.”
“That was when I realized how much valuable time a game could waste.”
More recently, Bill Gates talked about video games when doing a book review of Tomorrow, and Tomorrow, and Tomorrow. In it, he directly says he’s not a gamer, except maybe he is a gamer.
Am I a gamer? For a long time, I would have said no because I don’t spend hundreds of hours going deep on one game.
But when I was younger, I loved arcade games and got very good at Tetris. And in recent years, I have started playing a lot of online bridge and games like Spelling Bee and a bunch of the Wordle variants. The definition of a gamer is becoming a lot broader and more inclusive, and it might be fair to start calling me one.
I will put Bill as a casual gamer, but he makes a strong case for the Gamer tier and would understand that placement too.

Dario Amodei
Dario Amodei is the CEO of Anthropic. Given how new his rise to tech CEO celebrity-ism is, you’d think there wouldn’t be much information about his video game habits, but somehow, there is. In 2025, The Sunday Times did an interview with several members of the Anthropic founding team, then started their article with this banger of an opening.
Most Sunday nights, Dario Amodei heads over to his younger sister Daniela’s house to play their favourite video game, Final Fantasy VII Remake, set in a dystopian world where the goal is to stop an all-powerful corporation from plundering the planet’s resources.
Then, on Mondays, they show up at the headquarters of Anthropic, the $60 billion rival to OpenAI they co-founded, to develop artificial intelligence (AI), which they believe will soon replace swathes of human work and, in the process, probably transform their start-up into one of the megacorporations of tomorrow.
I will not comment further, but I think we can agree that playing FF7 Remake makes you a gamer.

-
AI Will Not Make Your Job Chill
CommentsPeople keep talking about how AI will make their job easy, and I don’t really understand why.
In the Industrial Revolution, textiles were broadly automated. A single person’s labor could now produce much more cloth than before. It turned out people like having nice clothes, demand for shirts went up, and now I own several novelty T-shirts that I wear once a year. I assume the factory job producing this was still hard work.
Richard Gatling, inventor of the gatling gun, invented the first machine gun. According to a letter he wrote to a friend, he was motivated by reducing the size of armies.
It occurred to me that if I could invent a machine—a gun—which could by rapidity of fire, enable one man to do as much battle duty as a hundred, that it would, to a great extent, supersede the necessity of large armies, and consequently, exposure to battle and disease be greatly diminished.
In practice, the appetite for war was quite big (war being zero-sum), so armies were still big during WW1 and WW2. Soldiers in those wars did not have an easy time despite their better tech.
The thing I’m gesturing to here is that something being easier to produce doesn’t lead to people doing the same work in less time. There is instead a complicated relationship of how much new demand is unlocked, the best ways to get people to fill that new demand, and the resulting equilibrium typically still involves hard work.
With the rise of coding agents in particular, I find I have less downtime than before. It feels like if I am not sending an agent on an adventure, I’m not doing all that I could. And, this is not an unfamiliar feeling. ML work was like this too. If you aren’t running an experiment training a model overnight, what are you doing?
As coding has become more commoditized, there is a growing divide between people who liked building software, and people who liked writing code. I was one of the weirdos who liked the latter, who got into coding via algorithms and found tech interviews fun. Writing code was my downtime between conceptual work. Now this is gone, because it’s irresponsible to write code from scratch. Writing code from scratch is for free time now.
I don’t think AI has made my job chill, and I feel like I am front-line compared to much of the economy. My expectation is that although more slices of my job as a researcher will be automated, the remaining work will just expand to fill the remaining time, and there won’t be any top-level agreement that all AI researchers will agree to only work 20 hours a week. The pressures of competitive capitalism will push too hard on maximizing output.
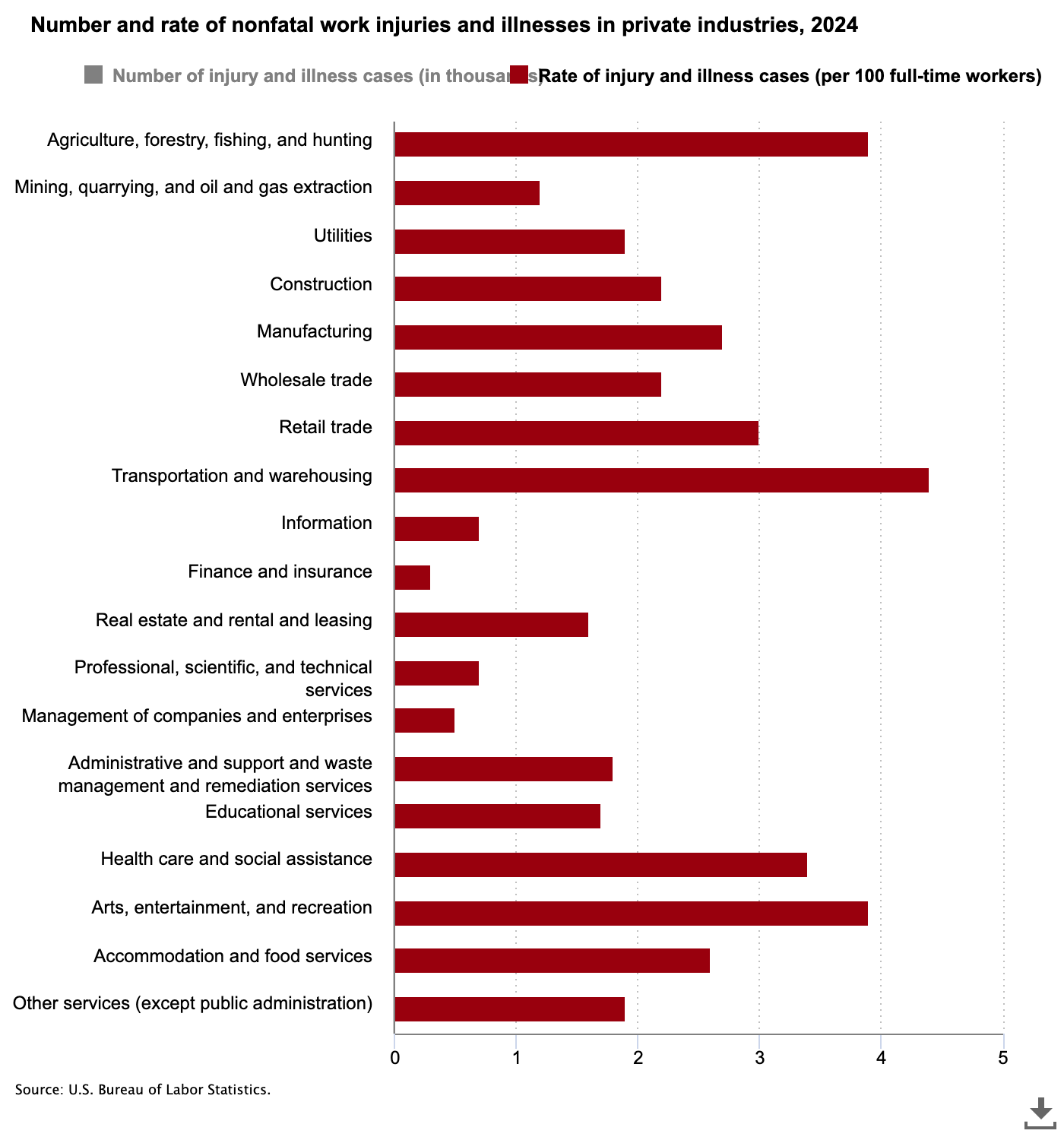
Amazon warehouses are another good case study for this. If you had to pick a single company that speedruns capitalism, Amazon is top of the list. It’s not widely known, but transportation and warehousing has the highest rate of nonfatal work injuries in the US. Based on the Bureau of Labor Statistics, the 2024 rate was 4.4 injuries and illnesses per 100 full-time workers.
How do Amazon warehouses in particular compare? The results are not great. Based on reports from labor unions, Amazon warehouses were 7.7 injuries per 100 FTEs in 2021. For fulfillment centers, warehouses with robotic facilities see more injuries per worker, not fewer. This is attributed to two factors:
- Quotas at facilities with robots are set higher, increasing from 100 items per hour to 300-400 items per hour. This increased speed puts more pressure on workers.
- To satisfy the robot systems, workers do narrower ranges of motion more often, which increases RSI issues.
It’s hard to deny this works as a consumer. My Amazon packages arrive on time. Still, the automation sure didn’t make fulfillment center jobs be chill, safer, or more relaxing. Do LLM improvements make skilled labor more similar to fulfillment center work, or less?
Projecting the future is notoriously hard, but here is my best guess. LLMs will get better at an increasing range of skills. For a while, this will not lead to any job loss, because increasing abundance will lead to higher demand. But the nature of those jobs will become either more tiring, or more boring, or both. They will still be rewarding, or better than they were before if you’re a fan of high intensity work. It certainly won’t be chill.
And then, slowly then all at once, certain jobs will have 100% of their required skills be completable by LLMs, and those jobs won’t exist anymore.
P.S: Certain jobs disappearing doesn’t say anything about the overall labor market. It’s very possible employment stays the same as alternate kinds of jobs arise. However, I think it’s important that people typically argue that either employment will go down, or employment will stay the same. No one says employment will go up. I don’t feel informed about the question of employment, so my uninformed guess is to take the average and say it’d go down.
-
Why I Signed The Amicus Brief for Anthropic v Department of War
CommentsOn Monday, Anthropic filed a lawsuit against the Department of War, and an amicus brief in support of Anthropic was filed on behalf of a number of OpenAI and Google employees. See coverage here and the brief itself here. To emphasize, everyone who signed did so in a personal capacity. There’s also an amicus brief filed on behalf of Microsoft. That one is speaking for the company, focusing on a temporary restraining order of the supply chain risk designation.
I don’t plan to write more about this subject, but will briefly explain why I signed.
In many ways, I thought the fight between Anthropic and the government was one of the more important stories in the world. There’s conflicting reporting, but very broadly, Anthropic signed an agreement with the government to deploy Claude in classified, military contexts. There was then a falling out. According to some, this started because Anthropic asked questions about if their model was used in the Maduro raid. According to others, the conflict came from the government asking a hypothetical about automated defense missiles, and not liking Anthropic’s answers. The leaked Anthropic memo says the negotiations fell apart because Anthropic refused to delete a phrase about using AI in “analysis of bulk acquired data”, covering information obtained by third-party data brokers. Whatever the reality was, the relevant point is that the government no longer liked the deal with Anthropic, and tried to get Anthropic to agree to an updated contract with weaker red line protections. Anthropic said no, Pete Hegseth declared them a supply chain risk, and Anthropic filed a lawsuit against this.
Now, personally, I’m in favor of red lines on domestic surveillance and fully autonomous weapons. You may read the amicus brief if you’re curious why (it’s what I did before signing), but a short version is that I believe domestic surveillance is currently limited by the friction required to do a full collation of all info the US government has on a given citizen. AI tooling could heavily reduce this friction and create a trivially directable surveillance apparatus much stronger than the current one. I am personally okay with a less efficient government, when that loss of efficiency is in the name of preserving civil liberties, rather than dumb reasons like outdated software. As for fully autonomous weapons, I don’t want them to exist at all. But even if you assume they should exist (and this is a big assumption), the reliability of AI is not high enough for them. The only exception I can think of right now is situations where a missile is already in the air, and your options are to autonomously shoot it down or fail to react in time at all.
Separate from the debate you can have over how AI should be used, I also understand that the US government has the right to decide the contracts it agrees to, drop them if they no longer fit, and that usage restrictions which could hypothetically cede operational control may not be something the government wants. See Dean Ball’s thoughts on the subject here, the relevant point being:
The Department of War’s rational response here would have been to cancel Anthropic’s contract and make clear, in public, that such policy limitations are unacceptable.
Exiting the contract was fine, but the step of declaring Anthropic a supply chain risk was irrational and way too big of an overreach. It’s just an exceptionally retributive action which helps nobody. Not the military, not Anthropic, and not the people. By making this move, the Department of War claims the power to attack a US tech company’s business and force the tech industry to divest from said company, just because the government doesn’t like them. It’s incoherent and baffling for the US government to promote AI on one hand, and meddle in the free market against a US AI company on the other.
Generally, I’m not wired for political debates. I don’t relish it in the way that Twitter people do. I’m also aware this could have repercussions on either my career or the potential future paths open to me. (To be clear, I don’t expect it to affect much of either, but it was something I considered.) In general, I am a fan of building career capital and preserving optionality. But if you never spend it on things you believe in, what’s the point?
The amicus brief was broadly aligned with my thoughts on the matter, so I signed.