Posts
-
The Argument for Contact Tracing
CommentsA few days ago, Apple and Google announced a partnership to develop an opt-in iOS and Android contact tracing app. Apple’s announcement is here, and Google’s announcement is here.
I felt it was one of the biggest signs of optimism for both ending stay-at-home orders and maintaining control over COVID-19, assuming that people opt into it.
I also quickly realized that a bunch of people weren’t going to opt into it. Here’s my attempt to fix that.
This post covers what contact tracing is, why I believe it’s critical to handling COVID-19, and how the proposed app implements it while maintaining privacy, ensuring that neither people, nor corporations, nor governments learn personal information they don’t need to know.
As a disclaimer, I do currently work at Google, but I have no connection to the people working on this, I’m speaking in a personal capacity, and I’ve deliberately avoided looking at anything besides the public press releases.
What Is Contact Tracing?
Contact tracing is the way we trace who infected people have been in contact with. This is something that hospitals already do when a patient gets a positive test for COVID-19. The aim of contact tracing is to warn people who may be infected and asymptomatic to stay home. This cuts lines of disease transmission, slowing down the spread of the disease.
Much of this is done by hand, and would continue to be done by hand, even if contact tracing apps become widespread. Contact tracing apps are meant to help existing efforts, not replace them.
Why Is Contact Tracing So Necessary?
Stay-at-home orders are working. Curves for states that issued stay-at-home orders earlier are flatter. This is all great news.
However, the stay-at-home orders have also caused tons of economic damage. Now, to be clear, the economic damage without stay-at-home orders would have been worse. Corporate leaders and Republicans may have talked about lifting stay-at-home orders, but as relayed by Justin Wolfers, UMich Economics professor, a survey of over 40 leading economists found 0% of them agreed that lifting severe lockdowns early would decrease total economic damage.
Survey of leading economists:
— Justin Wolfers (@JustinWolfers) March 29, 2020
"Abandoning severe lockdowns at a time when the likelihood of a resurgence in infections remains high will lead to greater total economic damage than sustaining the lockdowns to eliminate the resurgence risk."
0% disagree.https://t.co/6NNAaLlSjq pic.twitter.com/7kcnVVPw2NUnderstand the incentives: CEO's and bankers are calling for workers to be recalled. Economists—whose models also account for what's in the workers' best interests—disagree. Epidemiologists—who understand how pandemics spread—also disagree.
— Justin Wolfers (@JustinWolfers) March 29, 2020So, lockdowns are going to continue until there’s low risk of the disease resurging. As summarized by this Vox article, there are four endgames for this.
- Social distancing continues until cases literally go to 0, and the disease is eradicated.
- Social distancing continues until a vaccine is developed, widely distributed, and enough of the population gets it to give herd immunity.
- Social distancing continues until cases drop to a small number, and massive testing infrastructure is in place. Think millions of tests per day, enough to test literally the entire country, repeatedly, to track the course of the disease.
- Social distancing continues until cases drop to a small number, and widespread contact tracing, plus a large, less massive number of tests are in place.
Eradication is incredibly unlikely, since the disease broke containment. Vaccines aren’t going to be widely available for about a year, because of clinical trial timelines. For testing, scaling up production and logistics is underway right now, but reaching millions of tests per day sounds hard enough that I don’t think the US can do it.
That’s where contact tracing comes in. With good contact tracing, you need fewer tests to get a good picture of where the disease is. Additionally, digital solutions can exploit what made software take over the world: once it’s ready, an app can be easily distributed to millions of people in very little time.
Vaccine development, test production, and contact tracing apps will all be done in parallel, but given the United States already has testing shortfalls, I expect contact tracing to finish first, meaning it’s the best hope for restarting the economy.
What About Privacy?
Ever since the Patriot Act, people have been wary of governments using crises as an excuse to extend their powers, and ever since 2016, people have been wary of big tech companies. So it’s understandable that people are sounding alarm bells over a collaboration between Apple, Google, and the government.
However, if you actually read the proposal for the contact tracing app, you find that
- The privacy loss is fairly minimal.
- The attacks on privacy you can execute are potentially annoying, but not catastrophic.
When you contrast this with people literally dying, the privacy loss is negligible in comparison.
Let’s start with a privacy loss that isn’t okay, to clarify the line. In South Korea, the government published personal information for COVID-19 patients. This included where they traveled, their gender, and their rough age. All this information is broadcasted to everyone in the area. See this piece from The Atlantic, or this article from Nature, for more information.
Exposing this level of personal detail is entirely unnecessary. There is no change in health outcome between knowing you were near an infected person, and knowing you were near an infected person of a certain age and gender. In either case, you should self-quarantine. The South Korea model makes people lose privacy for zero gain.
How does the Apple and Google collaboration differ? Here is the diagram from Google’s announcement.
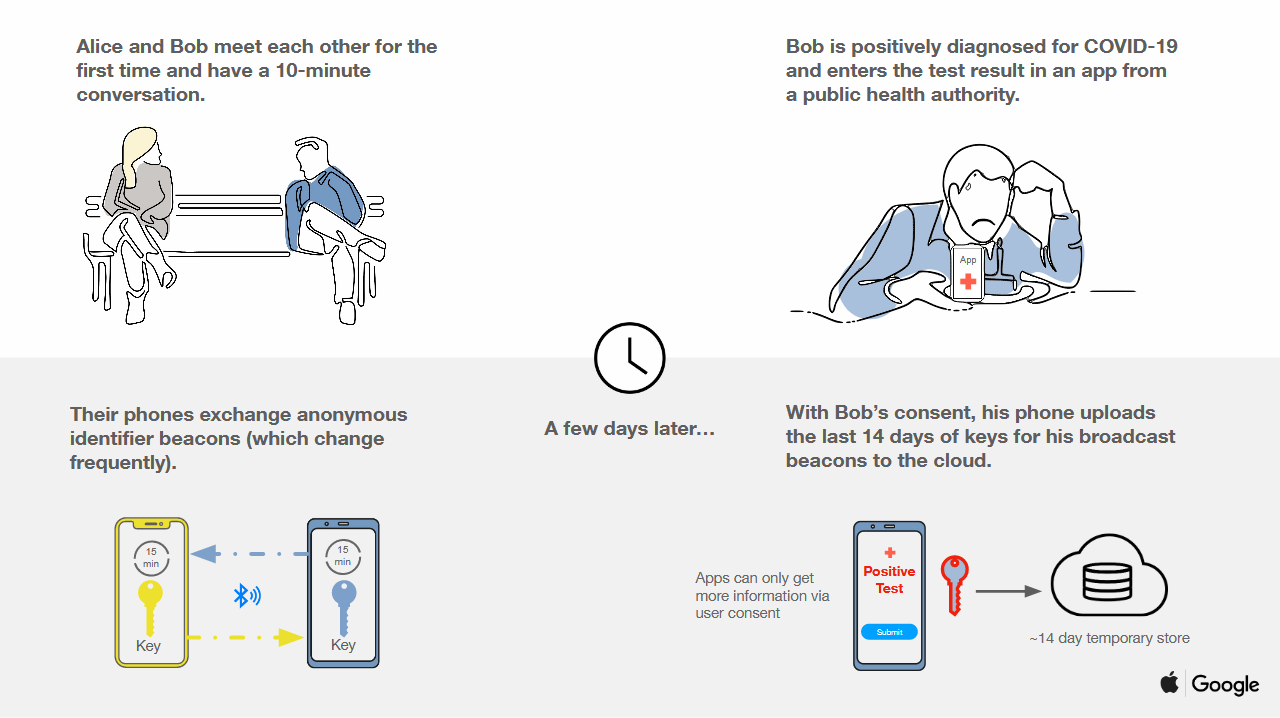
This is similar to the DP-3T protocol, which is briefly explained in this comic by Nicky Case.

- Each phone continually generates random keys, that are broadcasted by Bluetooth to all nearby devices. These keys change every 5-15 minutes.
- Each device records the random messages it has heard from nearby devices.
- Whenever someone tests positive, they can elect to upload all their messages to a database. This upload requires the consent of both the user and a public health official.
- Apple’s and Google’s servers store a list of all messages sent by COVID-19 patients. They will be stored for 14 days, the incubation period of the virus.
- Periodically, every device will download the current database. It will then, on-device, compare that list to a locally saved list of messages received from nearby phones.
- If there is enough overlap, the user gets a message saying they were recently in contact with a COVID-19 case.
What makes this secure? Since each phone’s message is random, and changes frequently, the messages on each phone don’t indicate anything about who those messages correspond to. Since the database is a pile of random messages, there’s no way to extract further information from the stored database, like age, gender, or street address. That protects people’s privacy from both users and the database’s owner.
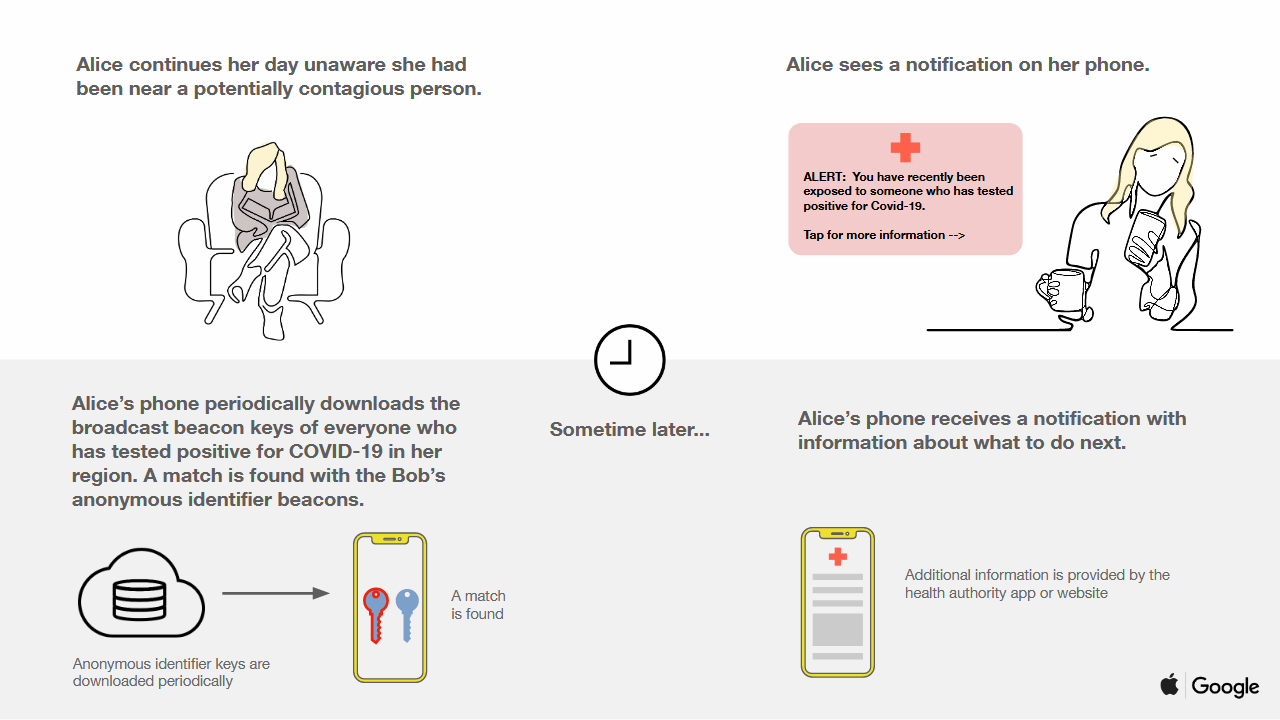
The protocol minimizes privacy loss, but it does expose some information, since doing so is required to make contact tracing work. Suppose Alice only meets with Bob in a 14 day period. She later gets a notification that someone she interacted with tested positive for COVID-19. Given that Alice only met one person, it’s rather obvious that Alice can conclude Bob has COVID-19. However, in this scenario, Alice would be able to conclude this no matter how contact tracing is implemented. You can view this as a required information leak, and the aim of the protocol is to leak no more than the required amount. If Alice meets 10 people, then gets a notification, all she learns is that one of the 10 people she met is COVID-19 positive - which, again, is something that she could have concluded anyways.
If implemented as stated, neither the hospital, nor Apple, nor Google should learn who’s been meeting who, and the users getting the notification shouldn’t learn who transmitted the disease to them.
What If Apple and Google Do Something Sketchy?
First, the simpler, less technical answer. So far, Apple and Google have publicized and announced their protocol ahead of time. Their press releases include a Bluetooth specification, a cryptography specification, and the API that both iOS and Android will support. This is standard practice if you want to do security right, because it lets external people audit the security. It also acts as an implicit contract - if they deviate from the spec, the Internet will bring down a firestorm of angry messages and broken trust. If you can count on anyone to do due diligence, it’s the cryptography nerds.
In short, if this was a sneaky power grab, they’re sure making it hard to be sneaky by readily giving out so much information.
Maybe there’s a backdoor in the protocol. I think that’s very unlikely. Remember, it’s basically the DP-3T protocol, which was designed entirely by academic security professors, not big tech companies. I haven’t had the time to verify they’re exactly identical, but on a skim they had the same security guarantees.
When people explain what could go wrong, they point out that although the app is opt-in, governments could keep people in lockdown unless they install the app, effectively making it mandatory. Do we really want big tech companies building such a wide-reaching system?
My answer is yes, absolutely, and if governments push for mandatory installs, then that’s fine too, as long as the app’s security isn’t compromised.
Look, you may be philosophically against large corporations accumulating power. I get it. Corporations have screwed over a lot of people. However, I don’t think contact tracing gives them much power they didn’t already have. And right now, the coronavirus is also screwing over a lot of people. It’s correct to temporarily suspend your principles, until the public health emergency is over. Contact tracing only works if it’s widespread. To make it widespread, you want the large reach of tech companies, because you need as many users as possible. (Similarly, you may hate Big Pharma, but Big Pharma is partnering with the CDC for COVID-19 test production, and at this time, they’re best equipped to produce the massive numbers of tests needed to detect COVID-19.)
NOVID is an existing contact tracing app, with similar privacy goals. It got a lot of traction in the math contest community, because it’s led by Po-Shen Loh. I thought NOVID was a great effort that got the ball rolling, but I never expected it to have any shot of reaching outside the math contest community. Its footprint is too small. Meanwhile, everyone knows who Apple and Google are. It’s much more likely they’ll get the adoption needed to make contact tracing effective. Both companies also have medical technology divisions, meaning they should have the knowledge to satisfy health regulations, and the connections to train public health authorities on how to use the app. These are all fixed costs, and the central lesson of fixed costs is that they’re easier to absorb when you have a large war chest.
Basically, if you want contact tracing to exist, but don’t want Apple or Google making it, then who do you want? The network effects and political leverage they have makes them most able to rapidly spread contact tracing. I’m not very optimistic about a decentralized solution, because (spoiler for next section) that opens you up to other issues. For a centralized solution, the only larger actor is the government, and if you don’t trust Apple or Google, you shouldn’t trust the government either.
Frankly, if you were worried about privacy, both companies have plenty of easier avenues to get personal information, and based on the Snowden leaks, the US government knows this. I do think there’s some risk that governments will pressure Apple and Google to compromise the security for surveillance reasons, but I believe big tech companies have enough sway to avoid compromising to governmental pressure, and will choose to do so if pushed.
What If Other Actors Do Something Sketchy on Top of Apple and Google’s Platform?
These are the most serious criticisms. I’ll defer to Moxie Marlinspike’s first reaction, because he created Signal, and has way more experience on how to break things.
These contact tracing apps all use Bluetooth, to enable nearby communication. A bunch of people who wouldn’t normally use Bluetooth are going to have it on. This opens them up to Bluetooth-based invasions of privacy. For example, a tracking company can place Bluetooth beacons in a hotspot of human activity. Each beacon registers the devices of people who walk past it. One beacon by itself doesn’t give much, but if you place enough of these beacons and aggregate their pings, you can start triangulating movements. In fact, if you do a search for “Bluetooth beacon”, one of the first results is a page from a marketing company explaining why advertisers should use Bluetooth beacons to run location-based ad campaigns. Meaning, these campaigns are happening already, and now those ads will work for a bunch more people.
Furthermore, it’s a pretty small leap to assume that advertisers will also install the contact tracing app to their devices. They’ll place them in a similar way to existing Bluetooth beacons, and bam, now they also know the rough frequency of COVID-19 contacts in a given area.
My feeling is that like before, these attacks could be executed on any contact tracing app. For contact tracing to be widespread, it needs to be silent, automatic, and work on existing hardware. That pretty much leaves Bluetooth, as far as I know, which makes these coordinated Bluetooth attacks possible. And once again, compared to stopping the start of another exponential growth in loss of life, I think this is acceptable.
Moxie notes that he expects location data to be incorporated at some point. If the app works as described, each day, the device needs to download the entire database, whose size depends on the number of new cases that day. At large scale, this could become 100s of MBs of downloads each day. To decrease download size, you’d want each phone to only download messages uploaded from a limited set of devices that includes all nearby devices…which is basically just location data, with extra steps.
I disagree that you’d need to do that. People already download MBs worth of data for YouTube, Netflix, and updates for their existing apps. If each device only downloads data when it’s on Wi-Fi and plugged in, then it should be okay. I’d also think that people would be highly motivated to start those downloads
- without them, they don’t learn if they were close to anyone with COVID-19!
If users upload massive amounts of keys, they could trigger DDOS attacks by forcing gigabytes of downloads to all users. If users declare they are COVID-19 positive when they aren’t, they could spread fake information through the contact tracing app. However, both of these should be unlikely, because uploads will require the sign-off of a doctor or public health authority.
This is why I’m not so optimistic about a decentralized alternative. To prevent abuse, you want a central authority. The natural choice for a central authority is the healthcare system. You’ll need hospitals to understand your contact tracing app, and that’s easiest if there’s a single app, rather than several…and now we’re back where we started.
Summary
Here are the takeaways.
Contact tracing is a key part to bringing things back to normal as fast as is safe, which is important for restarting the economy.
Of the existing contact tracing solutions, the collaboration between Apple and Google is currently the one I expect to get the largest adoption. They have the leverage, they have the network effects, and they have the brand name recognition to make it work.
For that solution, I expect that, while there will be some privacy loss, it’ll be close to the minimum amount of privacy loss required to make widespread contact tracing work - and that privacy loss is small, compared to what it prevents. And so far, they seem to be operating in good faith, with a public specification of what they plan to implement, which closely matches the academic consensus.
If contact tracing doesn’t happen - if it doesn’t get enough adoption, if people are too scared to use it, or something else, then given the current US response, I could see the worst forecasts of the Imperial College London report coming true: cycles of lockdown on, lockdown off, until a vaccine is ready. Their models are pessimistic, compared to other models, but it could happen. And I will be really, really, really mad if it does happen, because it will have been entirely preventable.
I originally posted this essay on Facebook, and got a lot of good feedback. Thanks to the six people who commented on points I missed.
-
Spring Cleaning
CommentsWhen I was growing up, I saved every bit of schoolwork I ever made. I did this because my parents told me too. I’m guessing they wanted to have the memories. Every worksheet and notebook sat in a cardboard box, under our dinner table, a time capsule starting from kindergarten.
Well, it was the summer after 7th grade, and those boxes were full. My parents wanted to clean the house, so my mom dumped a pile of old toys I played with, and told me to figure out what I wanted to keep, and what I didn’t. After that, I was to do the same with my old schoolwork.
What neither of us knew was that my dad had already taken the box (my box) of schoolwork, and had thrown the whole thing away, box and all.
Was I upset? Well, yeah! I’m sure a lot of embarrassing, adorable stuff was in there. But, I wasn’t upset enough to dig it out of a dumpster, so I let it go. That day, I made a resolution: I would never throw out my schoolwork again. Not until I got a chance to look through it first.
I kept this up all the way through college, and today, I decided to mine through all my undergraduate work, to see what gold I could find.
It turned out my dad had the right idea after all. I wanted almost none of it! It’s funny, at the time it all seemed to matter so much. After a few years, it just doesn’t.
The bulk of it is answers to homework questions. I threw out all of that, because they all refer to questions from textbooks I no longer own. I sold most of my textbooks every year, in a bid to stop the textbook bureaucracy from extracting more money from students.
The stuff that isn’t homework is primarily notes from my computer science courses. That’s to be expected, it’s what I majored in. There, the problem is that much it is far, far too similar to my day-to-day work. I don’t need my old notes on Python and data structures, when I have to deal with that every day. Freaking tech jobs. If I have to use one more hash table, I’m going to flip out. (Just kidding, hash tables are the one true data structure. If you disagree, you have yet to see the light.)
In a weird twist of fate, much of what I decided to keep was actually from the courses I liked the least at the time. The humanities class about movie stars in the 1950s and 1960s, which I found terribly boring. The operating systems course, where I liked the overarching concepts, and hated the details. The music course about music’s intertwining evolution with American culture, which…okay, actually, I liked that class, but I haven’t felt any urge to review it. I don’t like those courses any more than I did then, but they were different, and I respect that.
As for the courses I liked, I’m keeping those notes too, but wow, I remember so little of what I learned. For example, I took a course on formal logic, where we proved that proofs work. My notes are all Greek to me, literally and figuratively. (Logic uses a lot of symbols.) Meanwhile, I don’t remember Poisson distributions as well as I should, considering how much time we spent on them in probability theory. And although I can tell you what an SVM does, I had forgotten the exact way you structure the optimization such that its solution maximizes the margin. I could re-learn some of this quickly if I needed to, but the key point is that I haven’t needed to.
If that’s true, what was the point of doing it?
I took those courses because I wanted to. That worked for me, and I had the luxury to afford it, but it makes me realize how much of college must be wasted time for the people who just care about getting a high paying job. You could argue college teaches general skills around work ethic, socializing, time management, networking, and so on, but shouldn’t teaching those skills be high school’s job?
The argument that rings true for me is that most people’s college experience is like mine, where only small parts matter, but it isn’t clear what parts matter for you until after you finish undergrad.
Despite forgetting a lot of what I learned, I do feel that time was when I was most “alive”. I had more varied interests, was generally more curious about the world, and went through a lot of personal growth. It’s made me realize how much I miss having 100% freedom to do whatever I wanted, without having to worry about money or career aspirations. Now, there are heavy incentives to find my lane, so to speak. It can drift, but large shifts come at large costs.
It also reminded me that once upon a time, I genuinely thought “It’s all ogre now” was an incredible meme. I liked it so much that I wrote it on the cheat sheet for my machine learning final. Well, we’ve all got things we regret. Luckily, I’ve moved on to much better memes, like “Call Me Maybe” + “X Gon’ Give It To Ya” mashups. Four years from now, I bet I’ll still like that song.
-
A Puzzlehunt Tech Checklist
CommentsLast updated March 29, 2020
I have played my fair share of online puzzlehunts, and after helping run Puzzles are Magic, I’ve learned a lot of things about what makes a good hunt.
There are several articles about puzzle design, but as the tech person for Puzzles are Magic, I haven’t seen any articles about building a hunt website. I suspect that everyone builds their setup from intuition. That intuition is usually correct, I’ve yet to see an entirely broken tech set-up, but there are a lot of details to keep track of.
This is a list of those details. My aim is to be extensive about the lessons I learned when building the Puzzles are Magic site.
If you are reading this, I’m assuming that you know what puzzlehunts are, you’ve done a few puzzlehunts yourself, and are either interested in running an online puzzlehunt, or are just curious what the tech looks like.
(Fair warning: I’ll be making a lot of references to Puzzles are Magic, as well as other puzzles, and there will be minor spoilers.)
Hunts are Web Apps
The most important thing to remember about a puzzlehunt is that a puzzlehunt is essentially a full web application. There’s a front-end that solvers interact with, there’s a back-end that stores submission and solve info, and the two need to send the right information to each other for your hunt to work.
If you want to run an online puzzlehunt with teams, a public facing leaderboard, and so on, you’ll need to know how to set up a website. Or, you’ll need to be eager to learn.
If you don’t know how to program, and can’t enlist the help of someone who can, then your job will get a lot harder, but it won’t be impossible. If worst comes to worst, you can always just release a bunch of PDFs online, and ask people to email you if they want to check answers. The PI HUNT I worked on this weekend followed this model, and I still had fun.
The standard rules of software development apply, and the most important one is this: you don’t have to do everything! You’re going to run out of time for some things. That’s always how it goes. Keep your priorities in order, and do your best.
Using Existing Code
If you are planning to make minor changes on top of someone else’s hunt code, think again.
Puzzlehunt coding is like video game coding. It starts sane and well-designed, and becomes increasingly hacky closer to the hunt deadline. This is especially true if the hunt has interactive puzzles or is trying to do something new with its puzzle structure. In the end, functionality matters more than code quality, and since hunts are one-time events, there usually isn’t much incentive to invest in clean code.
Additionally, much of the work for a puzzlehunt is about styling the puzzles and site to fit what you want, and that’s work you have to do yourself, no matter what code base you use.
As far as I know, the only open-source puzzlehunt code base is Puzzlehunt CMU’s codebase, which can be found at this GitHub. Expect most other people to be hesitant about sharing their hunt code. Or at least, I’m hesitant to share the Puzzles are Magic code. I’m happy with the core, but there are a ton of hardcoded puzzle IDs and other things to make the hunt work as intended. I’ve considered releasing the code as-is, warts and all, but even then I’d need to audit the code to verify I’m not leaking any hardcoded passwords, secret keys, user data, puzzle ideas I want to use again, and so on.
The Puzzles are Magic code is forked from the Puzzlehunt CMU code, with several modifications. It’s written in Django, and served using Apache. Both libraries are free and very well tested, so they’re solid picks.
Authentication
You will need to decide whether you want logins to be person-based, or team-based.
In a person-based setup, each person makes their own account. People can create teams, or join existing teams by entering that team’s randomly generated hunt code. Puzzlehunt CMU’s code does this, as did Microsoft College Puzzle Challenge. The pro is that you get much more accurate estimates of how many participants you have. Both Puzzlehunt CMU and Microsoft CPC are on-campus events where the organizers provide free food, and they need to know how much food to order.
The con is that by requiring every solver to make an account, you increase friction at registration time. Everyone on a team must make an account to participate, and anyone the team wants to recruit during hunt must do the same. Also, some people are generally wary of entering emails and passwords into an unfamiliar website.
In a team-based setup, each team has a single account. There is a shared username and password, chosen by the person who creates the team, and their email is the main point of contact. They share the team’s login credentials around, and team members can optionally add their names and emails on that team’s profile page. This is the setup used by MIT Mystery Hunt, Galactic Puzzle Hunt, and Puzzles are Magic.
Puzzles are Magic went with team-based logins because our main goal was getting as many people as possible to try our puzzles. That meant reducing sign-up friction as much as we could, and redirecting all logins to the puzzle page to get solvers to puzzles as fast as possible.
The downside of team-based logins is that your participant counts will be off. In our post-hunt survey, we asked about team size, and based on those replies, we think only 50-75% of people who played Puzzles are Magic entered their information into the site.
Whatever login setup you go for, make sure you support the following:
- Unicode in team names and person names. I’d go as far as saying this is non-negotiable. Several teams have emoji as part of their team culture, and some teams will use languages besides English. Puzzles are Magic got a few teams from Chinese MLP fans (still not sure how), and they used Chinese characters in their team names.
- Password resets. People forget their password. It happens. This is especially important if you go with team-based logins. Lots of people sign up without realizing they’re creating an account for their entire team.
- HTTPS. There’s really no excuse to not use HTTPS. You may think that no one will try to hack your puzzlehunt website. You’ll be correct. However, people reuse passwords when they shouldn’t, and you don’t want packet sniffers to discover any re-used passwords. Just use HTTPS. If you don’t, people will complain, and I will be one of them. Let’s Encrypt is a free certificate signing authority you can use for this.
Admin Sites
Not everyone working on your Hunt will know how to program, and even those that do may not want to pull out a computer terminal every time they want to change something. You’ll want admin sites that let you directly modify your database from a web interface.
Django has a default admin site, and Puzzlehunt CMU’s code comes with custom add-ons to this site. We found they covered our use cases with minimal changes.
This is necessary to running an online hunt. We used it to fix typos in team names, delete duplicate teams created by people who clearly didn’t read our rules saying they shouldn’t this, and do live-updates to issue errata for puzzles.
You’ll also want to have a Big Board (a live-updating team progress page), and a Submission Queue (a live-updating list of recent submissions). These are necessary as well. Not only are they incredibly entertaining to watch, they also give you a good holistic view of the health of your hunt - which puzzles do teams get stuck on, how fast are the top teams moving, are there common wrong answers that indicate a need for errata, etc.
Unlock System
In an Australian style hunt, puzzles are unlocked at a fixed time each day, with hints releasing over time. In a Mystery Hunt style hunt, puzzles are unlocked based on previously solved puzzles, potentially with time unlocks as well.
Supporting both time unlocks and unlocks based on solving K out of N input puzzles is enough to cover both cases. You may also want to support manual overrides of the unlock system, for special cases like helping teams that aren’t having fun. See Wei-Hwa’s post about the Tyger Pit for another example where manual unlocks would have helped.
Answer Submission and Replies
Unless you expect and want to have someone awake 24/7 during Hunt, you’ll want an automatic answer checking system.
For guess limits, you can either give each team a limited number of guesses per puzzle, or you can give unlimited guesses with rate limiting. Both are valid choices. Whatever you do, please, please don’t make your answer checker case-sensitive, and have it strip excess characters before checking for correctness.
Whether you want to confirm partials or not is up to you, but even if you don’t, it’s good to support replies besides just “correct” and “incorrect”, since it opens up new puzzle design space. Example puzzles that rely on custom replies are Art of the Dress from Puzzles are Magic, and The Answer to This Puzzle Is… from GPH 2018.
(Tangent: it is generally good for every puzzle hunt to have 1 or 2 puzzles where the answer tells teams to do something, and they get the real answer after doing so. This gives you a back-up in case one of your puzzles breaks before hunt. Most of these puzzles require an answer checker that can send a custom reply.)
If you decide to confirm partials, you’ll encourage teams to guess more, so make sure you aren’t unduly punishing teams for trying to check their work.
Submissions should be tagged with the team that submitted them, and what time they did so, since this will let you reconstruct team progress and submission statistics after-the-fact.
Errata
Everyone tries to make a puzzlehunt without errata, but very few people succeed. Make sure you have a page that lists all errata you’ve issued so far, including the time that errata came out, and have the errata visible from the puzzle page as well.
If you are building an MIT Mystery Hunt style puzzlehunt, where different teams have different puzzles unlocked, your errata should only be visible to teams that have unlocked the puzzle it corresponds to.
When you issue errata, you’ll want to notify teams, which brings me to…
Email
If you have fewer than 100 participants, you can get away with emailing everyone at once, putting their emails into the BCC field. Above 100 participants, you’ll want an email system.
Puzzles are Magic used Django’s built in email system. Whenever we emailed people, we generated a list of emails, split them into chunks of 80 emails each, then sent emails with a 20 second wait time between each email send. Without the wait time, we found Gmail refused to send our emails, likely because of a spam filter.
As of this writing, we had to turn off a few security settings and manually unlock a CAPTCHA to get Gmail to be okay with Django sending emails from our hunt Gmail address. None of this was necessary to send emails from the hunt Gmail to itself, so it took us a long time to discover our email setup was broken. Make sure you check sending to email addresses you don’t own!
You may want to integrate a dedicated mailing service, like SendGrid or MailChimp, which will deal with this nonsense for you. I haven’t checked how hard that would be.
You’ll want the ability to email everyone (for hunt wide announcements), everyone on a specific team (if you want to talk to that team), and everyone who has unlocked but not solved a specific puzzle (to notify for errata). You may also want the ability to email everyone who hasn’t reached a certain point in the hunt, to talk to less competitive teams.
Puzzle Format
For puzzles, you can either go for a PDF-by-default format, or HTML-by-default format.
The upside of PDF-by-default is that you can safely assume PDFs will appear the same to all users. You don’t have to worry about different browsers or operating systems messing up the layout of your puzzle.
Browser compatibility is a huge pain, but if you’re running an online hunt, I still advocate for an HTML-by-default puzzlehunt. It requires more work, but comes with these advantages.
- You can more easily support “online-only” experiences. In my opinion, if you’re making an online hunt, you should create something that only works online, to differentiate it from in-person events.
- You reduce the number of clicks between a solver and the puzzle. Click link, see puzzle, vs click link, click download, open download, see puzzle.
- If you have several constructors, it’s easier to force consistent fonts and styles across puzzles, by using a global CSS file. With PDFs, you have to coordinate this yourself.
- HTML pages are inherently re-downloaded whenever a solver refreshes or reopens the page. That means if you issue errata, solvers will notice your errata faster than if it’s part of a PDF they have to re-download. It’s also possible solvers will accidentally look at their old downloaded PDF, instead of the new PDF.
In total, I believe these benefits are worth the extra work required. Of course, you should use PDFs in cases where doing so is easier. There was no way A to Zecora was ever going to be in HTML format. Meanwhile, use PDFs when you need the strengths of that format (such as a puzzle where the precise alignment of text is important).
If you plan to have your puzzles be HTML-by-default, you’ll want to have tools that make HTML conversion easier. You can write HTML manually, it’s just incredibly tedious. I personally like Markdown, since it’s lightweight, builds directly to HTML, and you can add raw HTML to Markdown if you need to support something special.
This is off topic, but if you know how, I highly, highly recommend writing scripts that automate converting puzzle data into HTML. Doing so reduces typo risk, and makes it easier to update a puzzle. For Puzzles are Magic, when constructing Recommendations, I wrote a script that took a target cluephrase, auto-generated extraction indices, and outputted the corresponding HTML. For Endgame, I did the same thing. Both those puzzles had 3 drafts, one of which was made the night before hunt, and those scripts saved a ton of time.
Access Control
Teams should not have access to a puzzle before they have unlocked it. This is obvious, but what’s less obvious is that they also shouldn’t have access to any static resources that puzzle uses. Any puzzle specific images, JavaScript, CSS, PDFs, and so on should be blocked behind a check of whether the team has unlocked that puzzle yet.
Assume that solvers will find any file that isn’t gated behind one of these unlock checks, and check whether doing so would break anything about your hunt.
The 100% foolproof way to avoid puzzle leaks is to only put the puzzle into the website right before it would unlock. This works for Australian-style hunts, where puzzles are unlocked on a fixed schedule.
However, for testsolving, you’ll want to have testsolvers use your hunt website, to test both the puzzles and your site. To do so, the puzzles need to be in your website, with access control to restrict them to playtesters. And if you’re going to support that, then you’re 90% of the way there to access control based on team unlock progress, and you might as well go all the way.
File Metadata
There are many ways your puzzle can have side channels that leak information you may not want to leak. For example, the puzzle Wanted: Gangs of Six from MIT Mystery Hunt 2020 involved identifying gangs of six characters from several series, extracting cluephrases using numbers written in fonts matching each series. The solution mentions that testsolvers were able to extract the font names from the PDF properties, and many of the font names were named after the series they were taken from. The final puzzle uses remastered fonts with less spoiler-y names. As another example, for A Noteworthy Puzzle from the 2019 MUMS Puzzle Hunt, the original sheet music and color names could be retrieved from inspecting the PDF file.
Whatever format you use, double check if that format comes with metadata, and if it does, inspect it to see if it leaks anything you don’t want to leak. If you make a music ID puzzle, and forget to clear the artist and album metadata, then, well, that’s on you.
Note that “side channel” implies you don’t want puzzle info to leak this way. Sometimes, leaking info this way is okay. In Tree Ring Circus from MIT Mystery Hunt 2019, one circle has a labeled size, and you need the size of the other circles to solve the puzzle. The circles were drawn in SVG, and to aid solving, the distances used in the SVG file exactly matched the distances you wanted.
Filenames
Make your filenames completely non-descriptive. If you have 10 images, name them “1.png”, “2.png”, “3.png”, and so on, in order of the webpage. Or better yet, give each of them randomly generated names. Anthropology from Puzzles are Magic used random names, since solvers needed to pair emoji pictures to numbers, and I didn’t want the emoji in “1.png” to be confused for the number 1.
If you have an interactive puzzle where hidden content only appears after the solvers reach a midway point, hide that content appropriately. If you have a secret 5th image, and you name your first four images “1.png” to “4.png”, you don’t want solvers to shortcut the puzzle by trying to load “5.png”.
Again, like the file metadata mentioned above, sometimes leaking info in filenames is okay. An example puzzle that does this is p1ctures from MIT Mystery Hunt 2015. Yes, almost anything can be part of a puzzle if you try hard enough.
Interactive Puzzles
Interactive puzzles are usually more work to make, but are also often the most memorable or popular puzzles. (My theory is that interactive puzzles naturally let you hide complex rules behind a simple surface, and the emergent complexity this creates is the entire reason that people like solving puzzles.)
The rule-of-thumb in online video games is to never, ever trust the client. Puzzlehunts are the same. In MIT Mystery Hunt 2020, teammate solved 2 or 3 interactive puzzles by inspecting the client-side JavaScript, finding a list of encrypted strings, searching for the function that decrypted them, and running the decryption until we found strings that looked like the answer.
Assume that teams will decode any local JavaScript, even if you minify and obfuscate it. The only guaranteed way to close these shortcuts is to move all key puzzle functionality to server-side code. Server-side confirmation has higher latency than client-side confirmation, so if you’re worried about responsiveness, only confirm the most important parts of the puzzle on the server. The interactive puzzles for Puzzles are Magic were essentially turn-based, so we didn’t care about latency and had all the logic be server-side.
For example, in Applejack’s Game, all the JavaScript does is take the entered message, send it to the server, and render the server’s response. That’s it. There’s nothing useful to retrieve from the client-side JavaScript, so there’s no need to hide it.
If possible, try to avoid repeating logic across the client and server. The GPH 2019 AMA mentions that one puzzle (Peaches) had a bug where client-side logic didn’t match the server-side verification, which caused some correct solutions to get marked as incorrect.
As mentioned in that AMA, if your server side code fails, make sure to give teams an obvious error, perhaps one that tells them to contact you so that you learn about the problem.
Accessibility
You can generally assume that most solvers will be on either Windows or Mac OS X, they will normally use one of Chrome, Safari, or Firefox, and they’ll be solving from a laptop-sized or monitor-sized screen.
The key word here is most. Accessibility issues will always affect a minority of your users, but there are a lot of minorities. If you want more people to solve your puzzlehunt, you’ll need to be inclusive when possible.
Some of your solvers will be color blind. Some of your solvers will be legally blind. Some of your solvers will heavily prefer printing puzzles versus solving them online. Of those solvers, not all of them will have access to color printers.
You may not be able to please all of these people. If your puzzle is based on image identification, the legally blind solver is not going to be able to solve it. You can’t even provide alt text that describes the image, because non-blind solvers will use the alt text as a side channel. But, try to do the best you can. As mentioned from the 2019 MIT Mystery Hunt AMA, “Keep in mind what the puzzle actually needs in terms of skills and abilities, and what you’re presuming the solver/s will have. Wherever there’s a mismatch, try to make the puzzle suit the smallest set of abilities without stomping on data the puzzle needs.”.
For color blind solvers, try to avoid colors that are too visually similar to one another. If you need to use a large number of colors, consider providing a color blind alternative.
For people who prefer printing puzzles, make sure that your puzzles print well. By default, printers ignore all CSS, so by default, your puzzles probably print poorly. You’ll need to define specific print CSS files to get your puzzles to print correctly.
Some solvers will be solving from smartphones or tablets, rather than desktops or laptops. It’s okay if your site is worse from mobile, but make sure your site isn’t completely broken on mobile. Even solvers with laptops will appreciate being able to solve puzzles on the go.
Watch out for slow Internet connections or computers. In Number Hunting from Puzzles are Magic, we used MathJax to render the math equations for flavor reasons, but we found this sometimes took a while, and rendered poorly on mobile because MathJax equations don’t support line wrap. So, we included a plaintext version as well.
The one big accessibility failure from Puzzles are Magic I’m still annoyed about is The Key is Going Slow and Steady. One lesson we learned during hunt construction was that puzzle presentation really matters. If a puzzle looks big, it’s intimidating, and solvers are less likely to start it. So, if you can find a way to make a puzzle look smaller, you should. Recommendations testsolved a lot better when I made all the images 4x smaller, even though this changed nothing about its difficulty.
For The Key is Going Slow and Steady, we used Prezi to bundle the flowchart into a smaller space. The problem this introduced from an accessibility standpoint is that Prezis load really, really slowly, and Prezis don’t work on mobile. At all. We were aware of these issues, but didn’t have time to build a lightweight alternative, so it had to go as-is.
Hardware and Load Testing
To run your hunt, you’re going to need a server. If you work at a university, check if your university provides free computing services. If you don’t have a server on hand, or you don’t want to trust your personal Internet, you’ll probably use a cloud computing service.
For cloud services, you can either go for a raw machine, or you can use app creation services like Google App Engine or AWS Elastic Beanstalk. App services will give you less flexibility, will require writing code to fit their API, and are more expensive. However, they’ll handle more things for you, like auto-scaling your site when you get more users.
Puzzles are Magic was hosted from a raw machine we purchased through Google Compute Engine. We did this because it required the fewest changes from the Puzzlehunt CMU code we started from, and we had some GCE free trial credit to play with. Unfortunately, our free trial expired about 6 weeks before the hunt started. We spent about $120 in total. Of that total, $80 was spent in the 4 weeks around hunt, and $40 was spent in the remaining time. We’re currently spending about $16/month to run the hunt in maintenance mode.
Here’s a chart for number of users per day, with annotations for key dates.
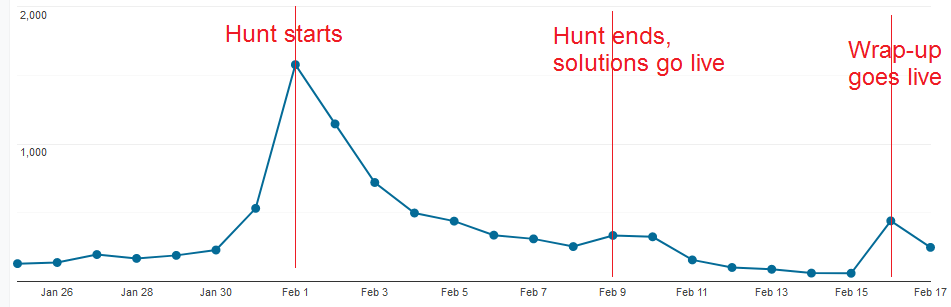
User counts started increasingly rapidly the week before hunt, peaked the first weekend, then decayed over time. Make sure you get a large enough machine a few weeks before your hunt starts.
We load tested our website using Locust. Our target was supporting 750 active users using the site at the same time. We picked that number based on registration counts and our estimates for how many teams would start working the moment puzzles released.
Make sure you test from a fast Internet connection, or split your load test across a few networks! We had trouble getting more than 250 active users to work, and eventually debugged it to load testing from a slow connection that had trouble pretending to be 250 users. The site was fine the entire time.
If your server is too busy to respond to solvers, it’s also going to be too busy to respond to your remote login attempts to fix it. Err on the side of too large. The money is worth your mental health.
More Exact Hardware Details
This part is only interesting if you care about webserver configuration.
We used a
n1-standard-4machine. Based on GCE specs, this corresponds to 4 hardware hyper-threads on a Skylake-based Intel Xeon Processor. The machine had 15 GB of RAM, and used the following Apache config (added to/etc/apache2/apache2.conf).<IfModule mpm_event_module> StartServers 10 ServerLimit 110 MinSpareThreads 25 MaxSpareThreads 75 MaxRequestWorkers 1000 ThreadsPerChild 5 AsyncRequestWorkerFactor 2 </IfModule>StartServers is the number of processes to start. It should satisfy
MinSpareThreads < StartServers * ThreadsPerChild < MaxSpareThreads.ServerLimit is the maximum number of processes to start. It should satisfy
ServerLimit * ThreadsPerChild > MaxRequestWorkers. (This isn’t true for our config because of a config error.)MinSpareThreads and MaxSpareThreads and the number of spare threads to prepare for new incoming connections. We didn’t change this.
MaxRequestWorkers is the maximum number of threads (requests) you want your server to support. Any requests over this limit will be blocked, until existing requests are fulfilled.
ThreadsPerChild is the number of threads to spawn per process. Most configurations online use
ThreadsPerChild 25. We found using more processes and fewer threads per process made our site load a bit faster, at the cost of more CPU usage and RAM usage. UsingThreadsPerChild 25with 5x smaller StartServers and ServerLimit should be good enough for you.We’re not sure what AsyncRequestWorkerFactor is, but all the guides we found online recommended keeping it at the default of 2.
Caching
Adding caching to your website can heavily speed up its performance. However, it also opens your site to caching errors, which can be extra dangerous when you’re trying to add errata to a puzzle.
We tried to avoid caching, and were willing to pay the costs that came with it, but part of our Apache config cached static resources we didn’t want to cache. We never debugged why, but it did mean that when we added errata to a PDF, it took 5 minutes for the errata to propagate to solves. Luckily, the errata was minor.
Hiding Spoilers from Web Crawlers
Adding
<meta name="robots" content="noindex">to the header of an HTML file prevents most search engines from indexing that page. To avoid spoiling anyone who looks through your archive later, that header should be added to the solutions for each puzzle, as well as any other page that could spoil that puzzle’s answer.Static Conversion
As mentioned earlier, running Puzzles are Magic in maintenance mode currently costs about $16/month. For archiving purposes, sometime after the hunt, you’ll want to convert your website into a fully static site. This brings your maintenance costs to almost zero. Amazon S3 costs just a few cents per GB of storage and data transfer, and GitHub Pages lets you host a static site for free.
Try to have a static answer checker ready to go before hunt ends. Even if all your solutions are ready the instant hunt ends, you want to give solvers the ability to check their answers spoiler-free.
As for converting the rest of the site, well, that can take some time. Remember how I said interactive puzzles should have all their logic be server-side? Well, making them work client-side means you have to reproduce all the server-side code to run in-browser. Puzzles are Magic still hasn’t been converted yet, and it’s been over a month since the hunt finished. I’m the one who wrote the code for all the interactive puzzles, so it’s on me to fix it.
If you’d rather not deal with these headaches, you can pay the server costs forever and leave the site as-is. Personally, I’d rather not pay $16/month for the rest of my life.
For non-interactive portions, the command mentioned here worked for me, but you should double check the links yourself, especially if your paths include Unicode characters, or are case sensitive.
March 29, 2020 update: Just finished static conversion of Puzzles are Magic, hosting it through Github Pages. I didn’t have Unicode issues, but did hit other problems.
- Some non-HTML files were not getting served with the correct file type in their
header. This still worked for solvers, but files like
1.pngwere crawled and saved as1.png.html. This broke some of the dynamic puzzles, and I had to rename all those files, and fix the generated links to each, which I did with some small shell scripts. - Files loaded through dynamic JavaScript were not crawled by
wget, and had to be added manually. - Files that relied on absolute paths broke in local testing, and needed to be changed to use relative paths.
- In the dynamic version of the site, trailing slashes did not matter to the
URL. Going to
/hunt/current/was equivalent to visiting/hunt/current. In the static version, this was different. The path/hunt/current/is shorthand for “load hunt/current/index.html”, and/hunt/currentis short for “load hunt/current.html”. Unfortunately, the links indexed by search engines all used trailing slashes. I was using Github Pages, which uses Jekyll, so I used jekyll-redirect-from to generate redirects from trailing slashes to the intended page. One gotcha was thatredirect_from: /hunt/current/had to be added as the very start of the file, no whitespace allowed at the top, or else it would be treated as part of the HTML file.
* * *
I am probably missing some things, but those are all the big ones.
This is likely my last puzzle-related post for a while. Almost all my 2020 blog posts have been about puzzles, but I do have other interests! Stay tuned for more.