The Dawn of Do What I Mean
Boy, last week was busy for deep learning. Let’s start with the paper I worked on.
SayCan is a robot learning system that we’ve been developing for about the past year. The paper is here, and it builds on a lot of past work we’ve done in conditional imitation learning and reinforcement learning.
Suppose you have a robot that can do some small tasks we tell it to do with natural language, like “pick up the apple” or “go to the trash can”. If you have these low-level tasks, you can chain them together into more complex tasks. If I want the robot to throw away the apple, I could say, “pick up the apple, then go to the trash can, then place it in the trash can”, and assuming those three low-level tasks are learned well, the robot will complete the full task.
Now, you wouldn’t want to actually say “pick up the apple, then go to the trash can, then place it in the trash can”. That’s a lengthy command to give. Instead, we’d like to just say “throw away the apple” and have the rest be done automatically. Well, in the past few years, large language models (LLMs) have shown they can do well at many problems, as long as you can describe the input and output with just language. And this problem of mapping “throw away the apple” to “pick / go to trash / place” fits that description exactly! With the right prompt, the language model can generate the sequence of low-level tasks to perform.
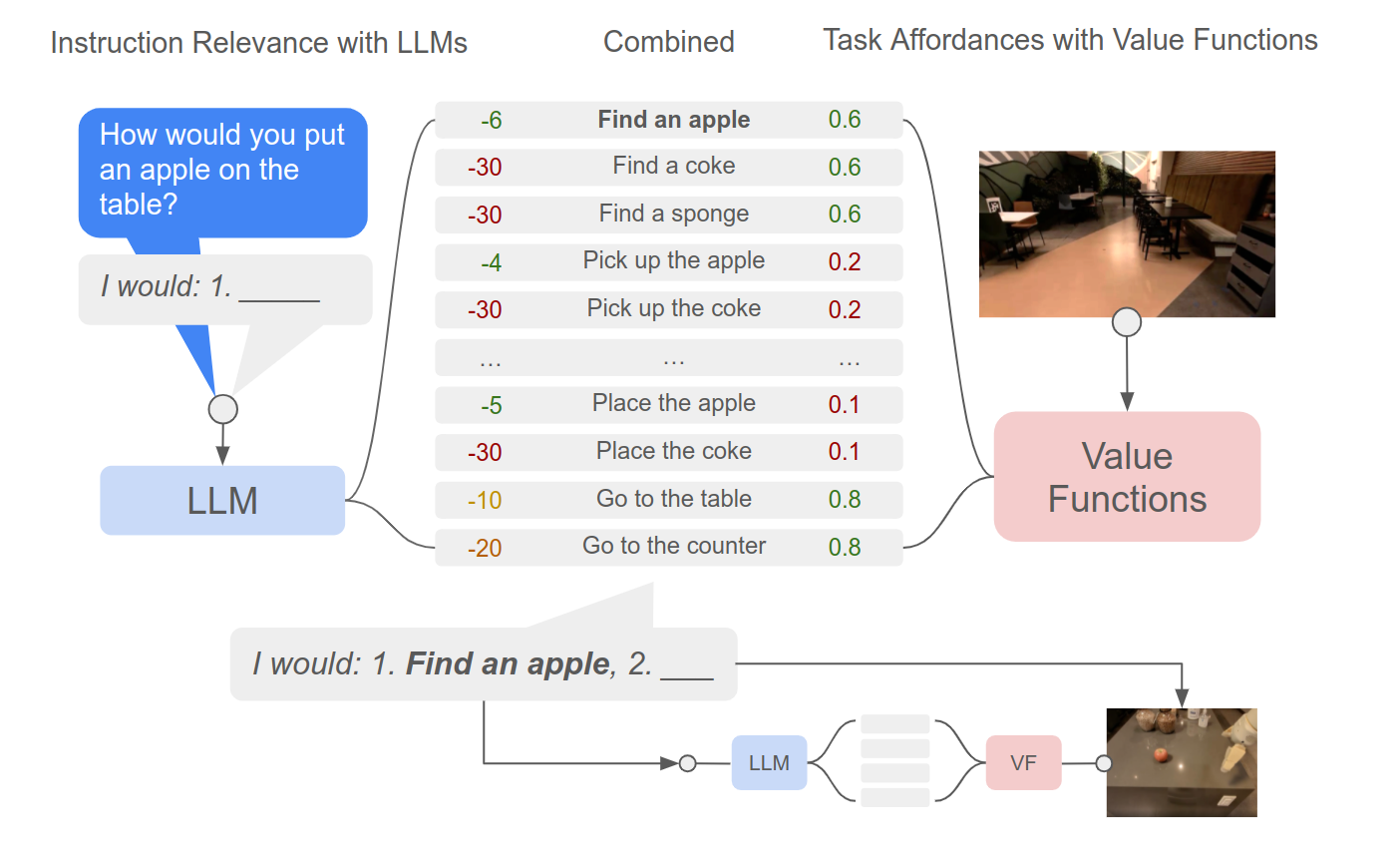
This, by itself, is not enough. Since the LLM is not aware of the robot’s surroundings or capabilities, using it naively may generate sentences the robot isn’t capable of performing. This is handled with a two-pronged approach.
- The language generation is constrained to the skills the robot can (currently) perform.
- Each generated instruction is scored based on a learned value function, which maps the image + language to the estimated probability the robot can complete the task.
You can view this as the LLM estimating the best-case probability an instruction helps the high-level goal, and the value function acting as a correction to that probability. They combine to pick a low-level task the robot can do that’s useful towards the high-level goal. We then repeat the process unless the task is solved.
This glosses over a lot of work on how to learn the value function, how to learn the policy for the primitive tasks, prompt engineering for the large language model, and more. If you want more details, feel free to read the paper! My main takeaway is that LLMs are pretty good. The language generation is the easy part, while the value function + policy are the hard parts. Even assuming that LLMs don’t get better, there is a lot of slack left for robot capabilities to get better and move towards robots that do what you mean.
* * *
LLMs are not the bottleneck in SayCan, but they’re still improving (which should be a surprise to no one). As explained in the GPT-3 paper, scaling trendlines showed room for at least 1 order of magnitude, and recent work suggests there may be more.
DeepMind put out a paper for their Chinchilla model. Through more careful investigation, they found that training corpus size had not increased in size relative to parameter count as much as it could have. By using about 4x more training data (300 billion tokens → 1.4 trillion tokens), they reduced model size by 4x (280B parameters → 70B parameters) while achieving better performance.
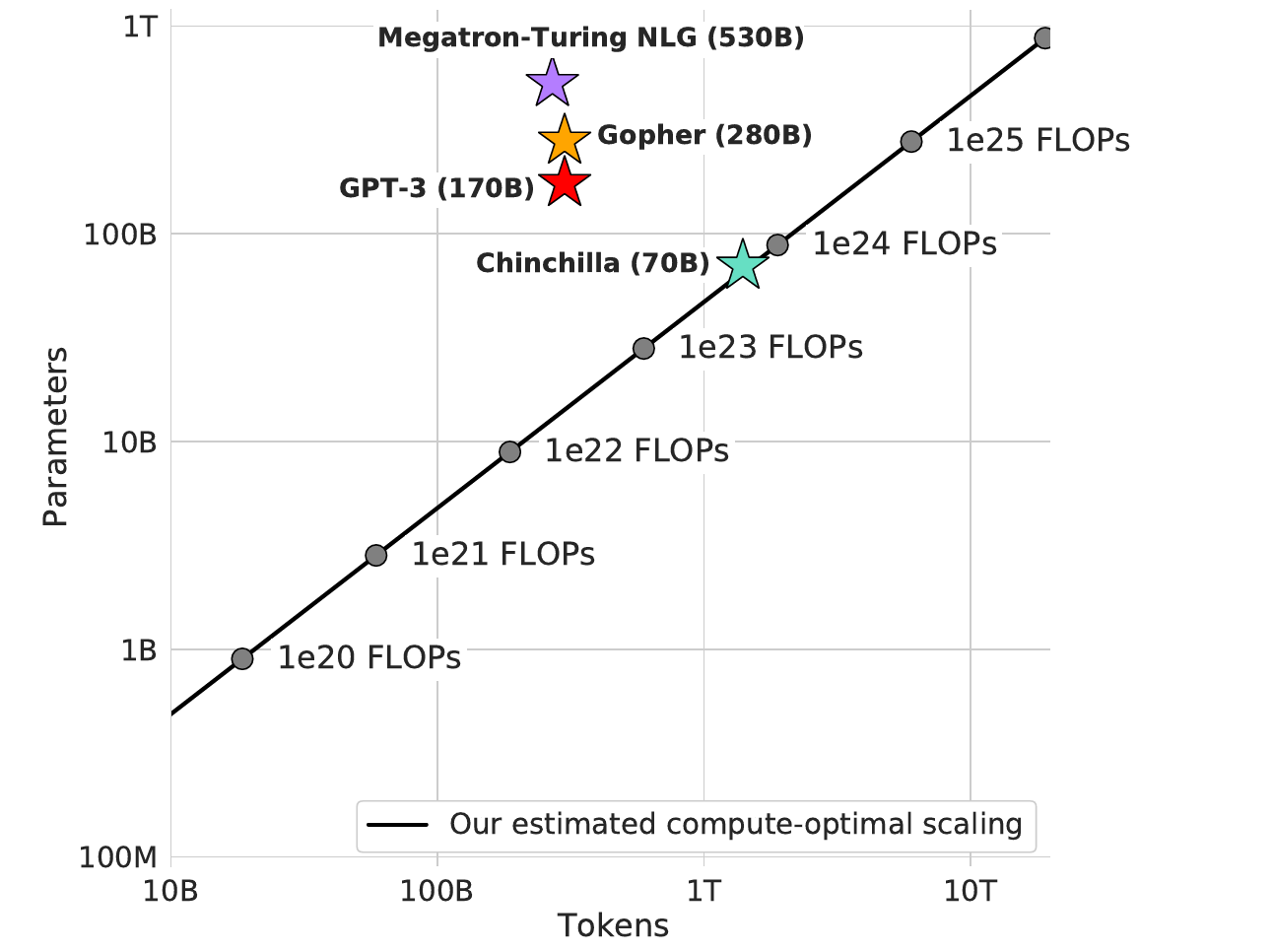
Estimated compute-optimal scaling, using larger datasets and fewer parameters than previous scaling laws predicted.
Meanwhile, Google Brain announced their PaLM language model, trained with 540B parameters on 780 billion tokens. That paper shows something similar to the GPT-2 → GPT-3 shift. Performance increases on many tasks that were already handled well, but on some tasks, there are discontinuous improvements, where the increase in scale leads to a larger increase in performance than predicted from small scale experiments.
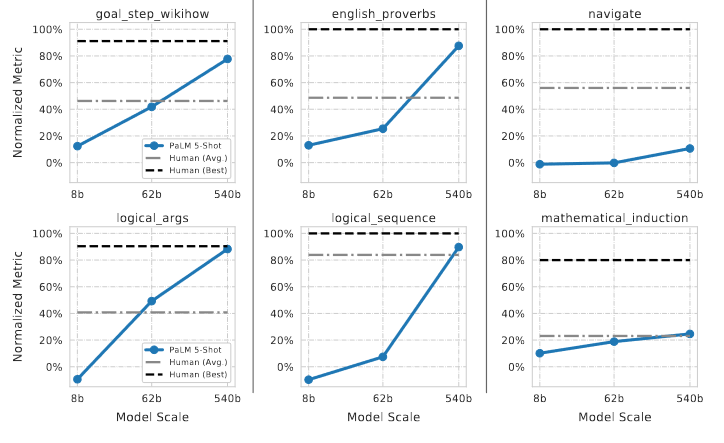
Above is Figure 5 of the PaLM paper. Each plot shows model performance on a set of tasks where PaLM’s performance vs model size is log-linear (left), “discontinuous” (middle), or relatively flat (right). I’m not even sure the flat examples are even that flat, they look slightly under log-linear at worst. Again, we can say that loss will go down as model size goes up, but the way that loss manifests in downstream tasks doesn’t necessarily follow the same relationship.
The emoji to movie and joke explanation results are especially interesting to me. They feel qualitatively better in a way that’s hard to describe, combining concepts with a higher level of complexity than I expect.

Neither of these works have taken the full 1 order of magnitude suggested by prior
work, and neither indicates we’ve hit a ceiling on model scaling. As far as I know, no one is willing to
predict whether or what qualitatively new capabilities we’ll see from the next large language model. This is worth
emphasizing - people genuinely don’t know. Before seeing the results of the PaLM paper, I think you could argue that
language models would have more trouble learning math-based tasks, and the results corroborate this (both navigate and
mathematical_induction from the figure above are math-based). You could also have predicted that
at least one benchmark would get qualitatively better. I don’t see how you could have predicted
that english_proverbs and logical_sequence in particular would improve
faster than their power low curve.
The blog post for the Chinchilla model notes that given the PaLM compute budget, they expect you could match it with 140B params if you used a dataset of 3 trillion tokens of language. In other words, there’s room for improvement without changing the model architecture, as long as you crawl more training data. I don’t know how hard that is, but it has far less research uncertainty than anything from the ML side.
Let’s just say it’s not a good look for anyone claiming deep learning models are plateauing.
* * *
That takes us to DALL·E 2.

On one hand, image generation is something that naturally captures the imagination. You don’t have to explain why it’s cool, it’s just obviously cool. Similar to language generation, progress here might overstate the state of the field, because it’s improving things we naturally find interesting. And yet, I find it hard to say this doesn’t portend something.
From a purely research standpoint, I was a bit out of the loop on what was state-of-the-art in image generation, and I didn’t realize diffusion based image synthesis was outperforming autoregressive image synthesis. Very crudely, the difference between the two is that diffusion gradually updates the entire image towards a desired target, while autoregressive generation draws each image patch in sequence. Empirically, diffusion has been working better, and some colleagues told me that it’s because diffusion better handles the high-dimensional space of image generation. That seems reasonable to me, but, look, we’re in the land of deep learning. Everything is high-dimensional. Are we going to claim that language is not a high-D problem? If diffusion models are inherently better in that regime, then diffusion models should be taking over more of the research landscape.
Well, maybe they are. I’ve been messing around with Codex a bit, and would describe it as “occasionally amazing, often frustrating”. It’s great when it’s correct and annoying when it’s not. Almost-correct language is amusing. Almost-correct code is just wrong, and I found it annoying to continually delete bad completions when trying to coax the model to generate better ones. There was a recent announcement of improving Codex to edit and insert text, instead of just completing it. It’s better UX for sure, and in hindsight, it’s likely using the same core technology DALL-E uses for image editing.

We’re taking an image and dropping a sofa in it, or we’re taking some text and changing the sentence structure. It’s the same high level problem, and maybe it’s doing diffusion-based generation under the hood.
* * *
Where does this leave us?
In general, there is a lot of hype and excitement about models with a natural language API. There is a building consensus that text is a rich enough input space to describe our intentions towards ML models. It may not be the only input space, but it’s hard to see anything ignoring it. If you believe the thesis that language unlocked humanity’s ability to share complex ideas in short amounts of time, then computers learning what to do based on language should be viewed as a similar sea change in how we interact with ML models.
It feels like we are heading for a future where more computer systems are “do what I mean”, where we hand more agency to models that we believe have earned the right to that agency. And we’ll do so as long as we can convince ourselves that we understand how these systems work.
I don’t think anyone actually understands how these systems work. All the model disclosure analysis I’ve read feels like it’s poking the outside of the model and cataloging how the black box responds, without any generalizable lesson aside from “consider things carefully”. Sure, that’s fine for now, but that approach gets harder when your model is capable of more things. I hope people are paying attention.