Posts
-
Authentic Imperfection
CommentsAuto-Tune is great.
I used to be ambivalent on this, but got radicalized by a video from Sideways. I will give the quick version.
Auto-Tune is one of many pitch correction tools that can be used to tighten up slightly off-key vocals. Its intended use was to reduce time spent getting the perfect take, by doing light adjustments to an existing performance.
Although intended as a background tool, it entered public consicousness when artists like Cher and T-Pain deliberately used it to an extreme degree because they liked the audio effect. This was special at the time, but ever since, they have been accused of not being real singers. T-Pain especially, even when there are many recordings of T-Pain singing live.
A ton of music artists use Auto-Tune, because audience expectations around music production have escalated rapidly, causing the baseline of “good singer” to rise. From just a musical standpoint, we get better music - cool! From an overall standpoint, it’s more mixed.
These tools have advanced to the point where pitch correction can be done live in real-time, and once again, most people can’t tell it’s happening. Concerts sound better, but no one will ever acknowledge this, thanks to the public stigma around Auto-Tune, and the assumption that if you use it, you don’t have talent.
This has led to an interesting place. Either your music performance needs to be perfectly pitch corrected, or it needs to be slightly off from perfect. The latter is implicitly considered a sign of authenticity: no one would tune themselves to sound wrong.
Sideways’ channel is specifically about movie musicals, so the video segues into how the music from the Les Miserables movie is really bad, but there’s something novel here. We want pure music, but only some kinds of music production count as pure.
This video is from 2020. Within three years, ChatGPT and DALL-E came out, and we speedran this discussion all over again.
* * *
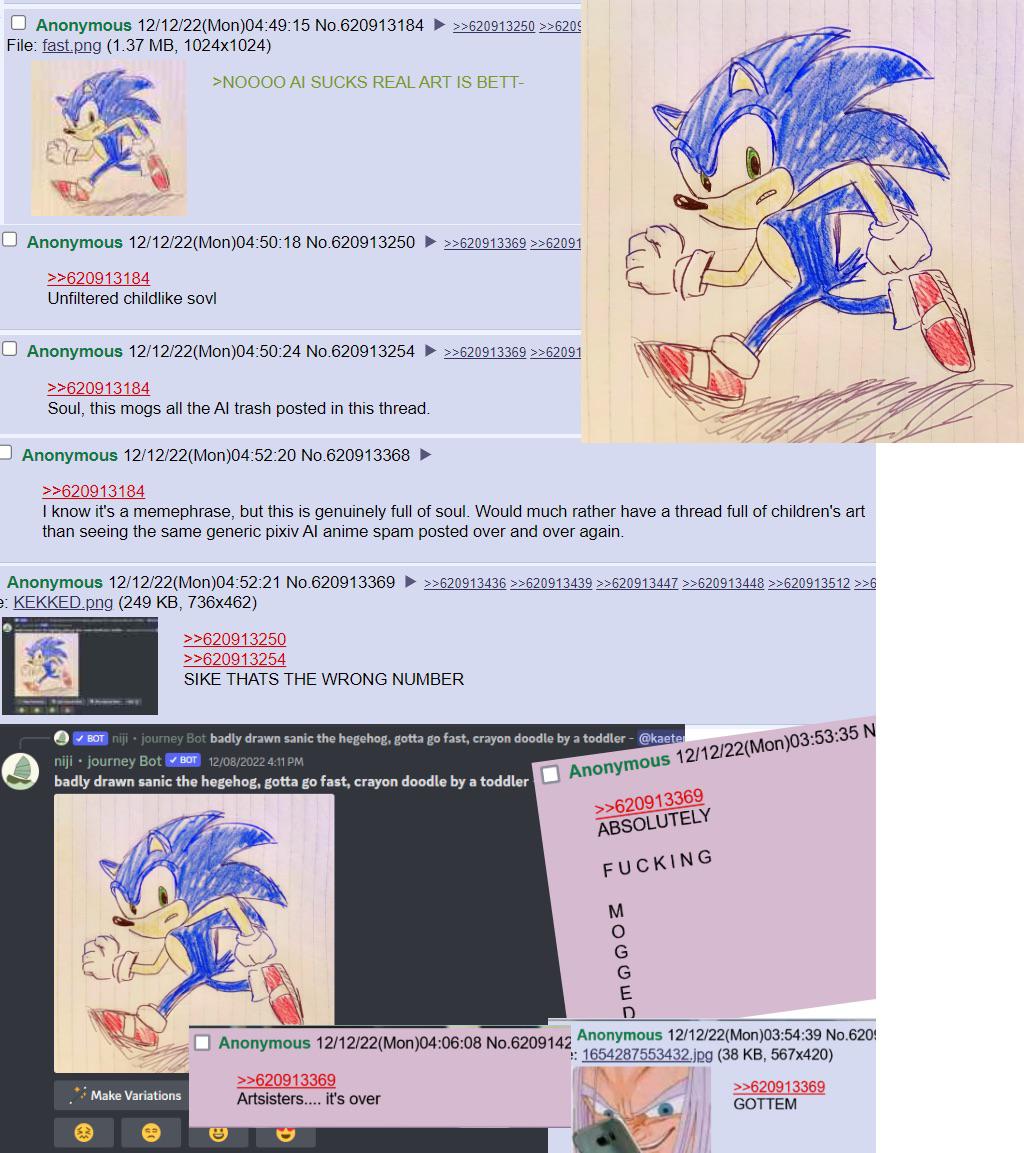
I’ve been thinking about the anger surrounding generative AI. There are common themes. It uses too much energy, it violates too many copyrights, the content isn’t even good.
I think the last point was easier to argue in the past and has gotten harder over time. What does it even mean for content to be good? It’s a very fuzzy, subjective thing, and there are recent surveys suggesting even the AI haters can’t tell all the time. Last year, Scott Alexander of Astral Codex Ten ran an AI art Turing test. To keep things fair, he took the best human images and best AI images, meaning human art from famous artists, and AI art from prompters skilled at removing obvious tells of image generation.

The median responder only identified 60% of images correctly, not much above chance. And, interestingly, when asked which picture was their favorite, the top two pictures were AI generated, even among people who said they hated AI art.
So what’s going on here?
When people complain about AI slop, I see it as a complaint against the deluge of default style AI images. First, it was hands with the wrong number of fingers. Then it was the overproduced lighting common to DALL-E and Midjourney outputs. Then it was the Studio Ghibli style and vaguely yellow filter common to ChatGPT generations. But these aren’t the only things image models can do. They’re just the quickest, trendiest thing. The things that become trendy are the things which become obviously artificial by sheer volume.
I’ve spent a very large amount of time overall with Nano Banana and although it has a lot of promise, some may ask why I am writing about how to use it to create highly-specific high-quality images during a time where generative AI has threatened creative jobs. The reason is that information asymmetry between what generative image AI can and can’t do has only grown in recent months: many still think that ChatGPT is the only way to generate images and that all AI-generated images are wavy AI slop with a piss yellow filter. The only way to counter this perception is though evidence and reproducibility.
Like Auto-Tune, there was originally a novel effect to the artificiality, and now it’s just wrong. It’s annoying when Claude Code says “you’re absolutely right!”. It’s weird when LLMs use em dashes, to the consternation of writers who wish they could use them without getting accussed of AI.
There are two reasons why this [em dash] discourse must be stopped: The first has to do with the way generative AI works; the second has to do with the fate of the human soul.
But, importantly, you can make people forgive the artificiality if you try. We’ve seen this happen in all forms: AI text, AI music, older forms of computer generated content like CGI. Mad Max: Fury Road is one of my favorite movies, and one narrative about the movie was its heavy use of practical effects. This was said with the air of “practical is better”, even when Fury Road used digital VFX in nearly every shot. But if you call it digital VFX instead of CGI, no one cares! One is the boring phrase and one is the bad phrase. CGI implies less work than raw human effort, even when the digital VFX industry is notorious for its long hours, poor pay, and unreasonable deadlines.

Comparison by Matt Brown from Toronto International Film Festival
In the comparison above (movie top, original shot below), obviously the main difference is the addition of the truck and the color correction. But did you notice the rock added to disguise the ramp the car jumped off of? (Look under the tires if you didn’t.) I know this is table stakes, everyone does it, but these adjustments are all over the movie, and it’s the kind of attention to detail that means something to me. Intent of that form can shine even when mediated by computers.
I don’t think people really care about AI or not. It’s more of a proxy complaint for whether they can see vision or taste. Or maybe people are shortcutting AI usage as a sign the user doesn’t have vision or taste, out of an assumption that someone with vision would do the work on their own.
We want to see the people behind the curtain. We care what they are trying to say. We interpret idiosyncracies and failings as style. When you learn something was generated artificially, this implicit contract breaks. The idiosyncracies of AI are too correlated to be charming.
I’ve seen a lot AI due to being a highly online person who works in AI, and don’t like most of it, but I had a lot of fun with the AI Presidents discuss their top 5 anime video that metastasized into a trend of AI Presidents discussing nerd culture. There was something honest in its absurdity, where the AI layer was generating the voices, the taste layer was deciding which president would take which role, and it comes together beautifully. Yet I’d admit that if I learned the script was written by an LLM, it would lose some of its magic.
As much as we celebrate imperfection, digital imperfection is a step too far. We see AI in the lens of automation, where failure cannot stand. People don’t want tools that give them more ways to fail, they want agents that make failure impossible. We don’t have them yet and would find ways to complain about them even if we did. Until then, in the uncanny valley of competence, at least the flawed can be kings.
-
Ten Years Later
CommentsMy blog turns ten years old today. The big 1-0. Thanks for reading!
Every now and then, someone asks me why I blog, and I don’t know really know what to tell them. I like writing and I had things to tell? There was a fire and I needed to stoke it? Something around there is approximately correct, but not the full story.
What feels closer is that a long time ago, I was looking for outlets to express myself creatively. Drawing didn’t appeal to me, coding weird digital toys didn’t either, and that left longform writing as one of the natural options. I had already written some long Facebook posts (back in the day where using your Facebook as a blog was a thing people did), so the jump was obvious. And I found once I got started, it was easier to keep going. (If anything, I think I have a harder time stopping things than starting things.)
Maybe that’s why it doesn’t feel like a big deal to cross the ten year mark. Like, I celebrate the milestones, but it doesn’t feel like an accomplishment. It’s more like, blogging is a thing I do which I want to keep doing. Why would it feel special to do something I like doing for 10 years? In life, I try to keep doing the things I find fun. It’s just good policy.
I think it also helps that I take this blog profoundly unseriously. When I wrote my last post, about brony musicians seizing the means of production, I decided to send a draft to an LLM for feedback. I prompted it to be honest and harsh in its criticism, and it told me:
- Your post is too long and meandering.
- You have too many personal anecdotes that aren’t relevant to the main story.
- You’ve buried the lede.
- Get rid of half the words.
On reflection, it wasn’t wrong that the post would be better if it were streamlined, without all the little frills I’d written into it. But I wanted the frills. So I took half its advice, ignored the rest, and that’s partly why it’s got the worst view-to-effort ratio of my entire blog. That’s the upside and downside of being your own editor.
But do I regret writing it? No, not at all. In a world of Substacks and Mediums, it feels good to have this corner of slightly old Internet, outside the storm of content platforms and monetization, where I can write 6600 words about My Little Pony and not feel bad about it. So, really, thanks.
Stats
I spent 93 hours, 7 minutes writing 6 posts this year, which is down from 139 hours + 9 posts from last year. That’s another reason I’m not celebrating 10 years with more gusto, I know I’ve been writing less.
Once again, I wish I could say I had a good reason for this, but the reality is that writing comes out of my free time, I got a new laptop this year, and the laptop came with a free 3 month subscription to Xbox Game Pass. So that turned on the engineer brain of “I need to maximize the value”, and I spent much of those 3 months playing all the Game Pass games I could. By the end, I was frankly pretty disappointed in how I’d spent my time, and decided not to renew it, but the damage was done, and the writing habit never really came back.
I want to be doing more writing, so I’m hoping the numbers trend back up this year. I also want to try some weirder stuff. One thing I’ve realized is that I’ve fallen into a groove with my writing. I did a lot more weird one-offs when I started blogging, when I was figuring out my voice, but now I know the typical style of my posts and it’s easy to stay in my lane instead of branching out. I want to try innovating, play a bit more with the craft of writing. Ten years is as good a time as any to try something new.
Lighthaven, the rationalist aligned event space in Berkeley, is hosting a blogging residency named Inkhaven. If you sign up, you pay $2000 plus housing, to live there during the month of November, committing to writing at least a 500 word blog post each day. If you don’t, you’re kicked out. They’re doing this because they think writing is good for the world, and want to get more people to write regularly. On one hand, the hosts are biased. Anyone familiar with rationalist culture knows that longform maybe-overthinking-it essays are the lifeblood of their community. Of course they have a high opinion on writing’s value. On the other hand, anyone familiar with the influence of those maybe-overthinking-it essays should find it hard to take the opposite position.
Am I going to do Inkhaven? No, they’re asking for full-time commitment and I both can’t and don’t want to do that right now. I’m not looking to spend money to become full-time Professional Writer Man. Did I think about it? Yes.
If the idea of paying to commit to a writing bootcamp appeals to you, you should definitely consider applying, if only because I bet you’ll find your people. Personally, I may do a post-a-day challenge anyways. I did one in 2016, and although most of the posts were trash, it was nice to prove I could do it.
View Counts
484 2024-08-18-nine-years.markdown 5230 2024-12-04-late-o1-thoughts.markdown 271 2025-01-09-destruct-o-match.markdown 944 2025-01-28-mh-2025.markdown 356 2025-04-01-who-is-ai-for.markdown 69 2025-07-21-babscon-2025.markdownAppendix: Video Game Reviews
Look, if Xbox Game Pass took over 3 months of my life, I at least get to review how it did.
UFO 50: This wasn’t part of Xbox Game Pass, but it was the game I played the most last year, I have to shill it. A great game if you’re a person who’s played a lot of video games. If you’re new? Start somewhere else. There’s a very particular thing going on in playing through the catalogue of a fictional video game studio, that makes you appreciate the evolution of game design all the more, but it works best if you’ve got the shared history. There are many games I’ve barely even tried, but I still have so many hours in the ones I did. Mini & Max is GOATed and worth the price of admission on its own.
Starcraft II Campaign: In a past life, I played a lot of Stacraft, enough to know I sucked and to appreciate the pros who didn’t. Coming back, I’ve learned I still suck at this game, but beating up the AI is still fun. I think unfortunately it only ever made it to “okay” though. The story of Starcraft II starts out strong in Wings of Liberty, but gets incredibly bad in Heart of the Swarm. Legacy of the Void redeems it a bit, and then the finale falls all the way back down again. Gameplay wise, it was fun for a while, but at some point rebuilding a base and deathball every game felt like a chore instead of play.
Indiana Jones and the Great Circle: I don’t know how they did it, but Indiana Jones and the Great Circle was just fun all the way through. I got surprisingly invested in the story, it’s voiced well, and the gameplay has a nice balance of exploration, puzzle solving, stealth, and frantically using your whip on Nazis when the stealth inevitably goes wrong. My one complaint is that the hand-to-hand combat feels like the worst part of the game, so of course they put a bunch of upgrades behind learning parry timings you’ll never use later.
Another Crab’s Treasure: The devs of Another Crab’s Treasure are now most famous for Peak, their small side project which is now their main project after it sold 5 million copies. I have not tried Peak, but Another Crab’s Treasure was really good and is worth playing if you’re interested in a Souls-like. I’ve been told it’s easier than other Souls-likes, but I still found it tricky. What really carries it is the game’s humor and story. In between the typical Dark Souls story of a dying world are real character arcs and jabs against capitalism privatizing profits while socializing losses.
Chants of Sennar: A short language-based puzzle game themed after the Tower of Babel, where you need to learn how to translate between languages to help people communicate with each other and ascend the tower. I will always shill Return of the Obra Dinn, and this felt very like that game, complete with me doing some brute force to resolve a few words I just didn’t get. Would recommend.
Superliminal: I remember seeing the trailer for this game a long time ago, and people talking it up as a Portal-like first person puzzle game. This game…is not Portal. It’s really not. I mean, it’s alright, but I’m definitely glad I played it for free on Game Pass rather than buying it. A lot of the set pieces were just okay rather than exceptional, and there are only so many tricks to pull out of the perspective toolbox. Doesn’t overstay its welcome but also didn’t have a lasting impression on me.
Gris: A very pretty game with good music that’s lacking in gameplay. Don’t get me wrong, the gameplay exists, but the game is much more about absorbing the vibe of the world and solving some light traversal puzzles rather than overcoming some great challenge. The character you’re playing as is going through something, but that doesn’t mean you are. Another game I don’t regret playing but which I’m glad I played for free.
Powerwash Simulator: I tried it and just don’t get the appeal. It’s satisfying to slowly bring a scene from messy to clean, but I get equivalent joy with less monotony by solving logic puzzles.
Unpacking: In contrast, Unpacking is a banger. Behind the surface level gameplay is a really cool narrative experience of seeing the protagonist grow up, as viewed only through the items they keep, the items they throw away, and the places they move to. There is a moment shortly after the college level where most people go “ohhhhhhhh man”, and it’s conveyed through finding where to unpack stuff. Just super neat. Unfortunately, also quite short.
-
Brony Musicians Seize The Means of Production: My Eyewitness Account to BABSCon 2025
CommentsBronies are older fans of My Little Pony: Friendship is Magic. They are mostly male, typically in 20s-30s age wise, and have been trending older and more female over time. (A lot of girls in the original target demographic grew up, and a lot of men in the fandom realized they were trans.)
Brony conventions are cons for the MLP fandom. Most started in the peak hype of the early 2010s, but many cons from that era are now defunct. However, a few conventions still exist, thanks to a core diehard fan group that attends reliably enough to keep conventions sustainable. At their peak, thousands of people would go to each convention, but these days hundreds is more accurate.
BABSCon is one such convention. Short for Bay Area Brony Spectacular, it first ran in 2014, and quickly became one of the mainstays (manestays?) of the brony convention circuit. I went to my first BABSCon in 2016, and have attended most years since. They’ve been fun, but my interest has fallen over time. The panels have started to repeat, the vendors have had less new merch, and it’s all just gotten less novel each year. By BABSCon 2024, I had decided I wasn’t going to any future iterations, and left early to attend a board gaming event. I’d gotten my fill.
Checking the news afterwards, I learned that con staff announced they were ready to hang things up. Next year, BABSCon 2025, will be the final BABSCon.
I may have fallen out of the con scene, but of course I had to go.
Okay But What Do You Do At My Little Pony Conventions
MLP conventions follow a similar template.
- Panels, where official MLP voice actors and writers answer questions, or fans present a pony or pony-adjacent topic.
- Vendor halls and artist alleys, where people sell art prints and fan merch.
- Gaming rooms, where people play video games, board games, or the defunct MLP CCG.
- Parties run out of hotel suites, to socialize while drinking cheap booze.
- A music concert in the evenings, typically set up as a rave with EDM or rock music made by brony musicians.
I’ve been to many of these conventions as just an attendee. For the final BABSCon, I felt I should give back to the community that had brought so much entertainment over the years. So on a whim, I filled out a panel application titled “Ponies and Puzzles”. I pitched a two-part panel. The first would analyze the design of the puzzles that appear in-universe within My Little Pony. The second would be a solve-along of pony themed puzzles from puzzlehunts. I explained why I wanted to run the panel, cited academic talks as evidence of my public speaking experience, and linked Puzzles are Magic, the MLP-themed puzzlehunt I led the design for in 2020. This was all to convince BABSCon that I was literally the most puzzle-pilled MLP fan in the world. I thought competition to present at the final BABSCon would be high, and wanted to put forward my best shot.
My panel was accepted! Which left me the task of actually, uh, writing and preparing a 90 minute presentation. Still, wasn’t this what I signed up for? I procrastinate working on it, then start grinding through the slides in the weeks leading up to BABSCon.
Three weeks before the convention, I get an email from the events coordinator of BABSCon.
Hello,
If you are receiving this email then you were accepted to be a panelist at BABSCon 2025.
tl;dr I’m hosting open calls to talk about the schedule.
Panelists were expected to attend one of these calls to coordinate a desired panel time. In particular, if there were specific events we wanted to attend, they could make sure our panel wouldn’t conflict with the times of those events. Somehow, I’ve never realized this is how con scheduling works. When you present at academic conferences, they decide the time for you.
Assuming that time slots were first-come first-served, I joined the first call I could make, the Friday 4-6 PM call. I wasn’t free until the end of that slot, but luckily, the host was willing to stay until they got to everyone. The first thing I heard in the call was someone thanking the con for selecting their panel, because they normally only get to run it unofficially under a stairwell at night. So, we were already off to an interesting start.
As I wait for my turn, I keep working my slides. Before they get to me, the events coordinator has to take another call. Alright, no problem. We wait, and at 6:05 PM, they come back, saying they’re very sorry, but they’ll need to stop the panel call early. Annoying, but I get that event organizing can be hectic. I pencil in joining the Saturday time slot.
Saturday morning arrives. I check my email, and:
Hi all,
Thank you everyone that came yesterday, I found it very successful and have a much better grasp on panelist needs.
I regret to inform you that due to the ongoing situation I will need to cancel the schedule forum today.
I believe everyone involved tried to do what they thought was best and it is more than unfortunate this conflict came to head in the way it did, when it did.
We are moving forward with what we have, and despite the circumstances, compared to a week ago I am more confident in our ability to pull things off now than I was then. I will wait for an official statement to be decided before speaking on that further.
This in no way affects the evaluation of any panel and I likewise completely understand anyone who needs to cancel. Obviously there may be changes to the schedule in the next few days. I will plan to resume with forum calls on Sunday (tomorrow) and will send an earlier notification than this if the situation changes.
??????
Sorry, what?
I don’t read brony social media, so I have no idea what drama is going down. But it’s clear that something is going on, it’s escalated hard, and it’s hit the point where con staff assumes everyone obviously knows what the “ongoing situation” is. Except I don’t. So…what?
With some trepidation, I open the BABSCon Discord, and there is a fire, burning bright.
The Situation
I’ve decided not to name anyone besides Pinkaboo, the central figure of the story. The names are easy to find if you really need to know.
Pinkaboo was the music concert coordinator for BABSCon. She has been involved in organizing pony music concerts for over a decade, for both BABSCon and other pony conventions. Because of this, she is widely liked by the brony musician community, but not well known outside of them, due to playing more of a background logistics role.
On Friday 6:18 PM, the musicians get an email saying Pinkaboo was fired from BABSCon. (This is 13 minutes after the panel call was cut short, for those keeping track.) It’s possible some were told earlier, but I believe this email is the first time the musicians were officially told.
Hello everyone,
We wanted to inform you directly that the BABSCon Chairs have made the decision to reorganize responsibilities over the Neighhem concert. Moving forward, [name] will assume acting responsibility as Concert Lead, while we finish interviewing an individual to assume the role full time. Pinkaboo is no longer a member of BABSCon staff; her status as a musician remains unchanged.
To be clear, this decision does not impact the existing plans for Neighhem: The set schedule will remain as planned. Musician benefits will remain as previously agreed upon, including the gratis party suite rooms, which continue to be under Pinkaboo’s purview as private guest rooms.
Moving forward, for official convention business, we have created a channel for Concert’s exclusive use on the BABSCon server, [link]. We can also be reached via email at [email].
As we approach the finish line, we acknowledge Pinkaboo’s work building the strong foundation of Neighhem at BABSCon. This is a contribution which we will continue to recognize and acknowledge.
Thank you,
BABSCon Chairs
The brony musicians immediately jump into an emergency Discord call with Pinkaboo, to get her side of the story. They quickly decide the BABSCon Chairs are talking out of their ass, do not deserve their respect, and make a coordinated social media blast announcing they are all dropping out of the concert in protest.
It is 3 weeks before the last BABSCon, and one of the major evening activities no longer exists.
This continues blowing up the Discord into Saturday, and continues to boil when the con chairs directly reply to some angry messages while not putting out an official statement. This makes it hard to find exactly why Pinkaboo was fired. A rumor goes around that Pinkaboo was fired for sending a passive-aggressive tweet reply when BABSCon staff shared the wrong draft of a concert marketing video on social media. The only accounts of this are secondhand, and if said tweet ever existed, it was deleted before anyone could archive it.
On Saturday night, the BABSCon chairs put out their first official message.
I do want to apologize for the sudden news that broke yesterday, the ripples it sent throughout the community, and how it affected everyone who has planned on attending BABSCon. Our approach to this situation has been to remain respectful of all parties and refrain from divulging sensitive information; however, this approach has led to misunderstandings and understandable concerns from our staff, guests, and attendees. We would like to shed some clarity on a couple specific situations we have seen being discussed publicly, which are excellent examples of multiple perspectives:
In regards to the concerns with Marketing, we agree Pinkaboo was very engaged with the musicians’ unique marketing needs, and extensively pushed to have them promoted. It is important to recognize that Pinkaboo worked with us to pre-write and pre-approve all the musician announcement posts. Unfortunately when those marketing pushes did not go well, Marketing was blamed and bared the backlash. Then when Marketing didn’t respond fast enough, they were blamed again. This occurred multiple times.
In regards to Musician compensation, we hear reports of all the work Pinkaboo has done to take care of the musician community. One example was letting them stay in her suite so they do not need to pay for their own hotels. That suite, the connecting rooms, and several other rooms, are all paid by BABSCon as part of Concert’s budget. Those details of the budget Pinkaboo received, and how she chose to allocate it to the musicians she invited, seem to have been obfuscated from the musicians themselves. Do we wish we could pay more for the musicians? Absolutely! The costs to host the concert were already higher than all of the rest of our Panels, Events, Arcade, Tabletop, CCG, Cosplay, and Theatrics budgets all combined, and we worked to stretch it across 50+ musicians as much as we could. We are sorry the details of that were never clearly communicated to the musicians directly.
Internally to staff, there were multiple other situations where statements and allegations Pinkaboo made were, upon review, found to be false.
This leads to the core of the matter – the Chairs have repeatedly seen Pinkaboo twist the truth and serve as an unreliable narrator within our staff team. This issue only grew worse with time, and with three weeks until the convention, it had become an issue we could no longer work around. Part of operating as a team is being able to trust your teammates to accurately and truthfully present information. Pinkaboo lost that trust, and she was removed from staff.
This says a lot of things, while not clearing up anything. Saying Pinkaboo was an unreliable narrator without providing examples is like the OpenAI board saying Sam Altman was not consistently candid without specifying how. Sure, there’s some element of truth, but you have to give more than that. Similar to that situation, this statement doesn’t bring anyone to BABSCon’s side. It just makes people angrier.
My View
In general, I assume social media hate mobs aren’t fair to the people they’re hating on, especially with the rise of astroturfing. So here’s my most charitable interpretation of what happened.
In a bid to incentivize brony musicians to show up for the last BABSCon, Pinkaboo spent a lot of the budget allocated to her, and pushed BABSCon to give her more. These incentives were massively successful, because the concert lineup is stacked. Many musicians haven’t performed their music live in years, and half the lineup could be the headliner at an average brony concert. Making this happen was likely expensive, and I get the impression Pinkaboo had more of a begrudging relationship with BABSCon rather than one with constructive criticism.
On Friday, Pinkaboo messed up something. (In the BABSCon Discord, one staff member says Pinkaboo’s actions caused multiple weeks of delays, again without providing specifics.) In normal circumstances, this would be resolved internally, but leadership was sick of working with her. So they took the opportunity to snowball that mistake into an excuse to fire Pinkaboo, thinking they could massage the damage and remove a headache from their lives. This backfired horribly.
Now, as con chairs, they have the authority to fire anybody. No one says they can’t fire their concert head. Everyone’s saying it’s dumb they did. It’s the final BABSCon! If the con chairs are sick of working with Pinkaboo, is working 3 more weeks before never having to work with her again really so impossible? Just let her finish her job. If the concert goes wrong, you even get to blame her in the end, since it’s her responsibility. And if it goes well, you don’t have to air any dirty laundry. How is this so hard?
The musicians in particular are pissed off because they know who Pinkaboo is, have a working relationship with her, and are directly aware of the work she’s done to support them. Firing someone from the concert they’ve been planning for months, and then saying they can still perform in it if they want, is just a crazy level of tone-deafness over what these concerts mean to the bronies performing in them.
This is not lost on the general BABSCon public. In the end, it’s all people, but this feels a lot like a big company (BABSCon) firing a productive worker (Pinkaboo) the moment something goes wrong, ignoring their years of service to the company. And, like most terminally online fandoms, MLP fans are very leftist. They quickly support the strike.

I come out of everything agreeing with them. In a game of he said she said, what matters is reputation. Pinkaboo has it. The con does not.
Fallout
The standard practice for music artists is to sign written contracts with the cons they’re performing at. For example, Odyssey said she’s contractually obligated to play Discord at her sets, which - understandable. Before deciding to strike, the musicians reread their contracts. They argue that all the contracts are signed with Pinkaboo rather than BABSCon, so those contracts no longer apply after Pinkaboo’s firing.
BABSCon staff disagrees. They say any common sense interpretation is that the contracts are from Pinkaboo on behalf of BABSCon, rather than Pinkaboo individually. I take BABSCon’s side of this dispute, but they never pursue collecting on those contracts because it won’t fix their fundamental problem of losing all their music talent, and the legal system would be too slow.
Other conventions start tweeting in support of the brony musicians, with no one taking BABSCon’s side. (Even if you agreed with BABSCon, would you forever burn all musician goodwill to stand up for a con that’s about to end?)
Some start airing out dirty laundry from previous BABSCons, alleging the con has a history of mistreating talent. This barely changes my opinion. I assume all conventions have internal drama by default, because logistics is hell and hell is a pressure cooker. To make a convention happen, you must make fast decisions with imperfect info. Any longrunning convention will, eventually, ban an innocent person for sexual harassment. Or fail to screen a stalker for a visiting celebrity. Or some other disaster. There are always stories. I’m not surprised people have bad things to say about BABSCon, now that it’s publicly acceptable to dunk on them.
Con staff and the former BABSCon musicians enter negotiations, to see if there’s any way they can resolve the strike. The musicians’ give their conditions for performing again:
- Pinkaboo must be reinstated as concert head.
- BABSCon head of staff must step down.
BABSCon staff refuses. Now, in my opinion, firing your music lead 3 weeks before con is dumb. Firing your head of staff 3 weeks before con is just suicidal. As angry as the musicians are about the concert, they consistently tell fans to still attend BABSCon. Many are friends with artists in the community, who rely on con attendees for personal income. Everyone (everypony) still wants the rest of the convention to be great.
Unfortunately for me, the concert was close to the only thing I wanted to see at BABSCon. I was mildly into brony music pre-2020, and then fell deep, deep into the rabbit hole as a side effect of writing the puzzle Recommendations for Puzzles are Magic. It’s hard for me to explain why I like MLP fan music, because brony music really isn’t accessible. The scene has evolved from “haha mild remix of song from MLP episodes” to “metal song about Sweetiebot from the Friendship is Witchcraft AU that last updated 10 years ago”. That was one of the bigger songs of 2023. These days, an MLP song is likely to have minimal pony references, only implying a side story that happens to have ponies in it. Often it won’t have pony references at all, and the only connection is that the music artist has a pony OC.
The best explanation I have for how this all “works” is that if you’re a fan of My Little Pony, you automatically give some slack to music made by other fans of My Little Pony, because they clearly have good taste. Then the music recommendation algorithms hijack the existing fandom social fabric to introduce you to new artists. Pony musicians build off each other’s work in a small reference pool, which lets you feel like you’re part of the in-group. Pretty soon you’re radicalized into getting emotional over a song about a unicorn that rediscovers her love of music by whispering to fish. Now that’s a story about life.
Of the artists in the cancelled BABSCon 2025 lineup, the one I was most looking forward to was Vylet Pony. I was introduced to Vylet through 4everfreebrony’s cover of Little Dreams, then went down her discography from there. Out of her older work, I really like Overrun and The Magic Show, but by far her most famous song is ANTONYMPH. Its music video, a love letter to the Internet of the early 2010s, is a tour de force of nostalgia that kicked off its own subfandom. You’ll usually see at least one Fluttgirshy cosplay at any MLP convention.
I am partial to the lyra.horse version, an in-browser audiovisual experience made by a trans horse infosec researcher. Nothing about that sentence is surprising if you’ve spent enough time online, which I unfortunately have.
In the years since, Vylet Pony has amassed an eclectic diehard fanbase. Common themes in her work are “don’t be afraid to like what you like”, loving yourself, and examining trauma through an increasingly complex lore that I honestly don’t bother following. Her work is so unabashed of its inspirations that it circles to being endearing. There is no subtlety: everything is here and extra, for better or worse. In practice, this means I often really like half of a Vylet Pony song and then don’t like the other half, but it also means that when I find a song that hits on all cylinders, it hits very hard.
Vylet Pony also never performs at conventions, having last performed at the final BronyCon in 2019. She was one of the musicians most outspoken about how she only agreed to perform at BABSCon because she trusted Pinkaboo to keep everything together. I also suspected she only agreed to BABSCon because she grew up in the Bay Area, and wanted to revisit her hometown to reflect on how she’s changed. So I was assuming this was the one and only live Vylet Pony performance I’d get to see, and now it’s gone.
Well, maybe it’s gone.
Asgard Is Not A Place
All the brony musicians who were going to perform are still flying into the Bay Area for the BABSCon weekend. If everypony’s going to be in the same place at the same time, there’s no rule saying they can’t perform somewhere else.
On its face, moving a concert to a new venue in 3 weeks is insane. But ask yourselves: is this any more insane than BABSCon trying to replace all their music talent in 3 weeks against a hostile crowd? Not really, and the musicians are the ones with the means of production.
Real traction begins when 15 comes out of hibernation to offer a bunch of money to make a new concert happen.
I'll pay at least like $5,000 to help secure a new location for the concert if it's still happening (seriously), I was looking really forward to it 😔 https://t.co/1gisC5VE0E
— 15 🔜 TrotCon (@fifteenai) March 29, 2025A bit of lore: 15.ai is a free MLP voice generation site run by an anonymous AI researcher who goes by the name 15. They worked on voice generation before it was cool, and in my opinion, when the site launched in 2020, their model was arguably the highest quality voice generation model in the world. Like, better quality than the models trained by Google. 15 credited this to the very high quality annotations of MLP speech data by the Pony Preservation Project from 4chan. Running 15.ai was expensive, often costing thousands a month in GPU credits, but they never compromised on keeping the site free. This made them a celebrity in the fandom - “horse famous”, as it were. These days, AI voice generation is more serious and controversial, but multiple startups credit 15.ai for creating the market they now compete in. (See the 15.ai Wikipedia page if you want to learn more.)
15 is known for being reclusive, so breaking their silence for the BABSCon situation was a big, big deal. Over the weekend, the idea gained momentum, turning from idea to official project. Brony musicians began advertising the alternative concert in the BABSCon Discord, calling it “Pinkaboo’s Neighhem”. The name is not an accident. It is a proverbial middle finger to BABSCon, and a reclaiming of a name that the con no longer deserves.
This announcement sparks some infighting among BABSCon staff. The staff is not a unified front, with plenty of volunteers who disagree with how Pinkaboo was handled. Those volunteers respect the authority of the con chairs, but they aren’t happy about it. At the same time, Pinkaboo haters understand that Pinkaboo’s story is now woven into the story of BABSCon, and it cannot be silenced. They end up creating a #neighhem-planning containment channel, and ignore it the best they can.
Through a mix of outreach, GoFundMe, and a desire to make everything not be for nothing, Pinkaboo’s Neighhem reaches its funding goal and is officially opened for registration a few days later.
- It will be held on Sunday evening, at the Fox Theatre in downtown Redwood City. This is to avoid competing with the con, which is scheduled to end on Sunday afternoon.
- Neighhem will be free, even for people who didn’t register for BABSCon. Donations are welcome to help cover costs. A limited amount of concert merch will be on sale, along with a small artist alley.
- The music schedule will be heavily compressed, but most of the original lineup will still perform, including Vylet Pony.
- Thanks to sponsors, there will be free shuttle buses taking people from the BABSCon hotel to the Fox Theatre and back. (Important because public transit will stop running by the time the concert finishes.)
- Most importantly,
GO TO THE BUCKING CONCERT!

Meanwhile: What’s BABSCon Doing?
BABSCon chairs manage to pull together a new set of evening activities, headlined by a music set from Mystery Skulls. This is an impressive pickup, since Mystery Skulls is a “real” (professional) music artist. Their connection to brony fandom is due to owing a lot of their popularity to the Mystery Skulls Animated series by MysteryBen27, an animator from the early 2010s brony scene.
(If you haven’t seen it, Mystery Skulls Animated is good. It’s the kind of series that raises more questions than it answers, with smooth animation filled with details you only notice on your 3rd viewing, and it only takes 20 minutes to watch everything released so far. Go watch it!
As for how they got Mystery Skulls to agree on such short notice: Mystery Skulls was scheduled to perform at BABSCon 2020, before it was shut down due to COVID. So they already had a working relationship. In some ways, this is a make-up for the set they should have played 5 years ago.
Excited to announce I will be performing at @BABSCon
— Mystery Skulls (@MysterySkulls) February 19, 2020
this year!!
go to https://t.co/k5NeRt6wFc to get your badge! Use the code “SKULLS” and receive 15% off either a one day or three day badge! See you there ! !! ! #Mysteryskulls(Statements made before disaster)
Also, money. You can get higher talent if you only have to pay 1 person rather than 15-20. As someone connected to but outside of the fandom, Mystery Skulls isn’t seen as a strikebreaker in the way that a brony musician would be viewed. I mean, they are breaking the strike, but strikebreaking implies the strikers have any intention to come back. They don’t. So, whatever.
With this, people point out that against all odds, everyone’s gotten what they wanted. BABSCon doesn’t have to deal with Pinkaboo. The brony musicians don’t have to deal with BABSCon. If you wanted to see a concert, now you have two concerts. The official BABSCon concert (now called Burning Mare) is much shorter, and the slack in the schedule is used to shuffle many panels to larger rooms. My panel benefits from this - I get upgraded from a side room further away from the main hub to one of the three main panel rooms. There are still hard feelings, but the average con goer experience really did get better. The breakup is bad, but the divorce is clean.
With the drama resolved, I can stop doomscrolling the BABSCon Discord, and focus on what’s important: making my panel the best it can be, to play my part in making the con what it is.
BABSCon, One Last Time
When I arrive on con weekend, I ask if panelists get a special badge. They don’t, so I just pick up a regular badge and the official conbook. It may just be my imagination, but the page advertising Mystery Skulls feels like it is made of noticeably cheaper last-minute paper stock.
I immediately head to the con store, because I’m pretty confident they will run out if I wait. I leave with a BABSCon 2025 T-shirt and a coin from leftover BABSCon 2024 merch. My call is correct: the T-shirts sell out by the end of the first day.
There isn’t too much to comment on for the rest of the con. As I said, I’ve been to enough of these to know what to expect. When I walk into the vendor hall, I do a quick once over, confirm I’ve seen most of the vendors before, and spend my time admiring things rather than spending cash. I do end up buying prints from one of the MLP comics artists that’s attending BABSCon for the first and final time, and two tiny laser-burned wooden pony pieces that were 25 cents each from a gachapon. (I rolled Vinyl Scratch twice, unfortunate.)
There is a brief protest for Pinkaboo, but it is very brief. A bunch of people in fursuits carry a “We Support Pinkaboo!” flag, pose for a photo op, then disperse.

The food is overpriced, but the gaming area is fun. One of my favorite BABSCon memories from past years is playing 3 hours of Smash 64 against someone continuously salting about how bullshit Kirby is while wearing Trixie cosplay. Just, 10/10 no notes. Unfortunately, the gaming has shifted heavily to Smash Ultimate and Them’s Fightin’ Herds, neither of which I got very into.
The panels are fun. One is a livecast of a modded WWE game, changing all the wrestlers to look like MLP characters. Another goes through a leaked Hasbro document from early brony fandom, written to help internal employees get up to speed on the fandom. Now it unintentionally acts as a 2011 time capsule. They have a whole section for Steven Magnet. When’s the last time anyone’s thought about Steven Magnet? Or used this meme template?

When it’s time for my panel, I head over early for setup, unsure if con staff will be there to assist me. When I see no one there, I set it up myself. I’m a bit nervous, but as the panel starts I shift into “presenter mode” and the nerves go away. From my standpoint, the panel goes well. I have to live-debug fixing computer audio in the middle, but people are engaged the whole time, have terrifyingly good knowledge of MLP trivia, and ask good questions at the end. After my analysis of the two in-universe My Little Pony escape rooms (yes, there are two of them), I run a solve along of Bottom Lines from DP Puzzle Hunt, Power from Deusovi’s Zelda Minihunt, and Art of the Dress from Puzzles are Magic. We go a bit over time, but it’s 30 minutes until the next panel, so I end up livestreaming a group solve of the Cross Eyed crossword from Puzzles are Magic until we are kicked out. Hopefully I’ve converted at least one person to puzzlehunts.
With that, there is pretty much nothing left for me to do, besides going to room parties and waiting for Mystery Skulls. I stop by the British themed room party, where I meet a life-size cardboard cutout of King Charles, eat a bunch of snacks they’ve brought from the UK just for the bit, and chat with one of the organizers of PonyCon Holland. He is on a mission to convince people to travel to the EU pony circuit. I mention that I was just in London a few months ago, and he complains that visiting London only means I’ve been to London. It doesn’t mean I’ve been to Britain. I ask what would count as visiting Britain - he says “anywhere but London”.
We talk a bit about pony cons outside the US, and the recent explosion of the Chinese bronycon scene. I don’t follow the Chinese brony fandom, but I know My Little Pony is massive over there. It feels like China is 10 years behind the US’s hype cycle, and they are living through our 2015-2016 peak of MLP popularity. There are a ton of Chinese MLP conventions and most new merch these days is made for China first. I’m surprised there aren’t many resellers at the vendor hall. I figured at least one person would be trying to profit off them, but I guess the demand for non-English merch is just too low.
In the US, the massive growth of MLP was followed by a contraction where cons died off. Hopefully that doesn’t happen to the Chinese scene, but it’ll depend how much staying power MLP has over there. If Hello Kitty can be timeless, My Little Pony can too. I hope to see debates over 虹林檎 vs 稀有苹果 for years to come.
The final BABSCon wraps up with its charity auction, which I am quickly priced out of (the suspiciously wealthy furries continue to sweep the table). As closing ceremonies begin, a few people start boarding the Pinkaboo’s Neighhem shuttles. I am not enough of a pony music person to skip the literal final BABSCon closing ceremony, but it does have an odd sense of penultimateness to it. The real finale’s in Redwood City.
Pinkaboo’s Neighhem

To borrow a saying from the youth, the vibes are immaculate. The entire concert feels like one huge after party, complete with a custom drinks menu at the bar. According to the organizers, Pinkaboo’s Neighhem got over 1000 signups on their Eventbrite, compared to 2000 registrations for BABSCon. It’s unclear how many people actually showed up, but half the convention looks accurate to me. Pretty good turnout for a last minute unofficial event. Turns out you can just move a concert if everypony wants to make it happen.
The Mystery Skulls set at BABSCon was fun, but Neighhem is beating it in all dimensions. The venue is nicer. The concert setup is more elaborate, with a larger stage and more audiovisuals. The performer callouts are more specific to MLP fandom. It feels more like a pony rave rather than just a rave.
I stick around until the schedule gets to an act I’m less excited about, and leave to get dinner at Marufuku Ramen. (Another upside: being close to good food.) As I walk back to the venue, boba in hand, security stops me and tells me no outside drinks are allowed. So I drink my boba outside, suddenly feeling self-conscious about the MLP hoodie and jersey I’m still wearing. But this fades quickly when I remember that cringe is defeated by safety in numbers and not giving a shit.
When I wore my fursuit on my college campus for Halloween I had many peers who thought they were a spectator to the cringe show that I was, and they’d record me or look and talk about me from far away in their groups- unaware of how good my head’s visibility is. When I noticed someone recording or jeering, I waved and I posed, and they’d either immediately look away or act like it was not me they were recording. They didn’t realize the show was interactive! We have this kind of drive to cringe at and feel better than others, assuming they are static and detached from us, but in reality (especially as we see it now) the “other” might be starkly aware of you.
(Comment by @riff__rafferty, on The Brony Song That Makes Me Cry)
In the crowd outside, I spot someone who I remember giving a talk about MLP generative AI at a previous BABSCon. I walk up and say hi. In retrospect, I realize I did not introduce myself at all, and, oops, that must have come off as so awkward. We briefly talk about the state of rationalist AI discourse. It turns out you cannot escape rationalist discussion if you are in the Bay Area, even at a My Little Pony concert.
I go back into the concert area, picking up a poster since T-shirts in my size are sold out. By the end of the night, Neighhem will have sold literally all merch they made. I alternate between the dance floor area and the cool-down balcony on the top floor.

Midway through one of the sets, there’s a medical emergency, where someone dislocates their knee and can’t get back up. EMTs are on-site, and organizers stop the set to allow the medical professionals to attend to them. As far as I know, the person who fell was just clumsy and got too excited, but out of an abundance of caution the bar cuts off alcohol for the night. Which unfortunately means I never get to try the custom “Pinkaboo” or “Eurobeat Brony” cocktails.
Concert staff release balloons into the crowd, and for the next few hours, there is a minigame of “keep the balloon in the air”. People start leaving as the night continues, but I am committed to seeing the Vylet Pony and Odyssey sets, even if it wrecks my sleep schedule.

(Source)
At midnight, Vylet Pony takes the stage to much cheering. Her set doesn’t include anything from her newest album Monarch of Monsters, but I wasn’t expecting it to - it’s not a particularly good “dancing” album. Based on crowd reactions, it is very obvious that most people are here for ANTONYMPH, but I’m happy to recognize songs from Super Pony World, I Was The Loner of Paradise Valley, and Creature City, one of my favorite songs from 2024. Shelly the Android Lobster forever.
That leaves the final set of Odyssey. Like always, her stage presence is great, and the venue is still packed at 1 AM. When it gets to Luna and Discord, the crowd shouts out the lyrics, because yes, here everyone knows the lyrics. Part of me wonders how much Odyssey likes playing songs from over a decade ago, compared to her new work with way fewer views. But the old brony songs are the ones that pay the bills, cultural touchstones in a fandom that’s been buffeted and weathered but somehow never quite died. BABSCon is over for good, but pony fandom continues.
Coda
The BABSCon Discord is now mostly dormant, having turned into yet another MLP chatting Discord, but with a Bay Area lean.
The Pinkaboo Neighhem Discord also goes dormant, now functioning as another MLP music discussion space. Several months later, Pinkaboo announces that after paying musicians and staff their fees, Neighhem had $1500 left over, which was donated to the music program at New Horizon School, a school for students with learning disabilities.
The musicians go back from whence they came. Some are still active, while others have either stopped or work professionally under other aliases. A few months after BABSCon, Vylet Pony releases her new album, Love & Ponystep. To quote a review, it is “fearlessly cringe”, and I love it. Fan of “Peace, Love, Glalie”, “Wonka X Howl”, and “Falling in Love With a Corporate Illustration” so far.
Recently, as my blogging profile has grown, I’ve wondered how much time to spend on stories like these, rather than more “professional” ones. But when I started this blog, I did it to write for me, not for anyone else. Have I learned nothing from pony fandom? Screw it, this post is going up. The point of pointless stories is to tell them. It’s okay to do things for you, even and especially if they aren’t legible to others.
As for My Little Pony, the world continues to spin. There’s speculation that Hasbro will leverage their Chinese popularity to do a big marketing push for the Year of the Horse in 2026. And as of last week, Variety reports that a live-action MLP movie is in the works. No one is excited by this news. The track record of live-action reboots is really not good. But I remember when Friendship is Magic was written off as a trash cash-in cartoon before it started airing. Then people watched it, and now Twilight Sparkle is a cultural icon. I hope the movie’s good. For now, all there is to do is celebrate what we have and wait for what’s new.