My AI Timelines Have Sped Up (Again)
In August 2020, I wrote a post about my AI timelines. Using the following definition of AGI:
An AI system that matches or exceeds humans at almost all (95%+) economically valuable work.
(Edit: To clarify, this doesn’t have to mean AIs do 100% of the work of 95% of people. If AIs did 95% of the work of 100% of people, that would count too.)
My forecast at the time was:
- 10% chance by 2035
- 50% chance by 2045
- 90% chance by 2070
Now I would say it’s more like:
- 10% chance by 2028 (5ish years)
- 25% chance by 2035 (10ish years)
- 50% chance by 2045
- 90% chance by 2070
To explain why, I think it would be most instructive to directly compare my 2020 post to my current one.
The Role of Compute
The last time I seriously thought about AGI, I saw two broad theories about the world.
Hypothesis 1: Scaling is enough for AGI. Many problems we consider challenging will disappear at scale. Making models bigger won’t be easy, but the challenges behind scaling up models will be tackled and solved sooner rather than later, and the rest will follow.
Hypothesis 2: Scaling current methods is not the right paradigm. It is undeniably important, but we will reach the limits of what scale can do, find we are not at AGI, and need new ideas that are far from current state-of-the-art methods to make further progress. Doing so will take a while.
Quoting myself from 2020,
How much are AI capabilities driven by better hardware letting us scale existing models, and how much is driven by new ML ideas? This is a complicated question, especially because the two are not independent. New ideas enable better usage of hardware, and more hardware lets you try more ideas. My 2015 guess to the horrid simplification was that 50% of AGI progress would come from compute, and 50% would come from better algorithms. There were several things missing between 2015 models, and something that put the “general” in artificial general intelligence. I was not convinced more compute would fix that.
Since then, there have been many successes powered by scaling up models, and [in 2020] I now think the balance is more like 65% compute, 35% algorithms. I suspect that many human-like learning behaviors could just be emergent properties of larger models. I also suspect that many things humans view as “intelligent” or “intentional” are neither. We just want to think we’re intelligent and intentional. We’re not, and the bar ML models need to cross is not as high as we think.
(2020 post)
Most of the reason I started believing in faster timelines in 2020 was because I thought hypothesis 1 (the scaling hypothesis) had proved it had real weight behind it. Not enough to declare it had won, but enough that it deserved attention.
Now that it’s 2024, do I get to say I called it? The view of “things emerge at scale” is significantly more mainstream these days. I totally called it. This is the main reason that I feel compelled to keep my 50% / 90% numbers the same but stretch my 10% number forward. If scaling stops then it’ll take a while, and if it keeps going I don’t think it’ll take that long. The evidence so far suggests that the scaling hypothesis is more likely to be true.
If there is something I did not call, it would be the flexibility of next token prediction.
There are certainly problems with GPT-3. It has a fixed attention window. It doesn’t have a way to learn anything it hasn’t already learned from trying to predict the next character of text. Determining what it does know requires learning how to prompt GPT-3 to give the outputs you want, and not all simple prompts work. Finally, it has no notion of intent or agency. It’s a next-word predictor. That’s all it is, and I’d guess that trying to change its training loss to add intent or agency would be much, much more difficult than it sounds.
(2020 post)
It turned out that next token prediction was enough to pretend to follow intent, if you finetuned on enough “instruction: example” data, and pretending to follow intent is close enough to actually following intent. Supervised finetuning with the same loss was good enough and it was not much more difficult than that. The finding that instruction fine-tuning let a 1.5B model outperform an untuned 175B model was basically what made ChatGPT possible at current compute.
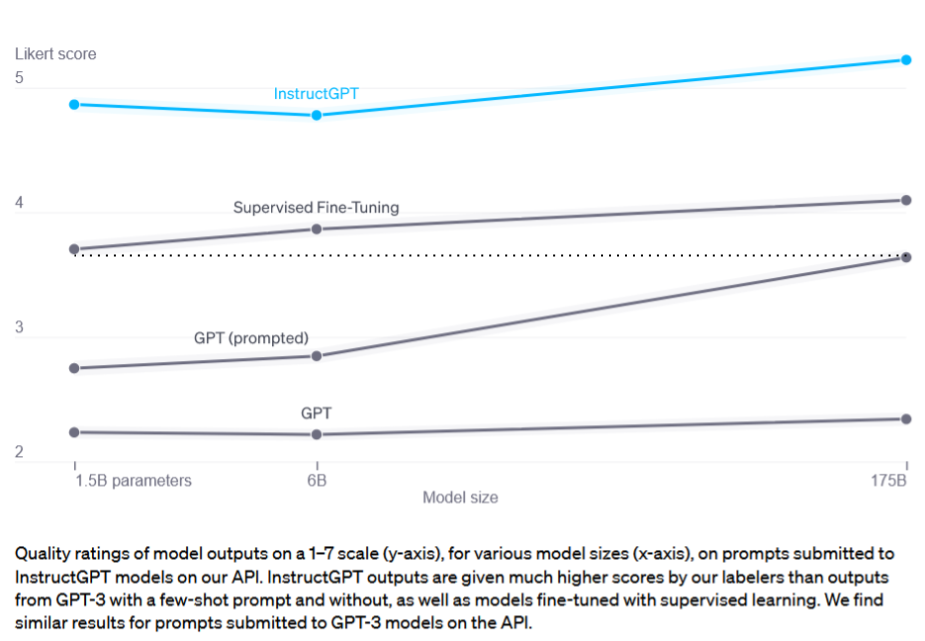
Diagram from InstructGPT analysis, with added line comparing the 1.5B supervised finetuned model to an untuned 175B model. Feel free to ignore the blue line that includes RLHF.
I was correct in claiming that something very important was happening at scale. I was wrong in how many ideas would be needed to exploit it.
Every day it gets harder to argue it’s impossible to brute force the step-functions between toy and product with just scale and the right dataset. I’ve been converted to the compute hype-train and think the fraction is like 80% compute 20% better ideas. Ideas are still important - things like chain-of-thought have been especially influential, and in that respect, leveraging LLMs better is still an ideas game. At least for now - see experiments on LLM-driven prompt optimization. Honestly it wouldn’t shock me if a lot of automatic prompt generation happens right now and just doesn’t get published, based on what people have figured out about DALL-E 3.
Unsupervised Learning
Unsupervised learning got better way faster than I expected. Deep reinforcement learning got better a little faster than I expected. Transfer learning has been slower than expected.
(2020 post)
Ah, transfer learning. I remember the good old days, where people got excited about a paper that did like, 5 tasks, and showed you could speed up learning at a 6th task. Now it is all about large internet-scale models that have gone through enough rounds of next token prediction to zero-shot a wide class of tasks. Or to quote work from my colleagues, “large language models are general pattern machines”. As far as I know, the dedicated transfer learning techniques like PCGrad are not only unused, they don’t get much further research either.
Suffice it to say that unsupervised and self-supervised methods have continued to shine as the dark matter powering every large language and multimodal model. They’re still the best methods for vacuuming up compute and data. Throw everything in the hole and the hole will provide.
If you’ve got proof that a large Transformer can handle audio, image, and text in isolation, why not try doing so on all three simultaneously? Presumably this multi-modal learning will be easier if all the modalities go through a similar neural net architecture, and [current] research implies Transformers are good-enough job to be that architecture.
(2020 post)
I don’t think there are sufficient advances at the algorithms level of unsupervised learning to affect my timelines. It feels compute driven to me.
What about other learning algorithms? There is still a role for supervised learning and reinforcement learning, but they certainly have less hype behind them. When deep reinforcement learning was at peak hype, I remember people accused it of being horribly inefficient. Which it was! The reply I’d always give was that deep RL from scratch was insane, but it was a useful way to benchmark RL methods. The long run would eventually look like doing RL on top of a model trained via other means.
Fast forward to now, and I got my wish, except I’m not happy about it. RLHF people tell me that they think pretty much any RL algorithm will give okay results as long as you have good preference data, and the most important questions are the ones surrounding the RL algorithm.

Calling back to the famous cake slide from Yann LeCun’s NeurIPS 2016 talk on predictive learning, people respect the cherry but it’s natural for people to care more about the cake. The slide is “slightly offensive” but I’d say it came slightly true.
I still think better generic RL algorithms are out there, and they would make RLHF better, but it’s harder to justify searching for them when you could spend the marginal compute on extra pretraining or supervised fine-tuning instead. It’s what you turn to after you’ve done both of the former. Robot learning in particular has drifted towards imitation learning because it’s easier to work with and uses compute more effectively. At least in my research bubble, the field is drifting from generic RL methods to ones that exploit the structure of preference data, like DPO and its siblings. Still, I feel obligated to plug Q-Transformer, a generic RL + Transformers paper I worked on in 2023.
Better Tooling
In the more empirical sides of ML, the obvious components of progress are your ideas and computational budget, but there are less obvious ones too, like your coding and debugging skills, and your ability to utilize your compute. It doesn’t matter how many processors you have per machine, if your code doesn’t use all the processors available.
[…]
The research stack has lots of parts, improvements continually happen across that entire stack, and most of these improvements have multiplicative benefits.
(2020 post)
Nothing in the tooling department has really surprised me. However, as more people have moved to Transformers-by-default, the tools have become more specialized and concentrated. Stuff like FlashAttention wouldn’t be as much of a thing if it weren’t relevant to like, literally every modern ML project.
If I had to pick something I missed, it would be the rise of research via API calls. API owners have a wider audience of hobbyists, developers, and researchers, giving more economic justification to improve user experience. I also liked Pete Warden’s take, that people are now more interested in “the codebase that’s already integrated LLaMa or Whisper” over generic ML frameworks.
Overall I’d say tools are progressing as expected. I may have been surprised when LLM assistants appeared, but I always expected something like them to arrive. However, I missed that the pool of people providing research ideas grows as AI becomes more popular and accessible, which should account for some speedup.
Scaling Laws
At the time I wrote the original post, the accepted scaling laws were from Kaplan et al, 2020, and still had room for a few orders of magnitude.
Two years after that post, Hoffman et al, 2022 announced Chinchilla scaling laws showing that models could be much smaller given a fixed FLOPs budget, as long as you had a larger dataset. An important detail is that Chinchilla scaling laws were estimated assuming that you train a model, then run inference once on your benchmark. However, in a world where most large models are run for inference many times (as part of products or APIs), it’s more compute optimal to train for longer than Chinchilla recommends, once you account for inference cost. Further analysis from Thaddée Yann TYL’s blog suggests model sizes could potentially be even lower than previously assumed.
Despite the dramatic reductions in model size, I don’t think the adjustments to scaling laws are that important to model capabilities. I’m guessing the Pareto frontier has bent slightly, but not in a dramatic way. Maybe I am wrong, I have not seen the hard numbers because it seems like literally every lab with the resources has decided that scaling laws are now need-to-know trade secrets. But for now, I am assuming that FLOPs and data are the bottleneck, and if you control for both we are only slightly more efficient and new scaling laws haven’t affected timelines too much.
I’d say the most important consequence is that inference times are much smaller than previously projected. In combination with smaller model sizes, there’s been a lot of progress in quantization to make those models even smaller in scenarios where you’re time or memory limited. That’s made products faster than they otherwise would be pre-Chinchilla. In the early 2010s, Google did a lot of research into how much delays impact search engine usage, and the conclusion was “it matters a ton”. When search engines are slow, people use them less, even if the quality is worth waiting for. ML products are no different.
Speaking of…
Rise of the Product Cycle
As part of the 2020 post, I did an exercise I called “trying hard to say no”. I decided to start from the base assumption that short-term AGI was possible, describe my best guess as to how we ended up in that world, then see how plausible I found that story after writing it. The reason to do this is because if you want to be correct that AGI is far away, you have to refute the strongest argument in favor of short-term AGI. So, you should at least be able to refute the strongest argument you come up with yourself.
At the time, I described a hypothetical future where not many ideas would be needed, aside from scale. I assumed someone developed an AI-powered app that’s useful enough for the average person.
Perhaps someone develops an app or tool, using a model of GPT-3’s size or larger, that’s a huge productivity multiplier. Imagine the first computers, Lotus Notes, or Microsoft Excel taking over the business world.
(2020 post)
This hypothetical app would bring enough revenue to fund its own improvement.
If that productivity boost is valuable enough to make the economics work out, and you can earn net profit once you account for inference and training costs, then you’re in business - literally. Big businesses pay for your tool. Paying customers drives more funding and investment, which pays for more hardware, which enables even larger training runs.
Since this idea would be based on scale, it would imply the concentration of research into a narrower set of ideas.
As models grow larger, and continue to demonstrate improved performance, research coalesces around a small pool of methods that have been shown to scale with compute. Again, that happened and is still happening with deep learning. When lots of fields use the same set of techniques, you get more knowledge sharing, and that drives better research. Maybe five years from now, we’ll have a new buzzword that takes deep learning’s place.
I thought this was a helpful exercise, and concluded by saying “the number of things that have to go right makes me think it’s unlikely this will occur, but it’s worth considering”.
And then everything I thought was unlikely came true.
We have a ChatGPT app, which went viral and inspired a large cast of competitors. It is not a huge productivity booster, but it’s enough of one that people are willing to pay for it. Supposedly Microsoft loses $20/user on Copilot, but David Holz has claimed Midjourney is already profitable. I’d split the difference and say most AI services could be profitable, but run at a loss in the name of growth.
This has driven tech giants and VCs to throw billions at hardware and ML talent hiring. Deep learning is old news - now everyone says “LLM” or “generative AI” or “prompt engineering”. Masked Autoencoders can handle audio, multimodal Gemini and GPT-4V handle vision, and a few video generation models are uncanny but making good progress.
To me it now seems completely obvious that transformers will be pushed much, much further than any other model architecture in the history of machine learning. There is too much hype, the scaling is inevitable, and even if the doomers’ point of view becomes more popular, there are enough optimists that I expect somebody will push forward, safety and alignment and fairness concerns be damned. To borrow a point from Gwern’s essay on timing, speculative technology is created by the experts with the most faith that it will succeed. It will always seem insane that those experts could be correct, and in fact those experts will usually be too early, but when they are right they will succeed before the world catches up to their ideas. And experts with the most faith tend to understand the possible negative externalities, but assume they’ll be fine. For better or for worse.
Trying to Say No, Again
Let’s run this exercise of “let’s assume near-term AGI is possible, how do we get there” again, to see what’s changed.
Once again, we’d assume progress comes primarily from larger compute budgets and scale. Maybe it’s not transformers, maybe one of the “transformer replacements” that claims to be more efficient will finally win. (I know some people are excited about Mamba and other state-space models.) Increasing parameter count in code is easy if you have the compute and data to exploit it, so let’s assume the bottlenecks are on compute and data. We can take “ML powers products powers funding powers ML” as a given. That’s just what’s happening. The question is whether something will make scaling fail.
I don’t really know enough about hardware to discuss it in any detail, so let’s just assume it’ll continue to grow. Computer chips have gotten more expensive, given that everyone is keeping their eyes on them, including nation states. Still, computers are useful, ML models are useful, and even if models fail to scale, people will want to fit GPT-4 sized models on their phone. It seems reasonable to assume the competing factions will figure something out. The silicon must flow, after all.
Data seems like the harder question. (Or at least the one I feel qualified talking about.) We have already crossed the event horizon of trying to train on everything on the Internet. It’s increasingly difficult for labs to differentiate themselves on publicly available data. Differentiation is instead coming from non-public high-quality data to augment public low-quality data. The rumor is that GPT-4 is good at coding in part because OpenAI spent a lot of time, effort, and money on acquiring good coding data. Adobe put out an ad asking for “500 to 1000 photos of bananas in real life situations” for their AI projects. Anthropic has a dedicated “tokens” team to acquire and understand data, based on job listings. Everyone wants good data, and they’re willing to pay for it, because people trust the models can use that data effectively as long as they can get it.
All the scaling laws have followed power laws so far, including dataset size. Getting more data by hand doesn’t seem good enough to cross to the next thresholds. We need better means to get good data.
A long time ago, when OpenAI still did RL in games / simulation, they were very into self-play. You run agents against copies of themselves, score their interactions, and update the models towards interactions with higher reward. Given enough time, they learn complex strategies through competition. At the time, I remember Ilya said they cared because self-play was a method to turn compute into data. You run your model, get data from your model’s interactions with the environment, funnel it back in, and get an exponential improvement in your Elo curves. What was quickly clear was that this was true, but only in the narrow regime where self-play was possible. In practice that usually meant game-like environments with at most a few hundred different entities, plus a ground truth reward function that was not too easy or hard, and an easy ability to reset and run faster than real time. Without all those qualities, self-play sputtered and died with nothing to show for it besides warmer GPUs.
I think it’s possible we’re at the start of a world where self-play or self-play-like ideas work to improve LLM capabilities. Drawing an analogy, the environment is the dialogue, actions are text generated from an LLM, and the reward is from whatever reward model you have. Instead of using ground truth data, our models may be at a point where they can generate data that’s good enough to train on.
There are papers exploring this already, usually under the umbrella term “synthetic data”. One of the early results around GPT-4 by Pan, Chan, Zou et al was that GPT-4’s label accuracy was competitive with human crowdworkers. Diffusion based image augmentation has been shown to improve robot learning, and Anthropic has based a lot of its branding on constitutional AI and “RL from AI feedback”. NeurIPS had a workshop on synthetic data as well. Other papers more directly use self-play terminology - see Improving Language Model Negotiation from Fu et al and Self-Play Fine-Tuning from Chen et al.
Language models in 2024 remind me of image classification in 2016, where people turned to GANs to augment their datasets. One of my first papers, GraspGAN, was on the subject, and we showed it worked in the low-data regime of robotics. “Every image on the Internet” is now arguably a low-data regime, which is a bit crazy to think about.
If the models don’t eat their own tail, the end result is a world where data becomes increasingly untethered from human effort, and progress just fully turns into how many FLOPs you can shovel into the system. Even if the accuracy of synthetic labels is worse, it’s often cheaper. I expect these ideas to work, although I’m uncertain on the time scale, and the result will be a world where direct human feedback is only used to bootstrap reward models for new use cases or sanity check data generated for existing ones. Everything else will be model-generated and model-supervised, feeding back into itself, with increasingly indirect human supervision.
Language models are a blurry JPEG of the Internet, but that is because current LLM text is bad for training. Blurrifying the Internet was the best we could do. What happens if that changes, and LLMs become blurry JPEGs of something clearer than the Internet?
Search and Q*
I don’t have too much to say about search, but I should mention it briefly.
During the Sam Altman drama, Reuters reported a method called Q*, creating a lot of speculation. In the circles I was in, the assumption was that it was some Q-learning driven search process. Eventually Yann LeCun put out a post saying people really needed to cool down, since literally every lab has looked into combining search with LLMs, and it would not be that surprising if someone made it work.
He was 100% correct. It is a very obvious idea to try. DeepMind put out a preprint that CNNs are good evaluators of Go moves in December 2014, added search via MCTS, and turned it into AlphaGo within a year. It was the ML success story of the decade. People do not forget the lessons from machine learning’s crowning achievements.
Search methods are usually very computationally inefficient, and I don’t know if our base models are good enough to use as search subroutines. Taking MuZero as a data point,
For each board game, we used 16 TPUs for training and 1000 TPUs for selfplay.
This is about a 100x increase in compute hardware. Still, one benefit of search is that it really ought to work. It is one of the most reliable ideas in machine learning. The reason we use search less now is because we’ve come up with better ideas for how to use compute. Search will always be there to eat marginal FLOPs if we run out of better ideas. Think harder, then teach yourself to come up with your final result the first time.
How Believable is All This?
Overall I think it’s plausible that we’ll continue to scale, that some of the perceived bottlenecks won’t matter, and we’ll discover ways to use current models to widen the ones that do. I’m finding it increasingly hard to refute that view of the world.
This theory of the world does rely heavily on model-generated data panning out. It’s possible that theory doesn’t play out. Or, that it leads to some gains, but runs into diminishing marginal returns. Still, let me know when you see the scaling laws hit a wall, instead of talking about why they ought to stop. So far, I don’t think they have.
On Hype
In 2016, a few prominent ML researchers decided to pull a prank. They set up a site for “Rocket AI”, based on some mysterious method called “Temporally Recurrent Optimal Learning” (TROL), then all coordinated stories about a wild launch party at NeurIPS 2016 that got shut down by the police. It was all fake, as detailed in this postmortem. There’s a fun quote near the end:
AI is at peak hype, and everyone in the community knows it.
Here’s the Google search trends for “AI” since 2016, scaled out of 100. Let’s see how peak 2016 hype compares to now.
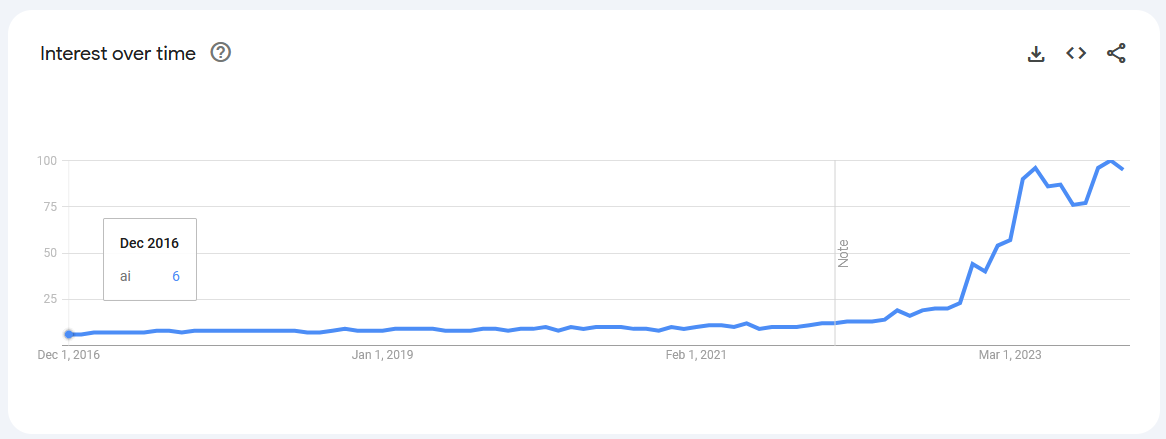
Oh, what naive children we were! I do think it’s funny that AI is one of only a few research topics where people try to play down hype for the sake of the conversational commons. Imagine feeling like you need to discourage people from being interested in your research. There’s a real privilege there.
I have really really tried to avoid getting caught up in hype. I don’t like AI Twitter for reasons I’ve explained here, but I especially do not like AI twitter post-ChatGPT. So I want it clear that when I say I think AGI could be soon, I am not doing it for street cred, or to fit in. It is something that feels genuinely possible. The routes for improvement are clear, it’s just a question of if they will fail assuming billions of dollars of funding.
In AI, models can never do everything people claim they can, but what the models can do is ever-growing and never slides backward. Today is the worst AI will ever be. Even if all the VC companies bust and LLMs dry up, we’ll still have the models that are already trained and the ideas already derived. There is no going back. I’d recommend people think about what that means.
Everything has been changing since last generation was born
And they won’t try to take in change is a two edged sword
Thanks to all the people who gave feedback on earlier drafts, including: Diogo Almeida, Vibhor Kumar, Chris Lengerich, Matthew P. McAteer, Patrick Xia, and Hugh Zhang.
Appendix - The Bull and the Bears
When getting feedback on early drafts of this post, the main lesson I learned is that for AGI, there is one bull and many bears. The bull is to say that we can figure out how to scale models, and scaled up models will solve all the other hard problems. The bears are to declare X, Y, or Z as reasons progress will slow down or stop. And everyone has a different bear.

I ignored these bears in the main text because I felt it disrupted the flow of the argument, but I do want to acknowledge and reply to the bearish counterarguments I’ve come across. If I don’t mention your bear, I apologize.
The Data Provenance Bear
This article from Scientific American asks whether generative AI is making itself harder to train, by polluting the Internet with junk LLM text. For a more malicious angle, some papers have explored whether you can poison datasets by deliberate data injection - see Carlini et al, 2023.
As I’ve argued earlier, I think this is very important in the short term, but will be worked around and become less important later. The entire “AI self-play” thesis assumes that we will cross a tipping point where LLM text (filtered in some way) is good enough to train with.
One thing this does impact is our ability to evaluate models. I feel like every surprising LLM result gets accused of test set leakage these days, because it has happened before and is increasingly hard to verify it isn’t happening. That does drag on research, especially as running evals at all becomes expensive. But, coming from robot learning I am quite biased to think that will be annoying rather than existential. In robot learning “our benchmarks are both expensive and bad” has been true ever since 2016. and we’ve still found ways to go forward.
The Overhangs Bear
For people unfamiliar with the term as it’s used in AGI discussion, an overhang is when the ideas to create really good AI exists, but people don’t know it yet. There is an overhang between the best model creatable with present resources, and the best models we actually have. Once people believe in the ideas, you see a rapid increase in capabilities as researchers quickly assemble the right ideas together and fill in the overhang.
The implication is that progress relative to compute will be faster than it “should be” while the overhangs are filled. Extrapolating progress during overhang filling would overestimate future progress.
I think this view of the world is correct in describing how technology evolves and I’d agree that there are fewer overhangs in 2024 compared to 2020. Where it breaks down for me is that this view doesn’t give great guidance on when the next overhang will appear. “There are important combinations of ideas people have not put together yet” is just always true and part of why people do research. To me, “overhangs exists” sounds the same as “progress is a series of sigmoid curves”, where every so often you go through an inflection point. Making a projection during the inflection point is wrong, but so is doing so after the inflection point. The important question is how often the field reaches new inflection points.
I’m not sure how good scaled up transformers can get, but we’re not done with trying to scale them up. It’s possible the next big inflection point lies in better computers rather than better neural nets. I have a friend who runs an ML computing startup, and he used to ask me “what would you do if you magically had 1000x more FLOPs and 1000x more memory?” He stopped asking me this question after GPT-3. I think he knew my answer by then.
The “Scaling is Hard” Bear
A friend reminded me that for every LLaMa, there’s a Meta OPT that doesn’t live up to expectations. If you’re bored one day, the team behind OPT released a very detailed logbook of the issues they ran into. It features gradient overflows during Thanksgiving, mysterious activation norm spikes that traced to an accidental library upgrade, and more.
Scaling isn’t exactly a “numbers go up, use more hardware, oops we have state-of-the-art” game. It requires not just ML expertise, but a more specific expertise that (I assume) is learned mostly by experience rather than reading papers.
So, one theory you could have is that figuring out how to scale ML model training becomes a research problem of its own, that is not solved by scale, and eventually becomes so intractable that progress stalls.
I don’t find this theory particularly likely, given the history of scaling compute so far, and scaling of other big projects like the Apollo program (support bigger rockets) and Manhattan Project (get more enriched uranium). But I don’t have any specific argument against it.
The Physically Embodied Bear
One of the classic questions in ML is whether intelligence is bottlenecked on physical embodiment.
If this model is good at language, speech, and visual data, what sensor inputs do humans have that this doesn’t? It’s just the sensors tied to physical embodiment, like taste and touch. Can we claim intelligence is bottlenecked on those stimuli?
(2020 post)
Humans grow up and learn from a huge host of stimuli and sensors. Models learn differently. Large ML models do not have to learn the same ways humans do, but the argument goes like this:
-
Our AGI definition is
An AI system that matches or exceeds humans at almost all (95%+) economically valuable work.
- 95%+ will include taking physical, real-world actions.
- Right now, the majority of data feeding models is not embodied. If we assume scale is the answer, lack of embodied data will make it hard to scale.
Right now, I don’t think intelligence is bottlenecked on having data from physical stimuli, but performing well at real tasks likely is.
There are recent efforts on improving availability of embodied data in robot learning, like Open X-Embodiment, as well as prior datasets like Something-Something and Ego4D. These might not be big enough, but I don’t see a reason you can’t use models to generate your way out of the limited embodied data that exists right now. People are exploring this right now - see Universal Policies from Du and Yang et al, 2023. One of the big reasons I co-led AutoRT was because I thought it was important to explore what embodied foundation models looked like and push towards getting more embodied data - because I would much rather have a dumb physical assistant than a superintelligent software assistant. The latter would certainly be helpful, but I find it more concerning.