Writing MIT Mystery Hunt 2023
This post is about 55,000 words long, and is riddled with spoilers for pretty much every aspect of MIT Mystery Hunt 2023. There are no spoiler bars. You have been warned. Please pace yourselves accordingly.
I feel like every puzzle aficionado goes through at least one conversation where they try to explain what puzzlehunts are, and why they’re fun, and this conversation goes poorly. It’s just a hard hobby to explain. Usually, I say something about escape rooms, and that works, but in many ways the typical puzzlehunt is not like an escape room? “Competitive collaborative spreadsheeting” is more accurate, but it’s less clear why people would find it entertaining.
Here is how I would explain it if I had more time. In a puzzlehunt, each puzzle is a bunch of data. Unlike puzzles people normally think of, a puzzle in a puzzlehunt may not directly tell you what to do. However, if it’s a good puzzle, it will have exactly one good explanation, one which fits better than every alternative. Every part of the puzzle will point to some core idea or ideas, in a way that can’t be a coincidence. In other words, a puzzle is something that compresses well. As a solver, your job is to find out how.
Puzzles can be a list of clues, a small game, a bunch of images, whatever. The explanation for how a puzzle works is usually not obvious and fairly indirect, but there is a guiding contract between the puzzle setter and puzzle solver that the puzzle is solvable and its solution will be satisfying. At the end of the puzzle, you’ll end with an English word or phrase, but that is more to give a puzzle its conclusion. People do not solve puzzles to declare “The answer is THE WOLF’S HOUR!”. They solve puzzles because figuring out why the answer is THE WOLF’S HOUR is fun, and when you find the explanation (get the a-ha), you feel good.
There’s a reason professors and programmers are overrepresented among puzzlehunters. Research and debugging share a similar root of trying to explain the behavior of a confusing system. It stretches the same muscles. It’s just that puzzles are about artificial systems designed to be fun and solvable in a few hours, whereas research is about real systems that may not be fun and may not be solvable.
That gives more of an answer to why people do puzzles. Why do people write puzzles?
I have a harder time answering this question.
Working on Mystery Hunt 2023 started as a thing on the side, then evolved into a part-time job, then a full-time job towards the end. Writing a puzzlehunt is incredibly time consuming. You’re usually not getting much money, and your work will, in the end, only be appreciated by a small group of hobbyists with minimal impact elsewhere. It all seems pretty irrational.
In some sense, it is. That doesn’t mean it’s not worth doing.
Post Structure
Oooh, a section of the post describing the post itself. How fancy. How meta.
I have tried to present everything chronologically, except when talking about the construction of specific puzzles I worked on, in which case I’ve tried to group my comments on the puzzle together. Usually I was juggling multiple puzzles at once, so strict chronology would be more confusing than anything else.
This post aims to be complete, and that means it may not be as entertaining. I’m not sure of the exact audience for this post, and figured it’d be useful if I just dumped everything I thought was relevant. If you are the kind of person who reads a Mystery Hunt retrospective that’s posted in April, it’s likely you’ll want to see the nitty gritty details anyways.
Most of the post is going to be a play-by-play of things I worked on. The analysis and commentary is at the end.
- Post Structure
- December 2021
- January 2022
- February 2022
- March 2022
- April 2022
- May 2022
- June 2022
- July 2022
- August 2022
- September 2022
- October 2022
- November 2022
- December 2022
- January 1-8, 2023
- Monday Before Hunt
- Tuesday Before Hunt
- Wednesday Before Hunt
- Thursday Before Hunt
- Friday of Hunt
- Saturday of Hunt
- Sunday of Hunt
- Monday of Hunt
- February 2023
- March 2023
- Thoughts on Hunt
- Ways to Improve the 2023 Hunt
- Unordered Advice
- So…Why Do People Write Puzzles?
- AIs and Puzzles
- The Start of the Rest of My Life
December 2021
Oh Boy, Mystery Hunt is Soon!
Writing and post-hunt tech work for Teammate Hunt 2021 is over and has been over for a while. Life is good. Team leadership sends out a survey to see if teammate has enough motivation to write Mystery Hunt.
I use a time tracker app for a few things in my life, and puzzle writing is one of them. My time spent on Teammate Hunt clocked in at 466 hours. I do some math and find it averaged to 15 hours/week. This is helpful when trying to decide how to answer the question for how much time I’d commit to Mystery Hunt if we won.
I already had some misgivings around how much time and headspace Teammate Hunt took up for me. On the other hand, it is Mystery Hunt. Noting that I felt like I did too much for Teammate Hunt, I said I expected to work 10 hours/week on Mystery Hunt if we won this year.
The survey results come in, and there is enough interest to go for the win. I have zero ideas for a puzzle using Mystery Hunt Bingo, but figure that maybe we’ll win Hunt, and maybe there will be a puzzle using my site, so I’d better remove the “this is not a puzzle” warning early, just in case. I didn’t want to face any warrant canary accusations if we actually won.
January 2022
The Game is Afoot
Holy shit we won Hunt!!!!!
I write a post about Mystery Hunt 2022, where I make a few predictions about how writing Mystery Hunt 2023 will go.
After writing puzzles fairly continuously for 3 years (MLP: Puzzles are Magic into Teammate Hunt 2020 into Teammate Hunt 2021), I have a better sense of how easy it is for me to let puzzles consume all my free time […] Sure, making puzzles is rewarding, but lots of things are rewarding, and I feel I need to set stricter boundaries on the time I allocate to this way of life - boundaries that are likely to get pushed the hardest by working on Mystery Hunt of all things.
[…] I’m not expecting to write anything super crazy. Hunt is Hunt, and I am cautiously optimistic that I have enough experience with the weight of expectations to get through the writing process okay.
Before officially joining the writing Discord, I set myself some personal guidelines.
Socializing takes priority over working on Mystery Hunt. I know I can find time for Mystery Hunt if I really need to. A lot of puzzle writing can be done asynchronously, and I’m annoyingly productive in the 12 AM - 2 AM time period.
No more interactive puzzles, or puzzles that require non-trivial amounts of code to construct. The goal is to make puzzles with good creation-time to solve-time ratios. Puzzles that require coding are usually a nightmare on this axis, since it combines the joys of fixing code with the joys of fixing broken puzzle design.
No more puzzles where I need to spend a large amount of time studying things before I can even start construction. Again, similar reason, this process is very time consuming for the payoff. I’d estimate I spent 80 hours writing Marquee Fonts, since I started with knowing nothing about how fonts worked at the start, and had to teach myself much more about fonts than I’d ever wanted to know to make the puzzle a reality.
No more puzzles made of minipuzzles. Minipuzzles are a scam. “Oh, we don’t have any ideas that are big enough to fill one puzzle. Let’s make a bunch of minipuzzles instead because it’s easy to come up with small ideas!” Then you get halfway through, and realize that ideation of small puzzles is easy, but execution takes way longer. The process of finding suitable clues is somewhat independent of puzzle difficulty, and you have to do way more of it. I also felt it was a crutch I was relying on too often when designing puzzles.
No more puzzles with very tight constraints. It collectively took 60-100 person hours to figure out mechanics and find a good-enough construction for The Mystical Plaza, even with breaking some puzzle rules along the way. Usually, the time spent fitting a tight constraint does not directly translate into puzzle content.
These guidelines all had a common theme: keep Hunt manageable, and make puzzles that needed less time to go from idea to final puzzle.
I would end up breaking every one of these guidelines.
Team Goals and Theme Proposals
The very first thing we did for Hunt was run a survey to decide what Hunt teammate wanted to write. What was the teammate experience that we wanted solvers to have?
We arrived at these goals:
- Unique and memorable puzzles
- Innovation in hunt structure
- High production value
- Build a great experience for small / less intense teams
Unique and memorable puzzles: Mystery Hunt is one of the few venues where you can justifiably write a puzzle about, say, grad-level complexity theory. That’s not the only way to make a unique and memorable puzzle, but in general the goal was to be creative and avoid filler.
Innovation in hunt structure: This is something that both previous Teammate Hunts did, and as a team we have a lot of pride in creating puzzles that stretch the boundaries of what puzzles can be.
High production value: teammate has a lot of software engineering and art talent, which let us make prettier websites and introduce innovations like copy-to-clipboard. We wanted to make a Hunt that lived up to the standards set by our previous hunts.
Build a great experience for small / less intense teams: We generally felt that Mystery Hunt had gotten too big. When we won Hunt, we were around 60% the size of Palindrome’s winning team. Correspondingly, we spent a while discussing how to create fewer puzzles while still creating a Hunt of satisfying length, as well as whether we could have more mid-Hunt milestones.
We then decided team leadership.
Hey everyone! Today is the deadline for submitting interest in leadership. Everyone who indicated interest will meet tomorrow and discuss the best division of responsibilities (not everyone will end up with a role, and some roles may have more than one person, based on examples from previous Hunts.) We decided to go with a closed meeting rather than a democratic vote to ensure that we reached the optimal allocation of responsibilities among everyone interested. We’ll let you know the final leadership team, and then have an official Writing Server Kickoff in the next few days!
I deliberately did not fill out the form, because it implied a baseline level of commitment that was above my 10 hr/week target.
The next step was theme proposals. This is always an interesting time in hunt development, since it sets the agenda of the entire upcoming year. Things can change later, but writing a puzzlehunt is an especially top-down design process. You decide your story, which decides your metametas and metas, which decides your feeders. It’s all handing off work to your future selves.
Historically, at the start of theme writing, I say I don’t have theme ideas. Then I get an idea right before the deadline and rush out a theme proposal. This happened in Teammate Hunt 2021 and it happened for Mystery Hunt. The theme I pitched for Teammate Hunt 2021 was not revived for Mystery Hunt (I didn’t think it scaled up correctly), but the Puzzle Factory theme is recycled from a Teammate Hunt 2021 proposal. We talked a bit about whether this was okay, since some organizers for Teammate Hunt 2021 were not writing Mystery Hunt this year. In the end we decided it was fine. At most there would be plot spoilers, not meta spoilers.
We liked the story structure of Mystery Hunt 2022 a lot, and almost all theme proposals were structured around a “three Act” framework, where Act I introduced the plot, Act II built up to a midpoint story event, and Act III resolved that event.
A few members with past Mystery Hunt experience mentioned that theme ideation could get contentious. People naturally get invested in themes, and spend time polishing their theme proposal. People working on other themes would observe this, and feel obligated to polish their proposals. This could escalate into a theme arms race, with lots of time spent on themes that would ultimately not get picked.
To try to avoid this, a strict 1 page limit was placed on all theme proposals. People were free to read discussion threads of longer freeform brainstorming, but there would be no expectation to do so, and all plot and structure proposals needed to fit in 1 page.
Did this work? I would say “maybe”. It definitely cut down on theme selection time, and reduced work on discarded themes, but it also necessarily forced theme proposals to be light on details. Team memes like “teammate is the villain” seemed to work their way into every serious theme proposal. Maybe that was genuinely the story we wanted to tell, but it could also have been an artifact of proposing themes while the memes were fresh. There may have been more diversity in theme ideas if they were written over a longer period of time. Palindrome’s theme was picked by the end of February, according to Justin Ladia. Galactic’s theme was picked February 26, according to CJ Quines. teammate’s theme was selected the evening of January 31.
I was not on the story team, but in our post-Hunt retrospective, members of the story team mentioned they were under a lot of pressure to fill in plot details that weren’t in the theme proposal, because, well, there wasn’t space for them in the proposal! Even the details that do exist differ a lot from where the story ended up. Here is how I would summarize the final version of the Hunt story.
teammate announces a Museum themed puzzlehunt written by MATE, a puzzle creating AI. During kickoff, teammate is really concerned with making a “perfect” Mystery Hunt that isn’t doing anything too crazy. The Museum is Act I of the Hunt. Over the course of solving, teams discover the Puzzle Factory, the place where Mystery Hunt puzzles are created. The Puzzle Factory is not a place that solvers were supposed to discover, and teammate does their best to pretend it doesn’t exist when interacting with teams. The Puzzle Factory is Act II of the Hunt, and is explored simultaneously with Act I. As they explore the factory, teams learn that MATE is overworked, and other AIs that could have helped MATE were locked away by teammate due to being too weird.
Solvers reconnect the AIs, and this prompts teammate to shut down MATE and the Puzzle Factory. They berate teams for trying to turn on the old AIs, then leave and declare Mystery Hunt is cancelled.
However, there is some lingering power after Mystery Hunt is shutdown, which solvers can use to slowly turn the Puzzle Factory and other AIs back on. This starts Act III of the Hunt, with puzzles written by the old AIs. Each AI round is gimmicked in some way, ending in a feature request that the AI wants to add to the Puzzle Factory. When all AI rounds are complete, MATE comes back, and after solving a final capstone, teammate comes back and admits that they were wrong about the old AIs. The Puzzle Factory makes one more puzzle, which has the coin, and MATE gets their long-deserved break.
Now, here is the start of the original proposal:
Act I begins with the announcement of an AI called MATE that can generate an infinite stream of perfect puzzles, as well as provide real-time chat assistance for hints, puzzle-solving tools, etc). During kickoff, teammate gives a business presentation with MATE in the background– but at the end, the video feed glitches briefly and other AIs show up for a split second (“HELP I’M TRAPPED”); teammate doesn’t notice. Stylistically, the first round looks like a futuristic, cyberspace factory. As teams solve the initial round of puzzles, errata unlock (later discovered to be left by AIs locked deeper in the factory), hinting that there’s something “out of bounds”. No meta officially exists for this round (the round is “infinite”), but solving and submitting the answer in an unconventional way leads to breaking out. (To prevent teams from getting stuck forever, we can design the errata/meta clues to get more obvious the more puzzles they solve.) Solving this first meta also causes MATE to doubt their purpose and join you as an ally in act II.
Quite a lot changed from the start to the end. The infinite stream idea was cut because we couldn’t figure out the design. Kickoff did not show the other AIs at all. The surface theme was changed to something completely different. In a longer ideation process, perhaps more of this design work could be done by the entire team, rather than just the story team. Maybe allowing wasted effort is worth it if it gets the details filled out early?
Themes were rated on a 1-5 scale, where 1 = “This theme would directly decrease my motivation to work on Hunt (only use if serious)” and 5 = “I’ll put in the hours to make this theme work”. I don’t remember exactly how I voted, but I remember voicing some concerns about the Puzzle Factory. The plot proposal seemed pretty complicated compared to previous Hunts. I wasn’t sure how well we’d be able to convey the story - You Get About Five Words felt accurate for Mystery Hunt, where some people will speedrun the story in favor of focusing on puzzles. I was also hesitant about whether we’d have enough good ideas for gimmicks to fill out the AI rounds in Act III. It seemed like a good theme for a hunt with 40 puzzles, but I didn’t know if it worked for a Mystery Hunt with 150+ puzzles.
I’m happy I was wrong on both counts. Feedback on the story has been good, and I feel the AI round gimmicks all justified themselves. I was imagining a Mystery Hunt where Act III was the size of Bookspace (10 rounds) and limiting it to 4 rounds did a lot for feasibility.
The Puzzle Factory did not win by a landslide, but it was the only theme with no votes of 1, and had more votes of 5 than any other theme. Puzzle Factory it is!
Hunt Tech Infrastructure
I’m going to talk a lot about hunt tech, a very niche topic within the puzzle niche. This won’t be relevant to many people. Still, I’m going to do so because
- It’s my blog.
- By now I’ve worked with four different puzzlehunt codebases (Puzzlehunt CMU, gph-site, tph-site, and spoilr), so I’ve got some perspective on the different design decisions.
The first choice we had to make was whether we’d use the hunt codebase from Palindrome, or use the tph-site codebase we’d built over Teammate Hunt 2020 and Teammate Hunt 2021. Our early plan is to mostly build off tph-site. The assumption we made is that most Mystery Hunt teams do not have an active codebase, and default to using the code from the previous Mystery Hunt. However, teammate had tph-site, knew how to use it, and in particular had accumulated a lot of helper code to make crossword grids, implement copy-to-clipboard, and create interactive puzzles.
The only recent team that seemed like they had faced a similar decision was Galactic, who decided to build off the spoilr codebase and make silenda rather than use gph-site. After asking some questions, it sounded like the reason this happened was because parts of their tech team were already familiar with spoilr. So for our situation, it seemed correct to use whatever code we knew best, which was tph-site.
A few writers from Huntinality 2.0 are asking if they can see the work we did to convert our frontend to React. This motivated us to start open-sourcing tph-site. It’s not too much work, and feels like a good thing to do.
A React Tangent
Almost every hunt codebase is written in Django. It’s a Python web framework that does a lot of work for you. In Django, Python code defines your database schema, user model, what backend code you want to run when users make a request, and what URLs you want everything to be accessed from. Although it is helpful to know what happens under the hood, Django makes it possible to build a site without knowing what happens under the hood. It’s also almost all Python, one of the most friendly beginner languages. I first learned Django 11 years ago and it’s still relevant today.
The default recommended approach in Django is that when a request comes in, you render an HTML response based on a template file that lives on your backend. The template gets filled out on the server and then gets sent back as the viewed webpage.
tph-site still uses Django as its backend, but differs in using a React + Next.js based frontend. React is a Javascript library whose organizing principle is that you describe your page in components. Each component either has internal state or state passed from whatever creates the components. A component describes what it ought to look like according to the current state, and whenever the state is updated, React will determine everything that could depend on that state and re-render it. The upside: dynamic or interactive web pages become a lot easier to build, since React will handle a lot of boilerplate Javascript and state management for you. The downside: extra layers of indirection between your code and the resulting HTML.
Next.js is then a web framework that makes it easier to pass React state from the server, and support rendering pages server-side. This is especially useful for puzzlehunts, where you want to do as many things server-side as possible to prevent spoilers from leaking to the frontend. (As for the merits of SPAs versus a multi-page setup, I am not qualified enough to discuss the pros and cons.)
The tph-site fork exists because teammate devs wanted to use React to implement the Playmate in Teammate Hunt 2020. Porting gph-site to React was quite painful, but I don’t think Playmate was getting implemented without it, and we’ve since used it to support other interactive puzzles. In general, I believe we made the codebase more powerful, but also increased the complexity by adding another framework / build system. (To use tph-site, you need to know both Django and React, instead of just Django.) One of teammate’s strengths is that we have a lot of tech literacy and software engineering skills, so we’re able to manage the higher tech complexity that enables the interactive puzzles and websites we want to make. For new puzzlehunt makers, I would generally recommend starting with a setup like gph-site, until they know they want to do something that justifies a more complicated frontend.
February 2022
PuzzUp
PuzzUp is Palindrome’s fork of Puzzlord, and is a Django app for managing puzzles and testsolves. We built off their fork and released our version here after Mystery Hunt. We considered giving PuzzUp a teammate brand name, and didn’t because there were more important things to do.
The mantra of puzzlehunt tech is that it’s all about the processes. The later in the year it gets, the busier everyone is with puzzle writing, and good luck implementing feature requests during Hunt. Early in the year is therefore the best time to brainstorm ways to reduce friction in puzzle writing and hunt HQ management.
The PuzzUp codebase had some initial Discord integrations to auto-create Discord channels when puzzles were created in PuzzUp. We wanted to extend this integration to auto-create testsolve channels for each puzzle. However, Discord limits servers to have a max of 500 channels. Based on an extrapolation from Teammate Hunt, we’d have more than 500 combined puzzle ideas + testsolves by the end of Mystery Hunt writing. (I just checked out of curiosity, and we hit over 800 combined ideas + testsolves, with 338 puzzle ideas and almost 500 testsolves by the end of Hunt.)
We poked around and found Discord has much looser limits on threads! So anything that lets us permute channels into threads lets us get around the Discord limits.
Here’s what we landed on: all testsolves are threads. Each thread is made in a #testsolve-mute-me channel. Muting the channel disables all notifications from the channel. Whenever a testsolve session is created, the PuzzUp server would start a thread, tag everyone who should be in the testsolve, then immediately delete the message that linked to thread creation. The thread would still exist, and could be searched for, but no link would appear in the text channel. The relevant logic is here if you’re curious. We also extended the codebase to have Google Drive integration, to auto-create testsolve spreadsheets for each new testsolve.
I say “we”, but I did none of this work. I believe it was mostly done by Herman. Much later in the year, I updated the Google integration to auto-create a brainstorming spreadsheet for new puzzles in our shared Drive, because I got annoyed at manually making one and linking it in PuzzUp each meeting. You don’t know what will be tedious until you’ve done it for the 20th time.
Puzzle Potluck
A puzzle potluck (no not that one) gets announced for early March. The goal is to provide a low-stakes, casual venue for people to start writing puzzle ideas. There are no answer constraints, write whatever you want! There’s not much to do in tech yet, so I started working on three ideas. One does not work and does not make it into Hunt. One is an early form of 5D Barred Diagramless with Multiverse Time Travel. The last goes through mostly unchanged.
Quandle
Puzzle Link: here
Perhaps you remember that I set a personal guideline for “no more interactive puzzles”, and think it’s strange that I worked on an interactive puzzle within a month. Yeah, uh, I don’t know what to tell you.
In my defense, as soon as “Quantum Wordle” entered my brain, I was convinced it would be a good puzzle and that I had to make it. I found an open-source Wordle clone and got to work figuring out how to modify it to support a quantum superposition of target words. This took a while, since I started with the incorrect assumption that letters in a guess are independent of each other. This isn’t true. Suppose the Wordle is ENEMY, and you guess the word LEVEE. The Wordle algorithm will color the first two Es yellow, and the last one gray. When extended in the quantum direction, you can’t determine the probability distribution of one E without considering the other Es. They’re already dependent on each other. (Grant Sanderson of 3Blue1Brown would put out a video admitting to a similar mistake shortly after I realized my error, so at least I’m in good company.)
After I got the proof of concept working, I considered how to do puzzle extraction. My first thought was to have the extraction be based on finding all observations that forced exactly one reality, but after thinking about it more, I realized it was incredibly constraining on the wordlist. This certainly wasn’t a mechanic I was going to figure out in time for the potluck deadline in March, so I went with a set of words with no pattern in an arbitrary order with arbitrary indices. That way I could do whatever cluephrase I wanted. Making that cluephrase point to specific words felt like the most interesting idea, and after a bit more brainstorming, the superposition idea came out.
Internally, the way the puzzle works is that the game starts with 50 realities. On each guess, the game computes the Wordle feedback for every target word, then averages the feedback across all realities. When making an observation, it repeats the calculation to find every target word consistent with that observation, deletes all other realities, and recomputes the probabilities for all prior guesses. Are there optimizations? Probably. Do you need to optimize a 50 realities x 6 guesses x 5 letter problem? No, not really. This will become a running theme. For Hunt, I optimized for speed of implementation over performance unless it became clear performance was a bottleneck.
The puzzle could have shown 50 blanks, revealing each blank when you solved a word, but I deliberately did not do that to make it harder to wheel-of-fortune the cluephrase. It is harder to fill gaps when you don’t know how many letters are in each gap.
During exploration, I generated random sets of 50 words, to get a feel for how the game played. My conclusion was that one observation was too little information to reliably constrain to one reality, while two observations gave much more information than needed. I considered making the word list more adversarial, but in my opinion, the lesson of Wordle is that it’s fine to give people more information than they need to win. People are not information-maximizing agents [citation needed]. I left it as-is.
As one of the first tests of our PuzzUp setup, I did a puzzle exchange with Brian. He tested Quandle and I tested Parsley Garden. Around 60 minutes into the Quandle test, I asked how the puzzle was going. Brian said he was stuck, and after asking a bunch of questions, I figured out that he has never clicked a guess after making one, meaning he’s never seen the probability distributions or used an observation. Oops. I added a prompt to suggest doing that, and the solve was better from there.
After potluck, I asked for a five letter answer, but none were available. The best option left was two five letter words. Aside from the design changes needed to make that work, the rest of the puzzle mechanics stayed the same, and the work later in the year was mostly figuring out how to embed it in our codebase and share team state.
People liked this puzzle! I expected that, it’s why I broke my “no interactives” rule. What I did not expect was that it would be one of the more discussed puzzles of the Hunt, especially in non-puzzle contexts like the World Poker Tour blog. I think that happened because the puzzle’s idea is easy to motivate and explain to people who don’t know what puzzlehunt puzzles are.
I’ve been told that technically, the quantum interpretation of Quandle is inaccurate. I believe the core issue is that you’re not supposed to be able to observe the probability distribution of a letter before observing the outcome. The distribution should immediately collapse to a fixed outcome as soon as you look at it. You certainly shouldn’t be able to make an observation that collapses from one superposition of 50 realities to another superposition of < 50 realities. This all sounds accurate to me and I don’t care. Get your pedantry out of here, I’m trying to make a puzzle.
March 2022
Of Metas and MATEs
The internal puzzle potluck goes well! Editors tell me that there were multiple Wordle-themed potluck ideas, the Hunt should only have one, and Quandle is the one they’re going to go with. Hooray! Apologies to the other puzzles in the Wordle graveyard.
Chat implementation for MATE and other AIs is coming along smoothly. teammate has multiple people with NLP experience, including with large language models, and for this reason we immediately know we are not going to touch them with a ten foot pole. We are going to stick to hardcoded chat responses that trigger according to a hardcoded chat interaction graph. At most we may use NLP to determine chat intents, no more. As a proof of concept, we use text-adventure style intents, where only specific keywords will trigger the right behavior. Everyone involved with chat then gets busy, and we never move past this. I do wish we’d used one of the lightweight ML libraries, to reduce the “sorry, I don’t understand” replies, but it was correct to deprioritize this.
User: hi
MATE: It’s nice to meet you!
User: are you a puzzle
MATE: I’m sorry, I don’t know what you mean.
User: are you a puzzle?
MATE: Come again?
User: usually if something isn’t a puzzle it will say “this is not a puzzle”
MATE: Alright.
User: is this a puzzle?
MATE: I’m sorry, I don’t know what you mean.
Meta writing is also now going in earnest. I mean, it was going ever since theme finalization, but now it’s extra going. Very approximately, these are the steps to writing Mystery Hunt puzzles.
- Decide on a theme.
- Figure out the major story beats that you want in the Hunt.
- In parallel, write metapuzzles off the critical path of story. Ideally, your major story beats are tied to metapuzzles, since this connects the solving process to the narrative. Those metas block on story development, but the rest don’t have to. Think, say, Lake Eerie in Mystery Hunt 2022. Good round? Absolutely! Was its answer critical to the story of that Hunt? No, not in the way that The Investigation was.
- Once the major story beats are decided, start writing the metas for story-critical answers.
- Whenever a meta finishes testsolving, release all its feeder answers.
- When all your metas and feeders are done, you’ve written all the puzzles of Hunt!
Mystery Hunt writing is very fundamentally an exercise in running out of time, so everything that can be done in parallel should be done in parallel. Interestingly, for Mystery Hunt 2023, that means the AI rounds were ideated first, because their answers were not story-critical, whereas the Museum and Factory metas were. Moving the AI rounds off the critical path was a good idea, since AI rounds were gimmicked for story reasons, which made them harder to design.
There weren’t too many guidelines on AI round proposals. They had to have a gimmick, a theme, and a sample meta answer that could be phrased as a feature request. Besides that, anything went. It turns out asking teammate to come up with crazy round ideas is pretty easy! In teammate parlance, an “illegal” puzzle is a puzzle that breaks what you expect a puzzle to be, and we like them a lot. We ended up with around 15 proposals.
The difficult part was doing the work to decide if an idea that sounded cool on paper would actually work in reality. One of my hobbies is Magic: the Gathering, and this issue comes up in custom Magic card design all the time. Very often, someone will create a card that tells a joke, or makes a cute reference, and it’s cool to read. But if it were turned into a real card, the joke wouldn’t convert into fun gameplay. Similarly, we needed to find the line between round gimmicks that could support interesting puzzles, and round gimmicks that could not.
For example, one of my round proposals was a round where every puzzle was contained entirely in its title. It would involve doing some incredibly illegal things, like “the puzzle title is an animated GIF” or “the puzzle title changes whenever you refresh the page”. There was some interest, but as soon as we sat down to design the thing, we realized the problem was that it was practically impossible to write the meta without designing the title for every feeder at the same time. The gimmick forced way too many constraints way too fast. So, the proposal died in a few hours, and as far as I’m concerned it should stay that way.
There was a time loop proposal, where the round would periodically reset itself, you’d unlock different puzzles depending on what choices you made (what puzzles you solved), and the meta would be based on engineering a “perfect run”. This idea lost steam. Given what puzzlehunts happened in 2022, this was really for the best.
In one brainstorming session, I off-handedly mentioned a Machine of Death short story I read long ago. In it, the brain scan of a Chinese woman named 愛 is confused with the backup of an AI, since both files were named “ai”. I didn’t think much of it at the time, but many people in that session went on to lead the Eye round, and I’d like to think I had some tiny contribution to that round.
The main round I got involved with was “Inset”, which you know as Wyrm. But we’ll get to that later.
A few weeks into this process, team leads announce that the four major story beats have been determined. They are designed to be discoverable in any order, and we need to deliver on metas for each.
- MATE is overworked.
- There are multiple AIs.
- teammate discarded all AIs except for MATE.
- Remnants of the AIs are still causing strange things in the Mystery Hunt.
It’s not known where all of these will appear, but some will for-sure be standalone metas in the Factory. We split into groups to brainstorm those, and the group I was in came up with:
The Filing Cabinet
Puzzle Link: here
I’m not sure how people normally come up with meta puns. What I do is use RhymeZone to look up rhymes and near-rhymes, then bounce back and forth until something good comes out. The brainstorm group I was in was focused on the “multiple AIs” story point. Looking for rhymes on “multiple” and “mate”, we found “penultimate”.
At which point Patrick proclaimed, “Oh, this puzzle writes itself! We’ll find a bunch of lists, give a thing in each list, and extract using the penultimate letter of the penultimate thing from each list.”
And, in fact, the puzzle did write itself! Well, the idea did. The execution took a while to hammer out. A rule of thumb is that there’s a 10:1 ratio for raw materials to final product in creative endeavors, and that held true here too. The final puzzle uses 16 feeders, and this was sourced from around 140 different lists. Our aim was to balance out the categories used, which specifically meant not all music, not all literature, not all TV, and not all things you’d consider a well-known list (like the eight planets). Lists were further filtered down to interesting phrases that ideally wouldn’t need to be spelled letter by letter, while still uniquely identifying their list from a single entry. The last point was the real killer of most lists. I liked Ben Franklin’s list of 13 virtues, but the words ended up being too generic.
Despite having the entire world as reference material, some letters (especially the Ps) were really difficult to find. I remember arguing against SOLID YELLOW for a while, saying its extract entry was ambiguous between “green stripe” and “striped green” no matter what Wikipedia said, but didn’t find a good enough replacement in the 20 minutes I spent looking for an alternative, and decided I didn’t care enough to argue more.
I feel every puzzle author relishes an opportunity to shoehorn their personal interests into a puzzle, and this was a good puzzle for doing that. FISH WHISPERER did not make the cut, but I knew it had zero chance of clearing the notability bar. MY VERY BEST FRIEND was a funny answer line that got bulldozed in the quest to fit at least one train station into the puzzle, which was harder than you’d think. Not a great showing for stealth inserts, but I’m happy WAR STORIES stuck around until the end.
Also, have a link to some Santa’s reindeer fanart and fanfiction. Testsolvers cited it as a source for “Olive is Santa’s 10th reindeer”, a mondegreen from people who misheard the classic song as “Olive the other reindeer used to laugh and call him names”.
April 2022
Round and Round and Round and Round!
![]()
It’s Wyrm time!
Wyrm took quite a while to come together, but was started in earnest around April. From the start, the round proposal was “really cool fractal art”, and the design around it was figuring out what an infinitely zooming fractal round could look like. This started with the metameta.
Period of Wyrm
Puzzle Link: here
Really, I did not do much on this puzzle. The mechanics stayed the same throughout all testsolves. I testsolved the initial version, and my contributions afterwards were on searching for feeders during round writing. I also wrote a script to auto-search for equations that would give a desired period. The script limited its search to linear functions, which was good enough most of the time.
I learned a lot about how Mandelbrot periods work during this puzzle. Although we suspected that writing code would be the way most teams solved this puzzle, we wanted the puzzle to support non-coding solutions, given it was required to finish the Hunt. A decent chunk of time was spent sanity checking the puzzle in online Mandelbrot set exploration tools.
Mandelbrot set periods are based on the “bulbs” along the outer border of the set. The central cardioid has period 1, and bulbs of any period can be found along the cardioid. Each bulb is self-similar to the original set, so instead of only going around the central heart, you can use the bulb of a bulb. For example, to get a period of 6, you either use a 6-bulb, or a 3-bulb branching off a 2-bulb, or a 2-bulb branching off a 3-bulb. Long story short, composite periods are easier than prime ones, which had a nontrivial effect on choosing what pun to use.
Qualitatively, the period converges faster if the point is towards the middle of the bulb, so we tried to do that when possible. We also aimed to use the largest bulb per period to reduce precision needed to solve the puzzle, and spread the points across the border of the Mandelbrot set, a holdover from an earlier version of the puzzle that hinted the Mandelbrot set less strongly.
The metameta was very deliberately designed to be flexible enough for any answer, as long as we had a good enough set of categories, since we expected to have a lot of constraints from the future metas.
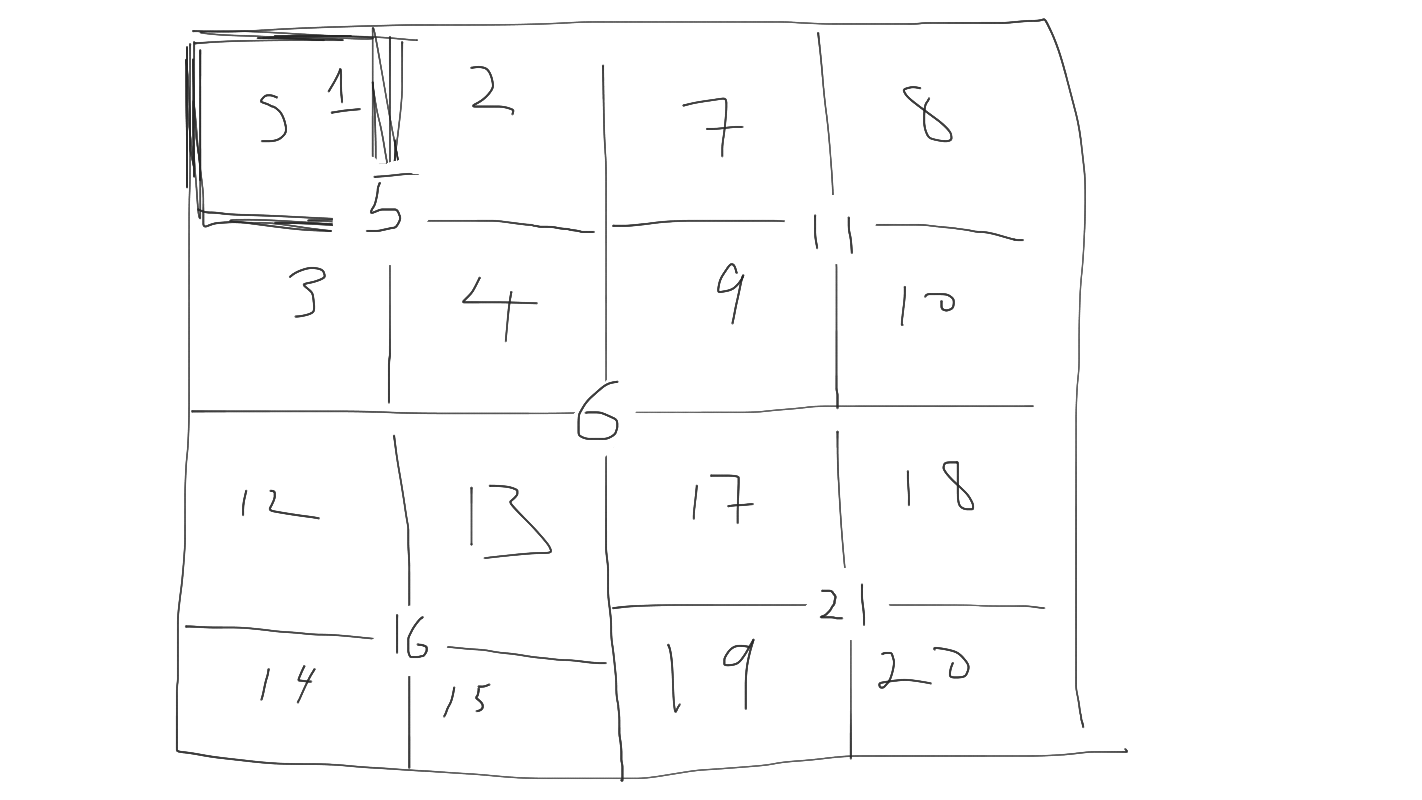
The round structure went through multiple iterations, done over Jamboard. Here’s a version where every puzzle would be 1/4th of a future puzzle:
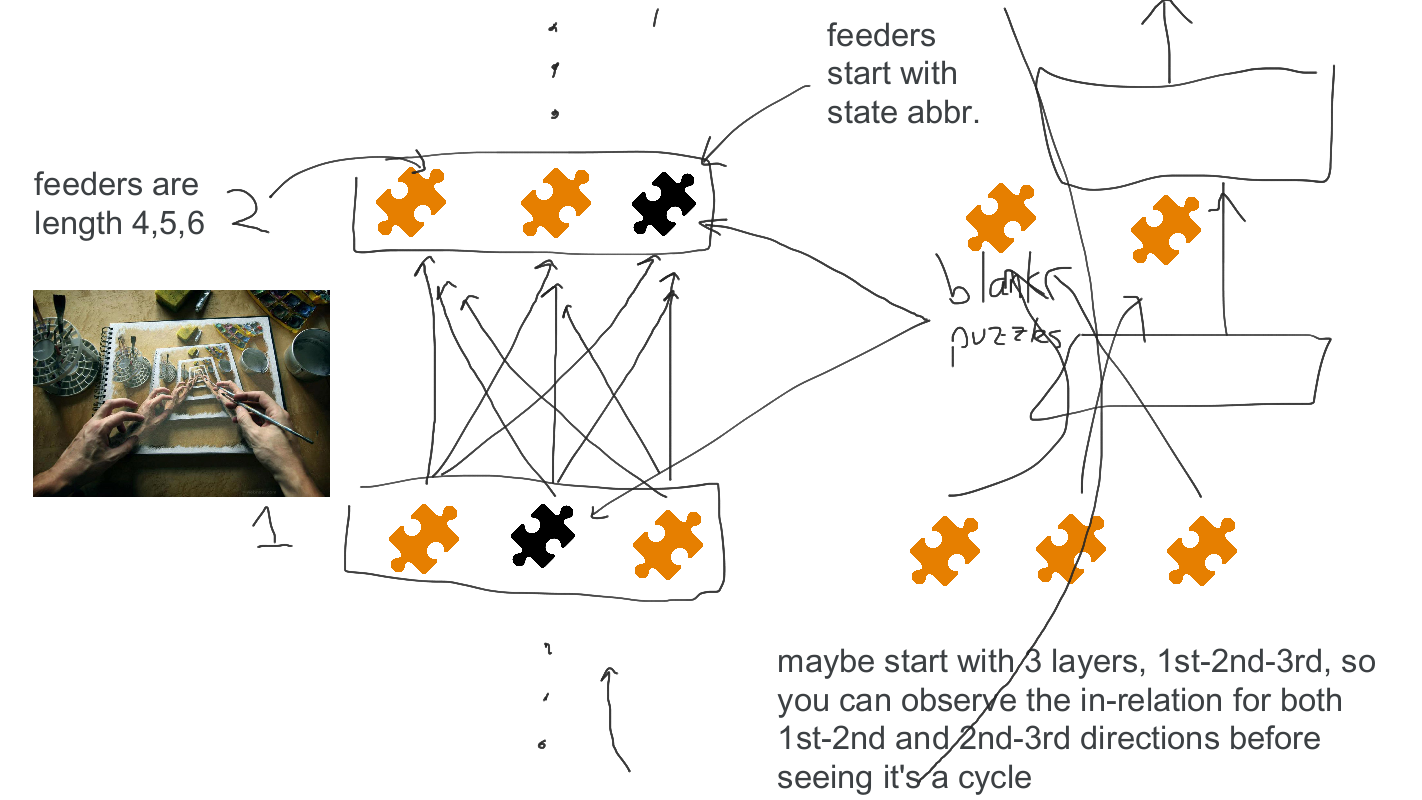
Here’s one where every puzzle’s answer would depend on answers from the previous layer, such that one puzzle could be backsolved per layer.
And here’s one where the entire round would be serial, each puzzle would rely on the previous puzzle’s answer, and you’d need to figure out how to bootstrap from nothing to solve the entire round.
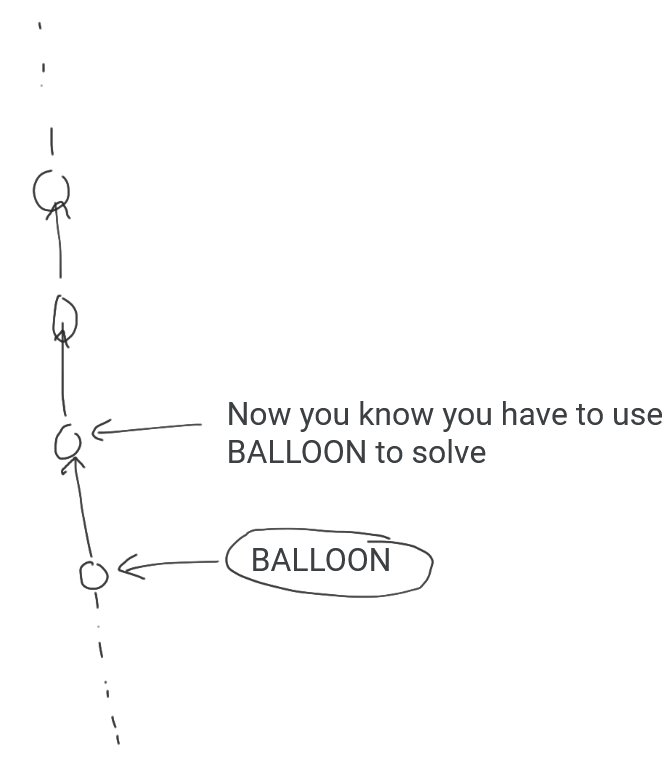
Most of these ideas would have been quite tricky to pull off, especially given we needed to fit it within the Period of Wyrm constraints. This led to the cyclic round structure proposal. Each layer would be normal puzzles, building to a meta, which would then be 1 pre-solved feeder for the next layer’s meta. The rounds would then form a cycle, where the last meta would be a feeder in the first layer. This restricted the “weirdness” to just the metas of each layer, and all regular feeders in each layer could be written without constraints besides the answer. The zoom direction of moving outwards rather than inwards was done to make it more distinct from ⊥IW.giga.
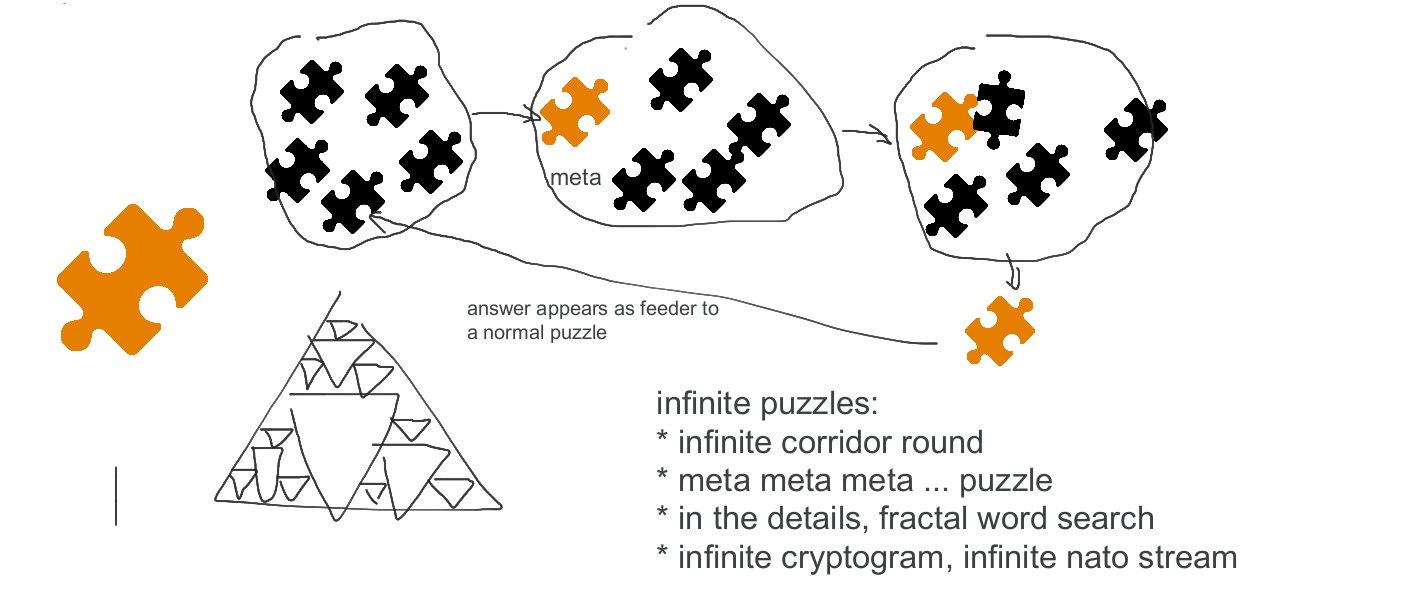
Our first plan was to have one unsolvable puzzle in the first layer of puzzles, that would become solvable once you got to the last layer of puzzles. This idea got discarded pretty early because it didn’t feel very impactful, it seemed hard to guarantee that a puzzle couldn’t be backsolved, and giving teams an unsolvable puzzle would be pretty rude. That led to the road of creating a metapuzzle disguised as a feeder puzzle, solvable from 0 feeders but still allowing for backsolving of feeders. Figuring out exactly what that meant would be a future problem.
Since I didn’t have any leadership responsibilities, and tech was still on the slow side, I ended up self-assigning myself a lot of work in brainstorming metas that fit the answer constraints. I noted that our Hunt had a lot of similarities to Mystery Hunt 2018: a goal to reduce raw puzzle counts, and including complex meta structures in their stead. As homework, I spent a lot of time reading through the solutions for both the Sci-Fi round and Pokemon round from Mystery Hunt 2018, since they also had overlapping constraints between metas and metametas. Going through each solution several times, I started to appreciate some 2018 metas that I found dull at the time, but which made the round construction possible when viewed through a constructor’s lens.
You can read more about the Wyrm answer design process in an AMA reply I wrote here. The short version is that all metas range between using answers semantically and using answers syntactically. The Period of Wyrm metameta forced semantic constraints, and the first Wyrm meta written (Lost at Sea) also used semantic constraints. This forced the remaining metas to be syntax based.
Over a few months, all the Wyrm metas were drafted and tested in parallel, using one central coordination spreadsheet to track the metameta categories used. Around 60 different categories were considered for the metameta, of which 13 were used, so more like a 5:1 ratio instead of a 10:1 ratio. Feeders were constantly shuffled between metas as we found better answers that satisfied the constraints, or changed meta designs to loosen their constraints enough to make feeders work.
We knew early on that some categories would be fixed. The category that led to INCEPTION was just too good as a “teaser” answer for the rest of the round, and got quickly locked in as the answer to Wyrm’s first layer. The FELLOWSHIP and EYE OF PROVIDENCE categories were locked in early as well, to fit the meta they went towards. My favorite category that didn’t make it was “Socialist”, for Social Security Numbers, using MONTGOMERY BURNS and TODD DAVIS. It got cut because we decided TODD DAVIS was a bit ambiguous with an “Athlete” category we were considering, and larger numbers would have forced awkward equations in the meta. Too bad, the juxtaposition of two capitalists getting labeled “Socialists” would have been great.
The other category we wanted to force was Hausdorff, since it was too thematic to not use. We wanted as many context clues pointing to fractals as possible, to reinforce the flavor of the round structure and metameta.
I factchecked the Hausdorff answers, which was a fun time. I’ll quote my despair directly.
aw man why have so many recreational math people tried to estimate the dimension of [broccoli] and cauliflower
[their] values are like +/- 0.2 the value from wikipedia
but that value is based on some paper someone put on arxiv in 2008 with 4 citations
put some notes in the sheet but in summary, of the real-world fractals, the most canonical ones are
1) the coastline based ones, because they were so lengthy that only 1 group of people really bothered estimating them.
2) “balls of crumpled paper”, which is usually estimated at dimension 2.5 and I found a few different sites that repeat the same number (along with 1 site that didn’t but the one that didn’t was purely experimental whereas the wikipedia argument is a bit more principled)
When I checked deeper, I found that the coastline paradox is well-known enough that multiple groups have checked the dimension of coastlines, getting different results, so those aren’t canonical either. The only one that was consistent was Great Britain, whose dimension of 1.25 is repeated in both the original paper by Benoit Mandelbrot and all other online sources I could find.
In my experience, factchecking is the most underappreciated part of the puzzle writing process. The aim of factchecking is to make sure that every clue in the puzzle is true, and only has one unique solution. The first is easy, the second is hard. Even with the puzzle solution in hand, it can take a long time to check uniqueness, on par with solving the puzzle forward. Although Wikipedia is the most likely source for puzzle information, Wikipedia isn’t always correct, and it’s important to verify all reasonable sources share consensus. You never know what wild source a puzzler will use during Hunt.
Sometimes, that consensus can be wrong and you still have to go with it for the sake of solvability! See Author’s Notes for Hibernating and Flying South from GPH 2022 for an example, or the Author’s Notes for Museum Rules from Mystery Hunt 2023. It’s unfortunate to propagate falsehoods, but sometimes that’s how it goes.
A Bay Area Meetup
teammate has people all over, with rough hubs around the Bay Area, Seattle, and New York. We held meetups at each hub in April, for anyone who felt the COVID exposure was within their risk tolerance.
We started brainstorming Weaver at the Bay Area meetup. Much of the work would be done later, but this meetup was the first time Brian mentioned wanting to make an underwater basket weaving puzzle, using special hydrochromic ink that dried white and became transparent when wet. The idea sounded super cool, so we did some brainstorming around what the mechanics should be (different weaving patterns, presumably), as well as some exploration into the costs. I then found an Amazon review.
I’ve tried a bunch of hydrochromic paints and they’re all kinda like this one. It’s a fun idea in theory – a paint that goes on white when dry and turns clear when wet, so you can reveal something fun on your shower tile or umbrella or sidewalk.
But… it doesn’t work great. It takes a pretty thick set of coats to actually hide (when dry) what’s underneath, and that makes it prone to cracking, and also not entirely transparent (more like translucent) when wet. It’s hard to get the thickness just right. Mixing some pigment into the hydrochromic helps a bit but adds a tint when wet. And even aside from all that it’s not very durable paint, it’s kind of powdery and scratches off. And you can’t add a top-coat, otherwise the water won’t get to it.
You can make it work, we did make it work for a puzzle application (invitation cards that reveal a secret design when wet) but I’d prefer not to use it again.
The Amazon review was written by Daniel Egnor. For those who don’t know, Dan Egnor runs Puzzle Hunt Calendar. This was easily the most helpful Amazon review I’ve ever seen.
Unfortunately, it suggested our idea was dead in the water (pun intended). This was super sad, but underwater basket weaving was too compelling to discard entirely, so Brian ordered some paint to experiment with later.
We then shifted gears to writing puzzles for the newly released Factory feeder answers, finishing a draft of:
Broken Wheel
Puzzle Link: here
This is one of those puzzles generated entirely from the puzzle answer. There were a few half-serious proposals about treating the answer as PSY CLONE and doing a Gangnam Style shitpost, but they died after I said “It’s been done”.
Alright, what is a Psyclone? There are two amusement park rides named the Psyclone, one of which is a spinning ring. How about a circular crossword that spins? That naturally led to the rotation mechanic. There were some concerns about constraints, but I cited Remy from Mystery Hunt 2022 to argue that it’d be okay to not check every square of the crossword. The entire first draft was written in a few hours, since we had a lot of people and it was very easy to construct in parallel. I guess that shouldn’t be surprising, since crosswords are easy to solve in parallel too.
Enumerations were added in the middle of the first testsolve because it was too hard to get started without them. As for the final rotation, we went through many iterations of flavortext and clue highlighting, before settling on placing the important clue first and mentioning “Perhaps they can be rotated” directly in the flavortext. “Rotated” in particular (over “spin” or “realigned”) seemed to be the magic word that got testers thinking about the right idea. It was a good reminder of how much subconscious processing people do in puzzlehunts.
“I Have a Conspiracy”
By late April, the round structure of Hunt had solidified.
- Five Museum rounds, that will combine into one metameta where both the metas and feeders are important. The metameta will deliver one story beat.
- Three Factory rounds, one of which will be about solvers “creating their own round” (this would later evolve into the Hall of Innovation). These will deliver the other three story beats.
- Four AI rounds, where the four AIs are locked in as Wyrm, Boötes, Eye, and Conjuri. There wasn’t a formal selection process for this, it was more that team effort needed to be directed elsewhere, and those were the four ideas with the most partial progress.
That gave around 150-160 puzzles. The writing team for teammate was around 50 people at the time and we thought we’d literally die if we tried to write a 190+ puzzle hunt.
There were two lingering problems. One, the Wyrm round was significantly larger than all the other AI rounds. Two, the story team was figuring out details of the midpoint capstone interaction. At the midpoint of the Hunt,
- Solvers should reactivate the old AIs.
- This causes teammate to shut down the Puzzle Factory and Mystery Hunt.
- Solvers should then start powering up the Factory by solving some puzzles.
- That is just enough to wake up the old AIs, who start writing their own puzzles, letting teams continue powering up the Factory until endgame.
The question is, what are the puzzles in step 3? This hadn’t been determined yet.
The Wyrm round authors and Museum metameta authors were gathered into a meeting with the editors-in-chief (EICs) and creative leads for a conspiracy: what if Act I feeders from the Museum repeated in Wyrm’s round?
This proposal filled a lot of holes.
- Wyrm’s round would be 6 puzzles shorter, bringing its size in line with other AI rounds. Between the repeated puzzles and backsolved puzzles, there would be around 13 “real” puzzles left.
- The reused feeders could become the puzzles in step 3. It would be reasonable for solvers to find copies of Museum puzzles within the Factory, since the Factory created puzzles for the Museum.
- The gimmick for Wyrm was in the structure, not the feeder answers. Out of the four AI rounds, it was the one most suited to repeated feeders.
- The overall hunt would require 6 fewer puzzles to write. The target deadline for finishing all puzzles was December 1st, and we were behind schedule. Reducing feeders was one way to catch up.
- If we could make that set of feeders fit 4 meta constraints (Museum meta, Museum metameta, Wyrm meta, Wyrm metameta), it’d be really cool.
Making this happen would be quite hard. The first step was Wyrm authors testsolving the Museum metameta, so that we knew what we’d be signing up for. After getting spoiled on MATE’s META. we discussed whether this was ambitious-but-doable, or too ambitious. It seemed very close to too ambitious, but we decided to go for it with a backup option of reversing the decision if it ended up being impossible.
It made it to the final Hunt, so we did pull it off. I’m happy about that, but given a do-over I would have argued against this more strongly. First of all, I don’t think many solvers really noticed the overlapping constraints. It leaned too hard towards “showing your team can solve an interesting design problem” without a big enough “fun” or “wow” payoff. (In contrast, the gimmicks of the AI rounds are much more obvious and easy to appreciate.)
The more problematic issue that was not clear until later was the way it delayed feeder release. Here is the rough state of Hunt at this time.
- The Office meta is done and its feeders are released.
- The Basement meta will go through more testsolving when the final art assets are in, but is essentially finalized and its feeders are released.
- All AI rounds are in the middle of design and are not ready to release feeders.
- Innovation and Factory Floor is doing its own crazy thing, and won’t be ready for some time.
In short, there were 2 rounds of feeders open for writing, and every other round was not. It is already known that Boötes and Eye will have answer gimmicks that make their puzzles harder to write, and Conjuri feeders will likely be released quite late since the meta relies on game development for Conjuri’s Quest.
The status quo is that all the Museum feeders can’t be released until five Museum metas pass testsolving, and all the Wyrm feeders can’t be released until four Wyrm metas pass testsolving. Including retests of both metametas with their final answers, this is 6 metas blocking Museum and 5 metas blocking Wyrm. Repeating feeders between Museum and Wyrm literally turned it up to 11 metas blocking both sets of feeders. There were 53 feeders in that pool, about 40% of the feeders in the whole Hunt.
Most of the non-gimmicked feeders were in that pool as well, leaving fewer slots for people who just wanted to write a normal puzzle. I don’t have any numbers on whether teammate writers were more interested in writing regular puzzles or gimmicked puzzles, but I suspect most of the newer writers wanted to write puzzles with regular answers, and did not have as much to do while the metas were getting worked out. (There was an announcement to keep working on puzzle ideas before feeder release, but it is certainly easier to maintain motivation if you have a feeder answer you’re working towards.)
I’d estimate that the extra design constraints from repeating feeders delayed the release of that pool of 53 feeders by 2-4 weeks. It forced more work on Museum meta designers who already needed to fit their meta pun and feeders into the metameta mechanic. Perhaps in a more typical Hunt, this would have been fine, but the AI rounds had already spent a lot of complexity budget and this probably put us in complexity debt.
But, this is all said with hindsight. At the time, I did not realize the consequences and I’m not sure anyone else did either. It did genuinely fix problems in the Hunt and story structure, it’s just there were other ways to fix them that would have had fewer bad side effects.
The Legend
Puzzle Link: here
Part of the deal for accepting the repeated feeders constraint was that editors-in-chief signed up to help design and push the Wyrm and Museum metas. The Legend was the meta brainstormed to take all the repeated feeders, and needed to be able to take pretty much any set of answers.
People say “restrictions breed creativity”. That’s true, but what they don’t say is that meeting those restrictions is not necessarily fun. It’s work. Rewarding and interesting work, but still work.
Before the decision to repeat feeders, I had sketched some ideas around using the Sierpinski triangle, after noticing INCEPTION was \(9 = 3^2\) letters long. The shape is most commonly associated with Zelda in pop culture, so ideas naturally flowed that way.

The early prototype associated one feeder to each triangle, extracting letters via Zelda lore. It was reference heavy and not too satisfying. After talking with Patrick a bit, he proposed turning it into a logic puzzle, by scaling up to 27 triangles, giving letters directly, and having feeders appear as paths in an assembled fractal.
This was especially appealing because it meant we could take almost any feeders, as long as they didn’t have double letters and their total length was around 50-70 letters. Brian, who was spoiled on some of the Museum metas, mentioned that TRIFORCE was a plausible answer for both the Museum and Wyrm metameta, so if we could make the Sierpinski idea work, we could do a “triangle shitpost” by making TRIFORCE the looping answer for the round.
Cool! One small problem: I’ve never written a logic puzzle in my life.
There are two approaches to writing a logic puzzle.
- Start with an empty grid and an idea for the key logical steps you want the puzzle to use. Place a small number of given clues, then solve the logic puzzle forward until you can’t make any more deductions. Add the given clue you wish you had to constrain possibilities, then solve forward again. Repeat until you’ve filled the entire grid. Then remove everything except the givens you placed along the way, and check it solves correctly.
- Implement the rules of the logic puzzle in code, and computer generate a solution.
Option 1 tends to be favored by logic puzzle fans. By starting from an empty grid, you essentially create the solve path as you go, and this makes it easier to design cool a-has.
Option 2 makes it way easier to mass produce puzzles if, say, you’re running a newspaper and want to have one Sudoku in every issue. Puzzle snobs may call this “computer generated crap” because after you’ve done a few computer generated puzzles within a given genre, you are usually going through the motions.
I knew I was going to eventually want a solver to verify uniqueness. So I went with option 2.
I have some familiarity with writing logic puzzle solvers in Z3, since I like starting logic puzzles but am quite bad at finishing them. My plan was to use grilops, but I found it didn’t support the custom grid shapes I wanted. Instead, I referred to the grilops implementation for how to encode path constraints, then wrote it myself.
Figuring out how to represent a Sierpinski triangle grid in code was a bit of a trip. The solution I arrived at was pretty cool.
- A Sierpinski triangle of size 1 is a single triangle with points \(0, 1, 2\).
- A Sierpinski triangle of size 2 is three triangles with points \((0,0), (0,1), (0,2), (1,0), (1,1)\), and so on up to \((2,2)\).
- A Sierpinski triangle of size N is three Sierpinski triangles of size N-1. Points are elements of \(\{0,1,2\}^N\). The first entry decides which N-1 triangle you recurse into and the rest describe your position in the smaller triangle.
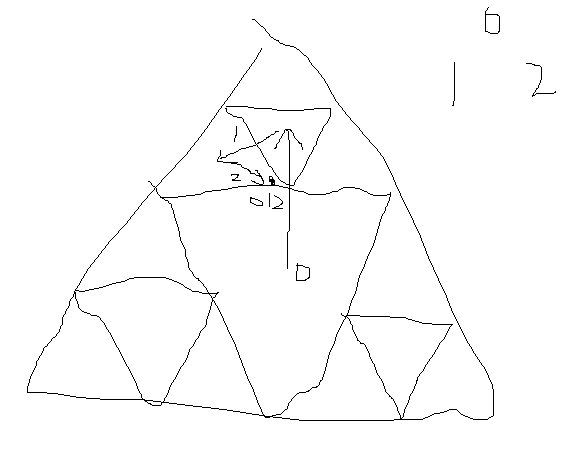
Checking if two points are neighbors can then also be checked recursively.
- If their first entries are the same, chop off the first entry and recursively check if the points are neighbors in the triangle one level smaller.
- If their first entries differ, they are in different top-level triangles, and the only three cases are \(0111-1110\), \(0222-2000\), and \(1222-2111\).

The first draft of my code took 3 hours to generate a puzzle, and the uniqueness check failed to finish when left overnight. Still, when I sent it to editors, they were able to find the same solution my code did by hand, so we sent it to testsolving to get early feedback while I worked on improving my solver.
Testsolving went well. The first testsolve took pretty much exactly as long as we wanted it to (2 hours with 5/6 feeders), and solvers were able to use the Sierpinski structure to derive local deductions that combined into the final grid. Not too bad for a computer generated puzzle! This was very much a case of “getting lucky”, where we discovered a logic puzzle format constrained enough that the solve path naturally felt a bit like a designed one.
I tried alternate means of encoding the constraint that every small triangle had to come from the given set of 27, and every triangle needed to be used exactly once. Swapping some ugly and-or clauses into if-else clauses got Z3 to generate fills 10x faster, but when switched to solve mode, it still failed to verify uniqueness.
At this point I decided to step in and mess around with different fills by hand. The goal was to minimize the number of triangles where 2+ letters were contributing to extraction. There were around 5 different fills with different feeder lists, and I suspect all of them were unique, but my solver only halted on one of them. I didn’t have much intuition for how to speed up the solver any more, so we stuck with that fill.
After that fill was found, there were only two revisions. The first was deciding how much hinting to give towards the Sierpinski triangle. This was the step with the largest leap of faith. In the end we decided to hint that the corners would touch only at vertices, and the final shape would be triangular, but no more than that.
The second revision was to make it a physical puzzle. In Mystery Hunt 2020, teammate got stuck on the final penny puzzle for 7 hours. This was quite painful, given that we had literally no other relevant puzzles to do, but at the end of Hunt we liked that we ended up with a bunch of small souvenirs that people could take home. We had already observed some struggles with spreadsheeting the triangle grid, and since The Legend was so close to the midpoint of the story, it seemed cool if we could give out physical triangles as a keepsake. They could serve double duty as puzzle aids and puzzle souvenirs.
I’m not sure if teams used the wooden triangles as a souvenir in the way we imagined, but I hope shuffling wooden triangles was more fun than manipulating spreadsheets!
May 2022
The Triangles Will Continue Until Morale Improves
The co-development of Museum and Wyrm metas was fully underway. The editors-in-chief created a “bigram marketplace” spreadsheet, listing every bigram that MATE’s META needed, along with a guess of expected bigram extraction mechanisms. All Museum and Wyrm authors coordinated over this sheet to make MATE’s META come together. Based on Museum meta drafts so far, editors ranked how tight their constraints were, and gave more constrained metas higher priority. The repeated feeders for Wyrm that we wanted in The Legend then got higher priority on top of that. Museum authors were asked to take 1-2 Wyrm answers each, to avoid concentrating them into one meta. Wyrm authors were fast-tracked to testsolves of the Museum metas, so that we could help brainstorm alternate answers that also fit the Wyrm constraints. Meanwhile, testsolves of The Legend were biased towards Museum meta authors, so that they could know a bit about what was going on. We did not expect to use each meta extraction mechanism an equal number of times, but ideally the balance is not too off-kilter.
I helped field questions from Museum meta authors. Yes, someone needs to take the answer GEOMETRIC SNOW, we know it’s not a great answer but haven’t found an alternative that fits the double O constraint. Yes, TRIFORCE can’t change. To help aid in feeder search, I wrote a script that attempted all Museum metameta bigram mechanics on all Wyrm feeder ideas so far, to see what stuck.
The feeder quality started pretty awful. After discussion with the authors of MATE’s META, editors add the glitch mechanic to that puzzle. Glitches erase parts of feeders before MATE’s META acted on them, allowing mechanics like “first + last letters” to have many more options. Feeder quality starts going back up.
Eventually this converged to a set of repeated answers for Wyrm that fit all Museum metas, and was a bit greedy at taking good bigrams, but not too greedy. As the bigram marketplace settles down and The Legend feeders get more locked in, we pivoted to dealing with our own constraints.
The Scheme
Puzzle Link: here
From the start of writing, we knew the meta answer was locked to EYE OF PROVIDENCE and it had to use the feeder INCEPTION in some way. There was a bit of brainstorming on whether we could exploit that 100% of teams would have the INCEPTION answer, but we did not come up with anything good.
The first serious idea I had for The Scheme was one I liked a lot. We weren’t able to make the design work, but I’m not willing to give up on the idea, so I won’t reveal it.
After that idea fell apart, we noticed that the Eye of Providence was depicted as a triangle, and we had triangles in The Legend, with a triangular looping answer, so why don’t we try to extend the triangle theming into this meta? It was a bit of a meme, but it would be cool…
When researching constrained metas, I found Voltaik Bio-Electric Cell, a triangular meta with a hefty shell that used the lengths of its feeders as a constraint. Well, we already had a 1 letter word in one of our feeders (at the time, it was V FOR VENDETTA). There was no length constraint on our feeders yet (meaning it would be easy to add one), and It seemed plausible we could make a full triangle out of words in our feeders.
We did a search for missing feeder lengths, tossed together a version that picked letters out of the triangle with indices, and sent it for editor review. I was fully expecting it to get rejected, but to my surprise, editors liked the elegance of the word triangle, and thought it was neat enough to try testsolving. (Perhaps the more accurate statement is that the editors knew the difficulty of the Wyrm constraints, most Wyrm metas we’d proposed needed shell, and this was the closest we’d gotten to a pure meta for Wyrm so far.)
The spiral index order was originally added because I was concerned a team could cheese the puzzle by taking the indices of all 720 orderings of the feeders. Doing so wouldn’t give the answer, but it seemed possible you’d get out some readable partials that could be cobbled together. With hindsight, I don’t think it was possible to get anything out of bruteforcing, but one of our testsolve groups did attempt the brute force, so we were right to consider it during design. We kept the spiral in the final version because it let the arrow diagram serve two purposes: the ordering of the numbers, and a hint towards the shape to create.

In PuzzUp, there was a list of tags we could assign to puzzles. This was to help editors gauge the puzzle balance across the Hunt. This puzzle got tagged as “Australian”. When I asked what it meant, I was told it’s shorthand for “a minimalistic puzzle, where before you have the key idea there’s little to do, and after that idea you’re essentially done.” Puzzles like this tended to appear in the Australian puzzlehunts that used to show up every year (CiSRA / SUMS / MUMS), and are a bit hit-or-miss. They hit if you get the idea and miss if you don’t.
One of the tricky parts of such puzzles is that you get exceptionally few knobs to tweak difficulty. This is a challenge of pure metas in general. The other tricky part of Australian puzzles is that solve time can have incredible variance. The first testsolve got the key idea in 20 minutes. The second testsolve got horribly stuck and was given four different flavortext + diagram combinations before getting the idea 3.5 hours later. The second group did mention the meta answer in their solve, when despairing about their increasingly bad triangle conspiracies. Watching them finish an hour later was the best payoff of dramatic irony I’ve ever seen.
Even in batch testing, where testsolvers solved The Scheme right after The Legend, no one considered using the arrangement from The Legend when solving this puzzle. A few teams got caught on this during the Hunt - sorry about that! The fact that The Legend triangle had an outer perimeter of 45 was a complete coincidence, and if we’d discovered that early enough it would have been easy to swap BRITAIN / SEA OF DECAY back to GREAT BRITAIN / SEA OF CORRUPTION to make the Scheme triangle 55 letters instead.
Maybe having an Australian puzzle as a bottlenecking meta was a bad idea. A high variance puzzle naturally means some teams will get it immediately and some teams will get walled, and getting walled on a bottleneck is a sad time. This is on my shortlist of “puzzles I’d redo from scratch” with hindsight, but at the time we decided to ship it so we could move on to other work. “You get one AREPO per puzzle” - I’d say this is the one AREPO of the Wyrm metas.
Lost at Sea
Puzzle Link: here
Nominally, I’m an author on this puzzle. In practice I did not do very much. The first version provided the cycle of ships directly, and tested okay (albeit with some grumbling about indexing with digits). By the time I joined, the work left to do was finding a way to fit in triangles, and finding answers suitable for the metameta. We were basically required to have triangles somewhere after The Scheme evolved the way it did.
I looked a lot into the Bermuda triangle, as did others, but none of us found reasonable puzzle fodder. So instead, we looked into triangular grids. Over a few rounds of iteration, the puzzle evolved from a given cycle into a triangular Yajilin puzzle where feeders were written into the grid and the Yajilin solution would give a cluephrase towards the rest of the puzzle and extraction.
It all worked, but the steps were a bit disconnected, the design was getting unwieldy, and we had a really hard time finding a way to clue all the mechanics properly in the flavortext. There were lots of facts about each ship that could be relevant, so the longer we made our flavortext, the more rabbit holes testsolvers considered. (It’s the natural response: if you get more data, then maybe you need to research more data to solve.)
My main contribution was suggesting we try removing the Yajilin entirely and brainstorm a different way to use triangular grids. The final version of the puzzle is the result of that brainstorm. I’m pretty happy with the way the puzzle guides towards the hull classification, self-confirms it with the ARB classification code being weird, and then leaves the number in it suspiciously unused if you haven’t figured out it’s important yet.
The other main contribution was helping find feeders. The first draft used MRS UNDERWOOD as a feeder, for indexing reasons. The answer worked, but was really not a good answer. The S in MRS was needed for extract, but it looked sooooooo much like a cluephrase for CLAIRE UNDERWOOD instead. Brian told me that it could be changed to just UNDERWOOD if we added a feeder that clued San Francisco, which fit the metameta, and had an S as its 5th letter. We collectively spent 5-10 hours doing a search for one, before landing on the “stories” idea with SALESFORCE TOWER or TRANSAMERICA PYRAMID. The puzzle was rewritten with SALESFORCE TOWER, went through an entire testsolve with zero issues, and then we learned that actually there are multiple Salesforce Towers in literally the final runthrough of all metas and the metameta. Oops. Thank goodness we had a backup answer!
June 2022
My Favorite Part of Collage Was When Teams Said “It’s Collaging Time” and Collaged All Over The Place
Wyrm feeders are almost ready for release. The Wyrm metas work. The shared feeders with Museum work. It all works, except for two action items:
- Write the 4th Wyrm meta.
- Do a batch solve of the entire round to get data on what it’s like to solve each meta sequentially.
We had meetings about the 4th Wyrm meta starting all the way back in March. The design requirements were pretty tight:
- The puzzle had to look like a regular Act I puzzle.
- It also needed to be interpretable as a metapuzzle.
- Feeders had to be used in enough of a way to allow for backsolving.
- At the same time, the puzzle had to be solvable without knowing any of those feeders.
The very first example for what this could look like was a printer’s devilry puzzle. Instead of each clue solving to the inserted word, inserting a word would complete a crossword clue with its own answer that you’d index from. The inserted words would then be unused information that would be revealed as the backsolved feeders once you got to the end of the round.
None of the authors were very excited by this, but it was important to prove to ourselves and editors that the design problem was solvable. Once we knew the meta answer was TRIFORCE, the idea died more officially, since TRIFORCE was 8 letters and we only had 6 feeders to work with.
Another idea proposed for this puzzle may have worked, but was basically impossible to combine with the Wyrm metameta constraints. That idea eventually turned into Word Press.
The key design challenge was that the puzzle needed to embed some process for backsolving. But, that backsolving process would look like unused information during the initial forward solve. If a team got stuck, they could rabbit hole on that unused information. The round structure of Wyrm only really worked if almost all teams solved the 4th Wyrm meta at the start of Wyrm. So, add two more constraints to the list:
- The puzzle should be very easy.
- The puzzle should be attractive enough that teams won’t skip it.
And thus our problem was harder. The ideas bounced back and forth for another few weeks, until we landed on a word web in late April. I immediately started advocating for it. Word webs are the closest thing to guaranteed fun for puzzlehunts, and were a highlight of the now-defunct Google Games. It solved our “solve from 0 feeders” problem, because spamming guesses and solving around hard nodes is just what you’re supposed to do in a word web. Teams would also be unlikely to get stuck in the word web, as long as we gave it enough redundancy, so it would avoid the risk of teams paying too much attention to the content seeded for Wyrm.
My main worry was that it’d take a while to construct. It was clear we could construct it though, so we tentatively locked it in. We punted on doing the construction itself until the other Wyrm metas were written, so that we’d know exactly what backsolve feeders we needed to seed in the web. Well, now those Wyrm metas were written. Time to reap what we’d sown.
Collage
The first thing I did was reach out to David and Ivan, the authors of Word Wide Web, to see if they had any word web tools I could borrow. David sent me a D3.js based HTML page that automatically layed out a given graph, with some drag-drop functionality to adjust node positions, but told me there was no existing interactive code due to time reasons.
I repurposed that code to create a proof-of-concept interactive version that ran locally. This quickly exposed some important UX things to support, like showing past guesses and allowing for some alternate spellings of each answer.
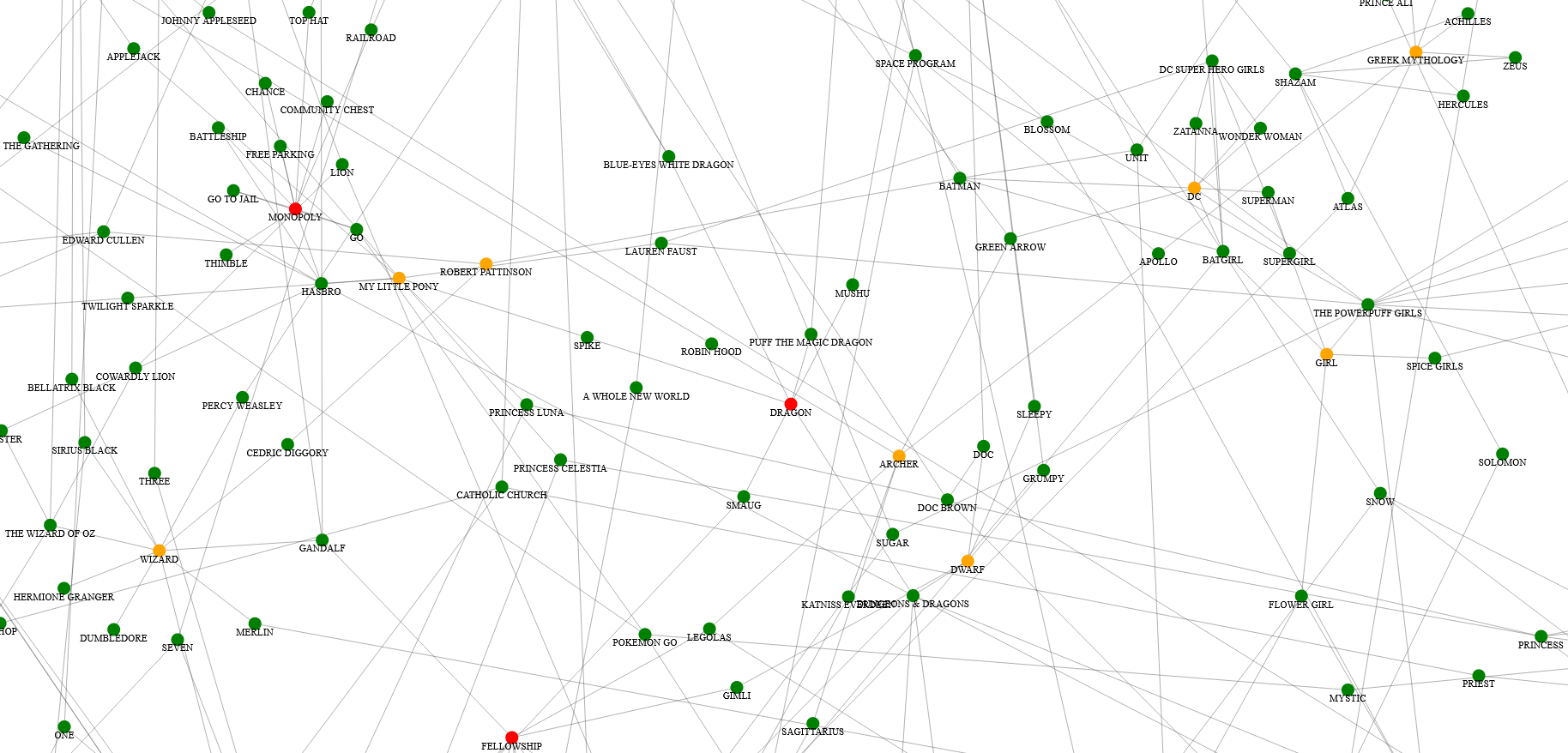
For unlocks, I decided to recompute the entire web state whenever the list of solved words changed. This wasn’t the most efficient, it could have been done incrementally, but in general I believe people underestimate how fast computers can be. Programmers will see something that looks like an algorithms problem, and get nerd sniped into solving that algorithms problem, while neglecting to fix their page loading a 7 MB image file it doesn’t need to load. (If anything, the easier it is to recognize something is an algorithms problem, the less likely it is to matter. The hard parts are usually in system design.)
In short, I figured recomputing the entire graph would be more robust, and didn’t want to deal with errors caused by messing up incremental updates.

(From “The Implementation of Rewind in Braid”)
From here, I worked on creating a pipeline that could convert Google Sheets into the web layout code. The goal was to make tech literacy not be a blocker for making edits to the word web, and to make it easier to collaborate on web creation. I added a bunch of deduplication and data filtering in my code to allow the source-of-truth spreadsheet to be as messy as it wanted, which paid off. Pretty sure around 10% of the edges appear twice in the raw data.
The process of coming up with the words themselves took a while. Collage is the first time I’ve ever made a word web, but my assumption going in was that word webs are best when there’s a high density of edges and vertices have large average degree. To get a sense for how big the web needed to be, I took the Black Widow web from Puzzle Potluck 3 and collected stats on how connected that web was. I then referred to various metrics to check how the density of the current Collage draft compared. I gave very serious thought to looking for my ancient spectral graph theory notes from college to estimate if the web was an expander graph, but decided that was overkill.
There was an initial “expansion” phase, where starting from the backsolve feeders, I put down literally anything I could think of. Other authors did the same. Then, after the web grew enough to have some collisions occur naturally, there was a “contraction” phase where I trimmed nodes that were hard to connect to the rest of the web, and future brainstorming was directed towards reducing leaf nodes in the graph. I’d estimate about 90% of the web is from me and 10% is from other people. This is why there’s so much My Little Pony and MLP-adjacent material in the web. I apologize for nothing.
After the prototype was tested a bit, it was time to get it into the site for real. I wrote some awful code to save and load node positions from the D3.js prototype, then set to work figuring out how to do teamwide live updates. This was my first time implementing websockets for a puzzle. (Websockets are a common approach for creating a persistent connection between user and server, where either the user or server can send messages to trigger events. We used them for solve notifications, the AI chats, and anything else where an update needed to trigger even if the solver isn’t doing anything.)
This was also my first time using D3.js, which made this puzzle have a lot of “firsts” for me. That contributed to how long this puzzle took to construct…but I knew I wanted to use websockets whenever I got to converting Quandle, and I wanted to use zoom from D3.js for the Wyrmhole round art, so I treated it as an investment.

Thanks to us reusing tph-site, it was easy for me to find websocket code examples from Teammate Hunt 2021. We had gone through a lot of pain making it easy to use in past hunts, so the end API I had to deal with was not as bad as I feared.
There was some danger in relying on such an interactive puzzle for a key part of Hunt. Websockets add complexity, and widen the set of things-that-can-go-wrong in the Hunt site. But, given that we were going to rely on websockets for chats with MATE, making Collage rely on them as well wasn’t adding any additional risk. MATE and the Wyrm metas were going to live together or die together, and we were going to bet on “live”.
Polishing and factchecking this puzzle was a nightmare. Turns out graph layout is a really hard unsolved problem. Even after turning the D3.js force graph parameters a bunch, I needed to do several adjustments by hand to clean up collinear points and reduce overlaps. The manual cleanup pass still missed some collinearity The click-to-highlight feature was added when I recognized that getting to 0 overlaps would not be worth the time investment. As for factchecking, the graph has over 300 words, and I knew there was no way we were going to exhaustively verify all O(N^2) pairs of those words. I think we got most of them, but I know a few slipped through (somehow no one noticed that “the princess bride” wasn’t connected to “bride”).
Across both testsolves, no one suspected the puzzle was seeding puzzle content, which I was happy about. Thanks to Patrick for suggesting a hardcoded threshold of 90% to solve the puzzle, rather than allowing the puzzle to be solved whenever all 3 neighbors of the goal node were revealed, since the latter usually happened by the 20% mark.

With Collage done, every Wyrm meta had gone through at least one clean testsolve, albeit with different feeders. That left doing one last batch test of all the Wyrm metas and metametas, with the finalized feeders for each. We debated back and forth on whether the batch test should testsolve the backsolving step of Collage. Given that the testsolve was advertised as a “test of the Wyrm metas”, it would be really hard to fit Collage into the test without arousing suspicion. The only test of Collage that seemed like it’d accurately model the real Hunt would be having the round page with prototype art, and having testsolvers test many random feeder puzzles, including Collage, before they tested the Wyrm metas. Those random puzzles didn’t exist yet, because they were waiting on feeder release. Which was waiting on testing the metas. Which wanted random feeder puzzles to exist first. And they didn’t, because the metas weren’t tested yet.
Who knew making an ouroboros-style round would make it hard to find a starting point?
There were strong arguments both ways, and the decision was to not test the gimmick. We would describe the backsolve step at the time the testsolve group unlocked the metameta, and we would push the backsolve test to a much later hypothetical full hunt testsolve.
The batch test was around 10 people who group-tested the Wyrm metas in sequence, starting with 4 feeders per meta and occasionally getting more if needed. When they got to the metameta, we gave them this diagram:
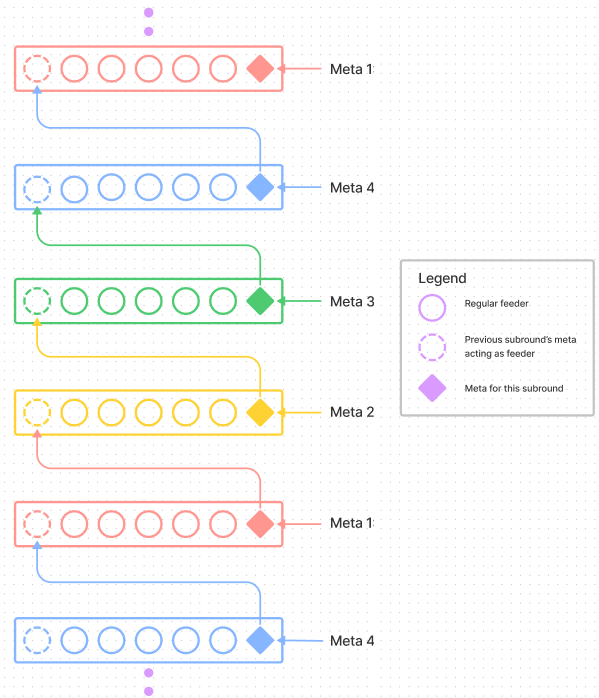
along with the backsolve feeders they would have had. We did redact the title of Collage to something else, because there was no reason to reveal which puzzle had the seeded content. The batch test went well, and we were able to release all the Wyrm feeder answers. The Museum metas finished shortly after, and this officially opened the floodgates for regular writing.
One last bit of trivia: the four Wyrm metas used to be named “The Legend”, “The Scheme”, “The Sea”, and “The Collage”. We ended up dropping the “The”.
The concern was that the pattern in the titles was too strong. With all the other context clues, if a team figured out that the round would loop, they could potentially solve the 3rd Wyrm meta immediately on unlock. We kept the pattern in mind as a potential nerf to make down the line.
(Two teams told me after Hunt that they suspected the Wyrmhole round would loop the whole time, but neither believed in it enough to attempt the cheese we were worried about. It’s always weird to talk about puzzle skips that people didn’t do. Sometimes I wonder if I shouldn’t mention them, because every solving tool makes it harder to design a solve path that cannot be shortcutted.)
With Wyrm metas resolved, the other major announcement was the plan for a teamwide in-person writing retreat. The goal was to get together, test drafts of physical puzzles and events, and start brainstorming AI round puzzles with very constrained feeders (like Boötes and Eye). There would also be a fullhunt testsolve of the start of the Museum. The retreat was scheduled for August.
However, the true goal of the in-person retreat was a more closely-held secret. And I was in the thick of that conspiracy.
July 2022
It’s Breakout O’Clock
“Breakout” was our internal name for what would eventually become the Loading Puzzle. It was the moment when teams would discover the Puzzle Factory hiding behind the Museum of Interesting Things. It was the goal we wanted all teams to see, and the key introduction to the entire story that would unfold over MLK weekend.
And most of the team was spoiled on its existence by February. How do you testsolve the discovery of something that you already know exists?
This is always the risk you take with structure-level gimmicks. The transition to discovering the Puzzle Factory was a key part of the theme proposal, which was heavily discussed early in the year. In general, it is okay for people to testsolve puzzles even if they know the answer to it already. It’s pretty easy to compartmentalize that knowledge. But for a gimmick this out-there, we wanted as accurate a test as possible.
The traditional answer to this problem is to recruit external testsolves. We tested the Teammate Hunt 2021 gimmick on a testsolve team from Galactic, and Galactic tested the gimmick of Galactic Puzzle Hunt 2022 on some people from teammate. This is a lot harder to do for Mystery Hunt.
To write Mystery Hunt, teammate did a lot of external recruiting. To get a sense of scale, we won Hunt with 53 people, not all of them decided to write, and we ended the year with about 60 writers and 70 people total on the credits page. My estimate is that around 30% of people joined after theme selection.
Any recruited person that joined after theme discussion was not spoiled on breakout. Although the Museum full hunt testsolve would use real puzzles, the true goal was to testsolve breakout on that group of 30%. After that testsolve, we’d treat the existence of breakout as not-a-spoiler and discuss it freely.
However, to make this plan work, the breakout puzzle would need to exist by retreat.
Loading Puzzle…
Puzzle Link: here
During one of the weekly general meetings, I was asked if I could join a brainstorm group for “a small puzzle”. Said brainstorm group had Jacqui (creative lead) and Ivan (tech lead).
Having been in the trenches with Jacqui and Ivan on many an occasion for tech-heavy puzzlehunt story integrations, I was 80% sure this “small puzzle” was breakout, and 100% sure it would be small to solve but take a stupidly long time to make. I didn’t mention my suspicions to anyone, I just said “sure”, but I’d like it on the record that I was right on both counts (and agreed to help anyways because it sounded like it needed help). I joined the breakout group in June and we didn’t finish until basically the day before the August testsolve at retreat.
Over the course of three months, we brainstormed how to create a puzzle that looked innocent at first glance, but became more suspicious the more you looked at it. A common theme in brainstorming was “peeling back the facade”. Those of you who have played a JRPG video game should know the feeling of talking to NPCs until you see all the dialogue, or trying to run over a waist-high fence and running into an invisible wall. We wanted something in that vein, that rewarded exploring the contours of the hunt site, surprising you when the contours broke instead of holding firm.
Many of the early ideas from this were unused, but got repurposed for the final clickaround of the hunt, MATE’s TEAM. For breakout, we converged towards something like a loading animation. The loading animation would represent MATE getting increasingly overworked trying to create puzzles, diegetically getting longer as teams solved puzzles and forced MATE to write new ones, and non-diegetically scaling up with solve progress to increase its obviousness and encourage teams to look more closely over time. The loading animation would appear on every puzzle.
As for the details? Boy was there a lot to figure out. Here’s a screenshot of the brainstorm spreadsheet.

There was a fairly serious proposal that the “hole” between the Museum and Factory would only exist on the puzzle page where you first solved the loading animation. The hole that appeared on the puzzle page would stay there, and although you could visit the Puzzle Factory URL directly, in-site navigation would rely on visiting the puzzle where you first solved the animation. I liked this a lot, but we dropped it due to complexity concerns.
Early prototypes were based on an infinite conveyor belt of pieces, except there would only be a few different ones. Screenshotting and assembling the pieces would spell out the answer, and entering it would cause the conveyor belt to break down. At the time, the answer was TERMINATE, due to its similarity to TEAMMATE.


Testsolvers rather this as “okay but not exciting, a bit too obvious when letters exist on the pieces”. This was revised to the version that went in the Hunt, which avoided showing letters directly by making the letters drawn in paths. Here is the original version we shipped to the August retreat.
Teammate Hunts have always had a rule that solvers can look at source code if they want, and Mystery Hunt usually has a similar rule. We have a lot of trust in our ability to hide things from the client and think it’s more fun if solvers can try to find secrets (and fail). For the loading animation, it meant the animation was drawn using CSS rather than a video file, with animation timing coming from the server. This way solvers could not right-click -> “Download Video” and solve the animation offline. The puzzle content behind the animation is also encrypted until the animation is solved.
Our testing process for this was pretty goofy. We would take groups of people spoiled on the existence of breakout, and tell them that we wanted to test the unlock structure and backend of the hunt website. The hunt site had many fake puzzles that would ask you to wait for 60 seconds, then give you the answer. We’d tell them the goal was for them to reach and solve the metapuzzle, which was impossible because they’d hit the infinite loading wall, and the testsolve would continue until they figured out the loading puzzle.

This testsolved correctly in isolation, but we knew the real test would be at retreat.
Meanwhile, we were working on the second part of the puzzle that would appear after the loading screen. There are a few principles that guide teammate’s approach to storytelling. I don’t want to put words in the mouth of the story team, but in my opinion the key points are:
- Decide on the story you want to tell, then make sure as much of the Hunt as possible echoes and is consistent with that story. This will take a long time to polish - do so anyway.
- Tie changes in narrative or story state to actions the solvers take. Usually this means attaching it to puzzle solves.
- Use bottlenecks to direct team attention towards the same point, then put the most important story revelations at those bottlenecks.
The breakout puzzle acts as the bottleneck into the Puzzle Factory, and we wanted to avoid one rogue team member solving the puzzle, finding the Factory, and leaving the rest of the team in confusion about what was going on.
Our solution was to have the second part of the puzzle be a “teamwork time” puzzle (borrowing a term from Mystery Hunt 2020), where collaborating with others would make it go faster. This evolved into the collaborative jigsaw seen during Hunt. Each user was required to enter STOP on the loading animation individually before they could access the jigsaw puzzle’s URL, to force a flow where early solvers would need to tell others how to break out of the Museum if they wanted to have collaborators or share what was going on. This would guide more people to experiencing the loading puzzle solution.
The collaborative jigsaw married three of the worst parts of frontend development: handling different screen sizes, live updates of other people’s actions, and non-rectangular click regions. Many thanks to Ivan for figuring out most of those details. Internally, every cursor fires a location update in websockets every 150ms, and the team-wide cursor state is broadcasted back to all viewers, using a spring animation to make cursor movement smoother by respecting momentum. The puzzle pieces are squares that have an SVG applied on top of them to cut them into the shape of the puzzle piece, with the SVG defining the click region for each piece. Custom hooks on mouse-enter and mouse-leave then track which puzzle piece the user is moving, which is also sent to the server and broadcasted back.

I played QA testing on checking it worked properly on Firefox and Safari, and debugging bugs like phantom cursors and puzzle pieces that claimed to be held when they weren’t. Fun fact: did you know that when you move your mouse into an element, browsers can sometimes fire a 2nd mouse-enter event in the middle of the first mouse-enter event? It’s true! It happens entirely randomly, causing you to see 2 mouse-enters then 1 mouse-leave all at once. I’m sure this won’t cause a bug that takes 5 hours to root-cause.
At one point, we planned to implement an adversarial UI, where pieces would wiggle out of their position, try to run away, and more. The story justification would be that MATE was trying to stop you from getting into the Factory. We ended up cutting this because it was more work. Also, in internal testing, a teammate trolled us by dragging a puzzle piece 5000 pixels down the page, and we decided we didn’t need to make solving the jigsaw any harder.
We did end up adding a max draggable range. Somehow this caused a problem in the live Hunt, where some teams dragged pieces outside of the draggable range and couldn’t move them again. I’m still not sure what happened there, because we tested it pretty thoroughly. I’m guessing something in the screen resizing logic caused problems? In any case, we had to figure out live on-the-fly fixes for this, which was exciting.
Around this time, hunt leadership mentioned we were even further behind expected hunt progress, and organized a teamwide “hack weekend” where each group would try to draft and testsolve a puzzle within two days. In said weekend, I helped write:
Museum Rules
Puzzle Link: here
There isn’t really too much of a story with this one. We looked at the pool of open answers, picked one of them, then brainstormed ideas based on that. That landed on breaking laws, which we’d justify in story as rules for attending the Museum. After the laws idea, the idea of extracting from Supreme Court seals felt like a more suitable way of using the puzzle information than just indexing. The puzzle presentation was stolen directly from Storytime in Teammate Hunt 2020 (as in, I found the code on my laptop and copy-pasted it into our Mystery Hunt repo).
I worked on creating the seal overlay extraction, Catherine did the drawings, and Harrison did the factchecking + research of weird laws. Harrison found that most weird laws did not have a solid primary source, but laws like “no killing a fly next to a church” were too funny to exclude. The urban legends were wrong, but they were at least consistently wrong, so we decided to perpetuate a bit of inaccuracy for the sake of solvability. Our sins are confessed in the puzzle solution. Other laws were deliberately misinterpreted for humor, like “no marathon dancing”.
My personal favorite weird law is that New York has a specific child labor law exception for working as a bridge caddie in a bridge tournament. We did not use it because it was just not going to be searchable. (I learned about it through someone at BEAM telling stories about verifying legal compliance.)
I do regret that we didn’t figure out a way to cleanly push to Supreme Court seals rather than state seals. The ambiguity came up in testing, and we specifically called out things that only existed in the Supreme Court seal when possible, but it was still a sticking point. We didn’t get around to revisiting ways to emphasize the relevant flavor more.
The hack weekend brought us back to the on-target trajectory, although it didn’t bring it back to surplus. More puzzles were needed, and I worked on two other ones in July.
Interpretive Art
Puzzle Link: here
As mentioned in the solution, this puzzle started from a shitpost someone posted on Facebook.
“First I was afraid, I was petrified.”
- person losing a fight with Medusa
Me: “haha. Wait this isn’t a bad puzzle idea.”
I mentioned it in our #puzzle-ideas channel, there was enough buzz to get a brainstorm going, and we were off.
One of the common tools a puzzle constructor reaches for is “does this have a small, canonical dataset”? Such things are easier to search and usually give a pre-built Eureka moment when solvers discover the canonical dataset. Accordingly, the first idea on this puzzle was to only use songs from the Guardians of the Galaxy Awesome Mix. It was a good intersection of pop music and alien interpretations of that music.
After I realized the GotG Awesome Mix did not have Never Gonna Give You Up or All Star, I decided using it was a bad idea, and we switched to “literally any popular song”. If you cannot meme in a puzzle, what are you even doing? An early version did not index words, and instead built up an eight word cluephrase by highlighting 8 squares of the fill. In testsolving, we didn’t like that only the clues crossing those squares “mattered”, so it was changed to indexing.
My proudest moment of the puzzle was in the first testsolve, where testsolvers solved NA NA NA NA NA NA NA NA NA NA NA HEY JUDE, and placed it while saying “what an absolute shitpost”. It was! It was also intentionally a way to break into the grid fill. A shitpost is only good if it’s a bit serious.
For a puzzle written so quickly, this puzzle got insanely high fun ratings in testing and seems popular with Hunt participants as well. Between this and Young Artists from GPH 2022, I suspect that any puzzle that riffs on pop music is going to be a fan favorite.
Conglomerate
Puzzle Link: here
Remember how I said I didn’t want to write minipuzzles anymore?
I still don’t, but editors asked if I could help contribute to a puzzle skeleton chuttiekang came up with. The ideas were there, it just needed more hands. Bending the rule to work on someone else’s minipuzzles was fine for me.
I ended up writing Birdhouse Kit, Camera, Microphone, Quilt, and Telescope, as well as a revision of Fishing Rod after the original mini failed. The sheer quantity of minipuzzles did make construction a bit difficult, since we wanted to avoid repeating encodings or extraction mechanisms. That left fewer options after we exhausted binary, semaphore, Braille - you know, the old standbys. The Quilt puzzle was computer generated. I wanted the puzzle done fast and figured people would forgive a computer generated Sudoku if it was just part of a puzzle.
This puzzle had more errata than I’d like. I think this is expected for minipuzzles. You have to make more content, so your exposure to missing something in factchecking is larger as well.
August 2022
Mining for Content
As the date for retreat approached, most of my work was on fixing parts of the Loading Puzzle. Still, there was time to work on other puzzles along the way.
Lost to Time
Puzzle Link: here
Whenever I wrote a puzzle for Hunt, I did a search in the devjoe index to double check it was not too close to a prior Mystery Hunt puzzle. This has built a bit of a “Alex is the Mystery Hunt expert” reputation. At one point, I got a message saying “I was told to ask you if you knew a puzzle about Canine or Cuisine?” I said “IDK why you were told to ask me, but yes it was called Bark Ode”, and it felt a bit like I’d answered my own question.
On one of my devjoe index searches, I opened a 1995 Mystery Hunt puzzle, and got really confused why the solution page redirected to devjoe’s domain. I posted a link in #puzzle-ideas and kept going on other work.
About a week later, Bryan said it was turning into a real puzzle, and I could join if I wanted because I’d be too spoiled to testsolve it anyways. The plan was to pretend we found all the missing parts of the 1995 Mystery Hunt in the Puzzle Factory basement. The core idea was to write puzzles with two answers, one for the 1995 Hunt and one for the 2023 Hunt, where knowing the 1995 answer would help in solving for the 2023 answer.
Given how niche the idea was, it seemed like a shame to leave any stone unturned, so we aimed to use as much of the missing content as possible. That meant writing 8 minipuzzles, based on the constraints given by devjoe’s writeup and the 1995 Hunt document. This definitely contributed to the length of the final puzzle. Even at planning time, we knew it was reallllly pushing it for a puzzle in Act II of the Hunt, but decided it could be okay if it was a one-off exception. In hindsight, I believe we were correct to use all the minipuzzles, but each minipuzzle should have been made much easier. At the same time, both testsolves were clean and gave the puzzle high fun ratings. I don’t think there was any way our systems were going to point us to revising this puzzle. I’m a bit disappointed this wasn’t solved more, but I understand given its length and placement in Hunt.
The minipuzzles I directly made were the conundrum and the screenshot of Rick Astley, but in general I helped out on the presentation of other minipuzzles and the meta. In the vein of Cruelty Squad, we spent a lot of time trying to make everything look as bad as possible. Well, “dated” would be the more accurate term. Every image in the puzzle was saved as a JPEG with lower resolution and maximal image compression. For the conundrum, I printed it out, cut it by hand, scanned it, then JPEG-ified the output because the scanner I used was too high quality. Last, we planned to run the video through a filter to add VHS lines, but this got dropped because none of the premade filters we found matched our desired aesthetic, and making a custom one was too much work.
For the newspaper puzzle, I briefly considered buying a newspapers.com subscription to track down the original newspaper used for the 1995 Hunt, and then realized that it would be much better if the puzzle did not encourage solvers to find the original. Hence the name “The Boston Paper”. That being said, I bet you could find what the original puzzle looked like if you dug hard enough.
It’s also interesting to write a puzzle that will potentially be broken if anyone finds more material about the 1995 Mystery Hunt. I’m usually rooting for better archiving. This is a rare example where I hope it stays in a steady state! I know an old Dan Katz post speculated whether an entire early Mystery Hunt could be a single puzzle in a modern Hunt. I think this puzzle shows that no, it can’t, but it’s kind of close.
As more prep for retreat, I did an internal test of a paper version of Weaver. I failed to understand the final cluephrase even with the correct extraction, so it got revised. I also remember commenting that it might be one weave too long, but we didn’t plan any changes before retreat. Brian had done some experiments with the hydrochromic paint he’d ordered before, believed he found a setup that would work, and was making a copy by hand for retreat.
Working on the Hunt Site
Hunt tech was also starting to ramp up. We had done many planning meetings about Hunt tech starting from the beginning of the year, but now we had a deadline: the hunt site needed to be in a good enough state to testsolve breakout.
Most of the hunt tech meetings were done async, although it became more synchronous as we had more work. Earlier, I mentioned that we planned to stay close to tph-site, but after seeing Palindrome’s release of spoilr, we revisited this plan. On a read of the code, Palindrome’s copy of spoilr had more team management than tph-site, and was more tailored to Mystery Hunt logistics. We still wanted to keep our frontend, so we decided to merge tph-site and spoilr into one codebase, then separate out the updates posthunt. Many thanks to Alex Gotsis for signing up to go through integration hell. Like most software integrations, the end result is a bit more complicated than both in isolation.
As mentioned earlier, one goal of a puzzlehunt tech team is to create good internal tooling. In a smaller Hunt, it’s possible for a small number of tech-inclined people to get all the puzzles into the Hunt website. In Mystery Hunt, this is less true, just because of the scale. We knew the end of Hunt writing would be busy with art and puzzle postproduction, so any tools we wanted were best planned and coded early.
Top of our list was improving our postproduction flow, given Palindrome’s comments that they had a postproduction crunch. It had been a bit of a grind for us too in Teammate Hunt. Ivan proposed an “auto-postprod” system. Given a Google Doc link, the tool would load the page, retrieve the HTML within the Google Doc, create a puzzle file based on that HTML, and auto-create a commit plus pull request for that puzzle. I said “sure”, not really expecting it to ever exist. Imagine my surprise when it actually got built!
It wasn’t perfect. It didn’t handle Google Sheets, it would sometimes timeout if a Google Doc had an especially large image, there was an issue with URL escaping at one point, and if it errored on a puzzle it would require someone to clean up git history before it would work again. Despite all of this, it was still quite helpful. Mechanically copy-pasting paragraphs from Google Docs does not sound like it will take that long, until you’ve done it literally thousands of times.
Retreat!!!
Retreat was held in a big AirBnB in the Bay Area. I took Friday off work to attend in person, and people from the East Coast would arrive throughout the day.
Friday of Retreat
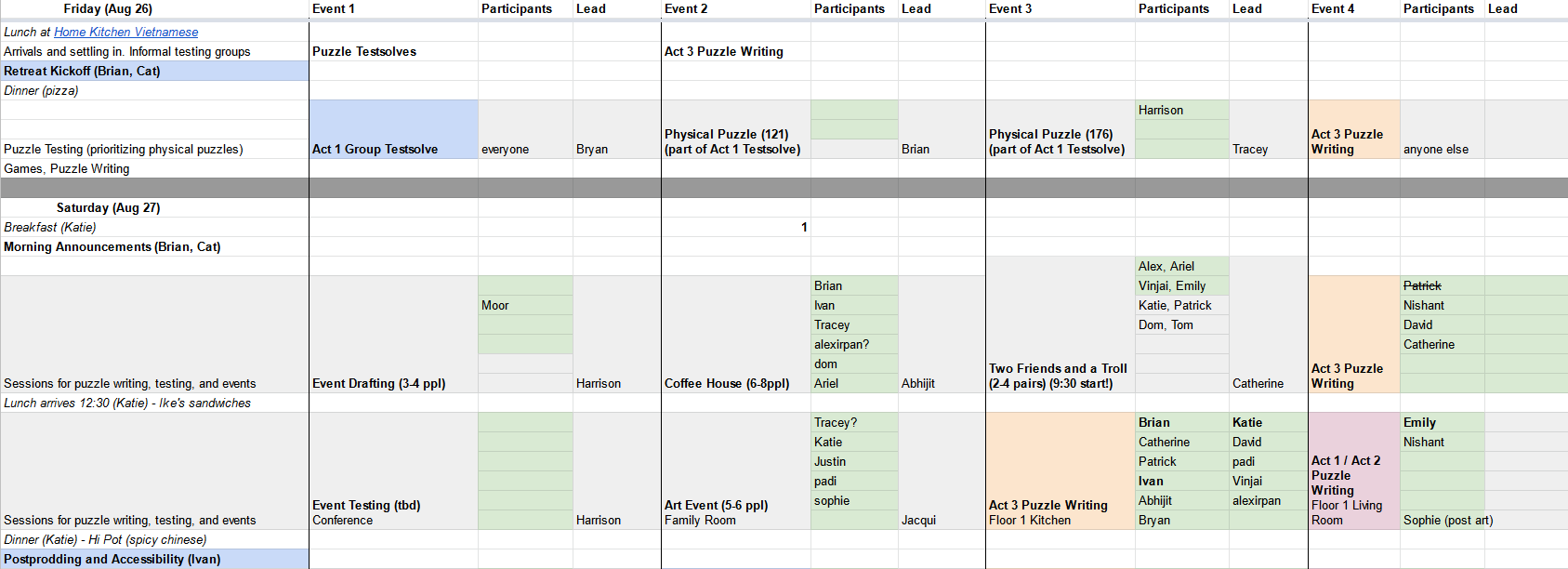
It was great to see people from teammate in person, given how many people I had only met over Discord voice calls. It’s really not the same as meeting in person.
As an icebreaker, we went around saying what our favorite puzzle was. I forgot what I said - I think it was A Puzzle Consisting Entirely of Random Anagrams? Vinjai said, “134”. Later I’d learn this was the puzzle ID for the Hall of Innovation and The Blueprint. He was one of the authors of that meta and it sounded like it was in the middle of taking over the lives of everyone involved.
Retreat started with a group testsolve of all the Act I puzzles and physical puzzles. Most physical puzzles were in Act I anyways, based on 2022 feedback that puzzles like Diced Turkey Hash were placed later than teams liked..
Almost immediately, we started hitting technical problems. The main issue was trying to connect 20 laptops and 20 phones to the same WiFi. It…did not work that reliably. I switched to using a WiFi hotspot from my phone. The other issue was that our testing server was fine for 3-5 people, and less fine for 20+. The setup for tph-site assumes it runs on a single VM, so we were not connected to an autoscaling service and needed to migrate on our own.
These tech problems made people assume that the loading animation was real, and that the site was just struggling. Which was useful data to have, it implied we really needed to land the prod version of the site. We also observed that when there were real puzzles instead of fake puzzles, teammates from teammate would get in the habit of opening every puzzle at once in a separate tab, then go back to a puzzle spreadsheet while waiting for the puzzles to load instead of watching the animation. That was not good. The loading puzzle was not getting solved and no one was suspicious. Jacqui tells me that two people who knew breakout existed tried to recruit her to “make the loading animation a puzzle”, and she had to find a way to deflect them from pursuing the idea any further.
In an attempt to get people to look at the loading animation more, the editors-in-chief nudged testsolvers towards puzzles that unlocked later (had longer load times). Meanwhile, on the tech side we did a number of deploys to “fix site bugs”, that was actually just increasing the time of the loading animation and encouraging solvers to refresh the site to get the “bug fix”.
An added part of the difficulty was that testsolvers were progressing through Act I slower than expected, so our loading times were low for much of testing. I can see some of you yelling, and yes, in hindsight, this was an early sign our difficulty estimates were off. But the main goal of retreat was getting one good testsolve of breakout, and the puzzle was not working. If that didn’t work, the entire Hunt design was in jeopardy. In comparison, many of the Act I puzzles were on their 1st draft and would likely get easier as they got polished or revised.
I think both of these arguments were correct. We were correct to focus on breakout and also correct to assume puzzles would get easier over time as they got cleaned up. The error was in estimating how much the solve time would drop in future revisions. The magnitude of the effect was probably smaller than we were hoping for.
In between trying to ramp up loading times, I testsolved many puzzles, including Exhibit of Colors (solved the flower puzzle and got the animal a-ha), Dropypasta (complained heavily about the old Pokemon Stadium mechanic - it got changed to what our testsolve group thought it should be), and Brain Freeze. At the end of Brain Freeze, someone asked why it had such a garbage answer, and I had to stay silent knowing it was from Wyrm and I was responsible for pushing that garbage answer into the Hunt.

After that, Collage got unlocked! Except, it was entirely broken. Oh no.
One meme in teammate during writing was “bamboozle insurance”. You offer bamboozle insurance when you want to assure people something will be true, and you pay bamboozle bucks when you are wrong. Example uses in a sentence:
“This meta testsolve needs 2+ hours but it will be worth your time, you can buy bamboozle insurance from me”
“Can I get bamboozle insurance the loading animation time won’t change, I’ll have to redo math if it does”
The nature of writing puzzlehunts is that you’ll be wrong quite often and I think everyone who offered insurance is in bamboozle buck bankruptcy. Here are some emojis we generated using DALL-E 2.

I bring this all up to say that I offered bamboozle insurance that Collage would be fine, and then it wasn’t. In my defense, it was fine when we testsolved it a few weeks ago. It turned out there was an issue where the loading animation was conflicting with the startup of the interactive puzzle content, and this caused the async initialization requests for Collage to never fire. We spun up a hotfix to get Collage working, and made a note to avoid interactive puzzles at the start of the final puzzle order. Unfortunately, this fed into the narrative of “the site is struggling, so the loading animation isn’t special”. It is the sort of thing where if you think about the loading animation for a bit, it does not make sense for a list of text to take longer to load than the loading animation itself, but that is not the mindset most people use unless you prompt them to.
The original plan was to get to breakout by around the evening (8 PM to 10 PM), then leave time for board games and socializing. But the evening came around, and it was still going. I was going to go pick up my parents from the airport at midnight, then come back to the AirBnB. With how the testsolve was going, I called my parents to let them know I wouldn’t be free, and they should make other plans. They did, and my parents informed me they tested positive for COVID the next day. Which left me with a very weird set of emotions around “I feel bad for cancelling on familial responsibility, but it’s good that doing so let me dodge COVID exposure, and it’s extra good I did not go to the airport and come back to bring COVID exposure to retreat”.
At 1:40 AM, the Act I testsolve was still not done, but it was officially put on pause to encourage people to go to sleep. Hunt exec + breakout authors then convened for a secret meeting in the basement. It felt a little like the Project Elrond scene from The Martian.

We concluded that all our intuitions about the loading puzzle were off, and it needed to be way easier, easy enough that we would not need to worry about the bottleneck it could have on Hunt. The additions we landed on were:
- Be much more aggressive on hinting with the messages MATE sent during loading. Instead of just giving a generic error, MATE would give messages that suggested the solution and say things like “It’s puzzling why this is taking so much time.”
- The original version shuffled pieces of each color to disguise the letter forms. This was partly done because we did not want the puzzle to be solvable from a screenshot of the animation, we wanted to require teams to look at the site to solve it. This was cut and the pieces were all shown in order.
By the time this was resolved and implemented, it was 4 AM. I went to go collapse on an air mattress so that I could be sort-of awake tomorrow.
Saturday of Retreat
The Act I testsolve was still running, but we did want to do the originally scheduled events. People could continue the testsolves in downtime, but were told to prioritize event testsolves and AI round puzzle ideation.
At this time, I was starting to get questions from friends about whether Mystery Hunt would be on-campus this year, and I still could not tell them anything besides “we’re working on it”. The tentative signs were pointing to “yes”, so we decided to plan as if we’d run on-campus, and events were correspondingly designed around in-person interaction. This was done knowing that the events wouldn’t be doable for fully remote teams, but, well…in my opinion, it’s called the MIT Mystery Hunt for a reason. I understand that not everyone can come in person and that this hurts accessibility, but after two years of remote-only events, it seemed appropriate to swing the pendulum back to in-person events. The event rewards were designed to be optional to finishing Hunt, to make sure fully remote teams were not blocked from getting to the end. Perhaps future Hunts will do more hybrid events - I’ll leave that choice up to future organizers.
We Made a Quiz Bowl Packet but Somewhere Things Went Horribly Wrong
Puzzle Link: here
Okay. I know this puzzle isn’t that popular, but all puzzles will have their stories told.
We were given the feeder answer for this puzzle, and after investigating various pyramid options, we landed on pyramidal quiz bowl questions. Some authors were fans of quiz bowl and it’s a puzzle-adjacent hobby. That got pyramid into the theming. The idea of extracting based on diagonalizing words based on a Hamiltonian path of the United States seemed like a good way to tie America into the theming as well. We spent much of the morning working out mechanics in more detail (how to connect answers to states, how to extract), and made a suitable quiz bowl question for the desired puzzle answer. Unlike regular quiz bowl, solvers would have access to the Internet, so we treated the puzzle as a “how well can you Google” puzzle. Since it was in an AI round, we decided to allow very obscure knowledge (which was one of the big causes of the puzzle’s length).
Originally, the plan was that every question would semantically clue a state in the Union. This was thrown out pretty quickly when we tried to tie DADDY LONGLEGS to South Carolina, and the best we could come up with was a South Carolinian high school’s rendition of the musical, which was a bridge too far.
A sketch of 4 sentences per clue x 48 clues was, in hindsight, a lot. Part of the justification was that this was not a puzzle that required a lot of context to make progress. It was something that parallelized well and was easy to jump in and out of. With other puzzles trending in the direction of serial deductions, it seemed okay to have a big puzzle that could run in the background.
Over the course of a few weeks, we started filling out the draft. It was clear that the puzzle skeleton would work mechanically, but we were quite unsure if the puzzle would be fun. For those unfamiliar with quiz bowl questions, the way they work is that they start obscure and become more obvious over time. Teams buzz in to interrupt the reader whenever they know the answer, which rewards teams with more obscure knowledge. But in this puzzle, you’d have search engines, and you’d have all text of all questions (albeit not in order).
It seemed like the solve process would be that you Googled every last sentence, which would immediately solve to the list of words. Then for every word, you’d find every sentence that looked like it could describe that word, and searched it to quickly verify yes vs no for each. That would work and everything would be reordered and then you’d be done. It felt pretty mechanical, where you didn’t have an a-ha anywhere and just shuffled words together until it solved. Like solving a jigsaw puzzle - not necessarily a problem, but probably not interesting.
Given the structure, the easiest place to add an a-ha was in the 1st step of Googling everything. That motivated the decision to obscure questions by pretending they were always talking about a location. In this way, although the bulk of the puzzle would still be Googling, you’d start with a global a-ha that the location theming was misdirection. Then every sentence would have a local a-ha in deciding how to reinterpret the clue. “Cryptic-like” is the right analogy here. Cryptics work because you need to decide what is wordplay and what is definition. Similarly, you’d need to decide what parts were straight and what parts were location wordplay.
This made the puzzle…a lot harder, which got corroborated by testsolving. To paraphrase, the feedback was “this was really fun at the start, then unfun after we got really stuck”. That is how most puzzles feel like when solving, but relative to those puzzles this puzzle was less fun to be stuck on because you cannot be saved by one good idea.
I’ve read a decent amount of negative feedback about the “all locations” aspect of the puzzle (some direct, some passive-aggressive). I am willing to die on the hill that it does improve the puzzle and shouldn’t be removed. The better fix is to keep the obfuscation and delete half the clues. This way the a-has are still there, but pairing is much easier and less grindy, since there are 1/4th the number of possible pairs.
After lunch, priority shifted from writing to continuing the Act I testsolve. The 4 AM fixes were
now on the testing site, but embarrassingly we had to do another hotfix because the loading
animation had an invisible <div> that made the answer box unclickable.
Solving of the last few Act I puzzles continued, and the pool of unspoiled testsolvers still weren’t solving the loading puzzle. From our #puzzle-ideas channel during retreat:
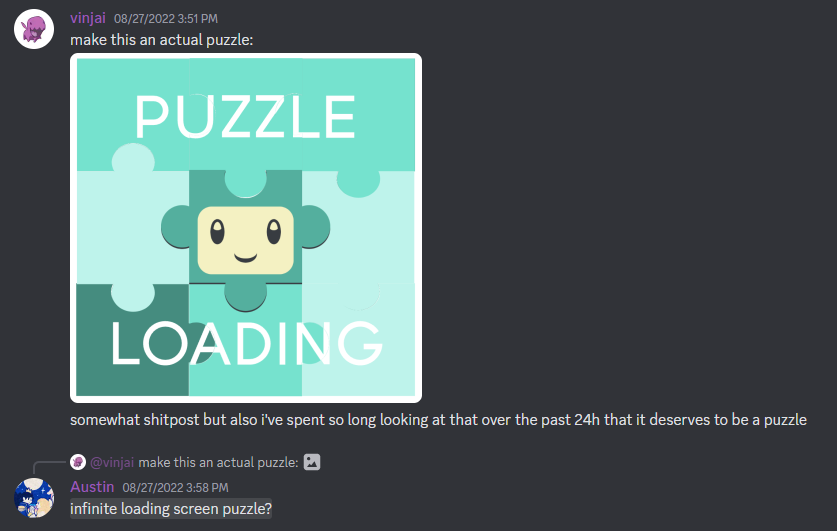
What the hell do we do? What nerfs are even left to apply?
I don’t think the relevant pool of solvers ever solved the puzzle organically. Instead, hunt exec, breakout authors, and a few unspoiled solvers were all shuffled into the same room where we had held our 4 AM emergency meeting. The unspoiled authors were told to look at the loading screen, and solved it in a few minutes. Their initial feedback was “yeah, this seems obvious, we should have noticed this earlier”, to which we said, “You say this, but we have 12 hours of empirical feedback saying the opposite.”
After some more Q&A on what made them believe it wasn’t a puzzle, reasons why they didn’t pay much attention to the animation, etc, we planned a few more changes:
- The four green dots (used to give an ordering on the letters) would be moved out of the answer submission box. Appearing inside the submission box made it look like the answer submission field was “loading” and could not be interacted with.
- Submitting an incorrect answer during loading would give a custom message (“Whatever you do, definitely don’t submit anything until it’s finished!”). Hopefully this would inspire some reverse psychology.
- MATE would become increasingly depressed as loading continued, to entice people to keep watching the page to see what would come next. We planned to add this in our Project Elrond meeting, but the art assets didn’t exist for it. (Much later, this led to the quote of “why does the animation look better when MATE is perpetually sad?”)

The most important consequence was the creation of the megahammer. Internally, “the hammer” was the threshold where teams would see infinitely loading puzzles. We envisioned this as the point that would force teams to solve the loading puzzle. “The hammer” was 7 solves, but would also be time-unlocked to reveal the loading puzzle and time-unlock the Puzzle Factory for all teams.
Retreat had shown the hammer was too weak. Hence, the megahammer. The megahammer was an email that would contain a video tutorial of how to solve the loading animation. The story team would figure out how to justify it, and we would send the email an hour after the hammer, to give teams some chance to solve the puzzle on their own before being sent the solution.
With all these changes planned, we assumed there was enough redundancy to go forward with the original plan of revealing the existence of breakout. After solving the loading puzzle, all “load times” were brought back to normal, and remaining testsolves could be continued without knowing the drama of what unfolded.
With breakout resolved, we could go back to puzzle brainstorming and wrapping up testsolves. The Teammating Dances event was written and tested entirely at retreat. Dinner arrived (I think it was Thai food?). After dinner, I joined a very-stuck testsolve of Tissues. At the time, it did not have the TetraSYS hint. We were given various hints towards “four” during the testsolve, and I mentioned there were four Greek elements (no idea why). I then said something along the lines of, “it’s a physical puzzle. We should do something that exploits the physicality”, and someone mentioned setting the puzzle on fire or dunking the tissues in water. “We should go do it, even though it’s likely not correct, because if it’s wrong the authors watching us right now will stop us from destroying the puzzle.” They grabbed the tissues to head to the sink, which gave the authors a bit of an aneurysm. “PLEASE DO NOT PUT THE TISSUES IN WATER why did you force us to clarify this??”
(Meanwhile the testsolver group for Weaver was putting the weave in water.)
After a number of other revisions, we were finally able to make it to the cluephrase of Tissues, but I decided to turn in for the night to catch up on sleep.
Sunday of Retreat
I woke up and continued the Tissues testsolve while waiting for other people to wake up. Some authors of Tissues were awake as well, and I did a few searches of “Nikoli + black cells” in front of them to prove I did not know what to do. They decided to try the cluephrase “DOKODESU”. I did searches of that and showed that no, whatever you’re going for is not enough. Eventually some combination of “Nikoli + dokodesu’s English translation + black cells” got there, but I still did not like it. I assume our testsolve was why this step got nerfed.
With more people awake, we proceeded with the scheduled State of Story meeting. The creative team presented the broad strokes of the Hunt story, the existence of breakout, our plans to make teams believe they shut down Mystery Hunt, and the art direction for each AI round. AI gimmicks were not revealed, since some still needed to be testsolved. Wyrm would be a precocious child that grew in length. Boötes would be a meme-y ASCII art cat in space. Eye would be a noble, biblically accurate angel, with nods to the Tower of Babel. Conjuri would be a pixel art owl eager for new challengers. Only Eye’s gimmick was spoiled widely at this time, since their puzzle ideas were most constrained and needed the most help for writing. The rest of the gimmicks were not spoiled to make testsolves of their puzzles act as if the team had not broken into the answer gimmick yet.
There was then time for a Q&A at the end. An audience member who did not notice breakout asked “what’s our plan if a team doesn’t notice breakout?”, which had incredible dramatic irony. We said we had a plan and moved on.
We did a final round of puzzle brainstorming and testsolving. I remember getting pulled aside to a puzzle brainstorm because we thought it’d be funny to write a puzzle with “the full house of Alexs over Brians”. (Alex Gotsis, Alex Irpan, Alex Pei, Bryan Lee, Brian Shimanuki.) We got in a room, tried to write a puzzle for l(a, spun in circles for an hour, and failed. The puzzle idea was officially killed a few weeks later. Some memes should stay dreams.
Retreat concluded with a bunch of board games. We played some rounds of Just Two. It’s Just One except a clue is only provided if exactly two people put it down. It’s good for large groups and is way harder. I’m told that when the word “pony” showed up, the only clue that made it through was “Irpan”.
East Coasters flew back home, and we ramped up the fall push for finishing Hunt.
September 2022
Ah Yes, Websites are a Thing
I’d say my main ramp-up on Hunt tech started around here.
There were a number of tasks to do, and the main one I took was handling the Wyrm round page. This ended up being a lot more complicated than I thought it would be. During Wyrm ideation, we discussed the Zoomquilt and its sequel as both art inspiration and proof-of-concept that we could make an infinitely zooming round page. (I remember Huntinality 2022’s registration form also came up.)
Art brainstorms for Wyrm had locked in a construction paper aesthetic, since every explanation of a wormhole in fiction involves sticking a pencil through two pieces of paper. There was a lot of work done for Wyrm on the art side. Turns out that if you want every puzzle to have its own icon, it doesn’t matter that 13 puzzles in the round are “fake” or repeats. You still need to draw 13 art assets. The art team considered reusing art assets for the repeated Museum puzzles, but it was hard to make the same image look good in both the Museum and Wyrm round pages, especially when the Collage art in Wyrm needed to be very detailed. Story-wise, this was justified as one being in “MATE’s Hunt” and the other being in “Wyrm’s Hunt”. Much of the ideation was on fractals, self-symmetry, repeating patterns, and so on.

With some discussion turning to fish tessellation patterns, tech was asked how hard it would be to support something where all fish of a certain type would link to the same puzzle, even if there were multiple fish in the round art. This would cause the click region to be both non-convex and disconnected, but tentatively we believed it would be doable.
I looked into creating a proof of concept for the round art and backend, using placeholder art assets. My first step was to copy the D3.js zoom code that I’d made for Collage.
Investing in learning D3.js was starting to pay off. To make it work for the round page, I stripped out the ability to drag the page, and the event listeners that responded to scroll wheel inputs. The user experience of scrolling down a page and then getting your scroll wheel eaten by the round art was not great, so I restricted the page to only work via hardcoded buttons. I also needed to figure out how to make the zoom level “roll over” once you passed the infinite threshold. I expected that to be a nightmare, and was pleasantly surprised when it really wasn’t.
Based on the barebones version, I asked if art could pick a fixed aspect ratio for all layers, along with always zooming in or out of the center of the art. They said yes. I hardcoded some placeholder puzzles to prove my server-side management worked at all stages of puzzle unlock. Then it was optimization time. Here are some comments from the time.
Based on the profiler call, current D3 setup is 11 ms to re-render all 4 layers when I do the 1 -> 2 zoom. (All 4 divs get re-rendered since they all look at scale variable). I set up the CSS transition for just layer 1 -> 2 and that was 8ms. The gap should get smaller when I make the CSS animation apply to all 4 layers.
So, in short, yes it’ll be faster, I’m not sure it’ll be appreciably faster. I’ll probably leave this for later based on the timing, in favor of some other things I need to fix in the prototype. But can keep it in mind as a performance win that may be more important when we have more assets in the round.
Performance optimization is not really in my wheelhouse, but it’s something we thought about a lot for Wyrm. To make the zoom work, we needed the zoom implementation to look seamless. The initial prototype was not. There was very noticeable pop-in as you swapped between layers, on both the background image and puzzle icons.
It 100% seemed like a solvable problem, given that Zoomquilt was seamless and I remember it looking seamless on 10 year old hardware. When I looked more closely, their code was based on using an HTML canvas. I was less excited about this, because HTML canvases don’t use vector graphics, and the default usage created weird rasterization artifacts when I tried using it in Collage.
I asked the tech people with more frontend experience for advice, and they helped explain
React’s rendering logic and where I could run a profiler. It turned out the problem was that
my prototype was taking fixed <img> tags and changing the src field based on what zoom level
I was on. This effectively forced the image to clear and re-render every time I crossed layers.
No browsers are built to do this seamlessly. I redesigned the layers to create all the
<img> tags for all four layers at once, then use CSS and JS to adjust the zoom and
z-index ordering of the static images.
This pushed the loading and drawing upfront, and the rest would just be image transforms, which
were relatively cheap.
This fixed the bulk of the performance issues.
Next was fixing the blurriness. That was easy. When I set up the prototype, I defined the zooms as \(1, 8, 8^2, 8^3\). I found that easier to think about, but it meant you would sometimes see parts of a 64x magnified image during transitions. It looked awful. I inverted the scale to \(1, 1/8, 1/8^2, 1/8^3\) and that fixed it.
The proof-of-concept now looked good enough that we were convinced the art concept was implementable, and I moved towards other work.
Feature Requests
From the start of the year, we’d been dumping feature requests and bug reports into our GitHub issues list. With less pressing puzzle work, I ran through all the features I knew I could do.
The first was improving our puzzle icon placement system. This also came out of Teammate Hunt 2021. In tph-site, icon placement is a field on the Puzzle model, meaning it’s saved in the database and can be adjusted live via admin pages. This made it possible to change positioning without a commit, but in Teammate Hunt 2021 it was kind of ass to alternate back and forth between the admin page and round page, refreshing to check every adjustment since the page did not live-refresh. To fix this, I coded a what-you-see-is-what-you-get drag/drop positioning tool. When logged in as the admin team, it drew this horrible, ugly red box that could be moved around. Dragging the box would drag the puzzle icon, and whenever it was dropped it would auto-save the new position and size info to the server. We’d then do one reconcile step at the end to export position data from the server and commit it into code.
The drag-drop tool had a bunch of bugs I never figured out, but I’d like to think it helped anyways.
I also did some work on postproduction of Quandle, to move the wordlist and game logic to server-side, and handled some of the revisions tied to breakout’s testsolve at retreat.
Galactic Puzzle Hunt 2022 ran around this time, notably with more tech issues than last time. In a spoilery discussion about GPH with some puzzlehunt devs, a dev from Huntinality shared a k6 load testing script they used for Huntinality, along with some optimizations and bug fixes they found in tph-site’s websockets code. I immediately made a note to test their bug fix later. The load test script in particular looks nicer than the hodge-podged Locust code I had written to load test the Playmate in Teammate Hunt 2020.
I also joined the brainstorm group for what we called the midpoint capstone puzzle, which you know as:
Reactivation
Puzzle Link: here
I’m on the author list for this puzzle but I really didn’t do much. I have said this before, but this time it is serious. I was in the first brainstorm meeting, where the creative team said they wanted each puzzle to be thematic to the AI. I shared some links to turtle graphics for Wyrm, which matched the repeating patterns idea, then stopped paying attention to the puzzle construction. That’s all I did.
October 2022
How About a Nice Game of Chess?
I was running out of burning puzzle ideas to work on. That was fine with me, I only wanted to work on puzzles that I was excited about. My plan was to work on token tech tasks the rest of the year, except for one puzzle, which would become much bigger than I expected.
5D Barred Diagramless with Multiverse Time Travel
Puzzle Link: here
I consider this puzzle my magnum opus.
If you want to solve a fun puzzle, go solve Interpretive Art. If you want a novel solve experience, go solve Puzzle Not Found. But, if you want a puzzle with spectacle that will strike fear into your heart, I can only recommend 5D Barred Diagramless with Multiverse Time Travel. It is very upfront about what you are getting into, and, to quote our Office art, “sometimes, the point of a puzzle is to be fun, but other times it’s to inspire fear”.
Okay I am exaggerating a bit for comedy. I think it’s long, but looks scarier than it is. Let’s start from the beginning.
The first draft of this puzzle was written in February for our internal puzzle potluck. I really liked the joke made by a team in DP Puzzle Hunt, and figured it could be a good puzzle if made for real. The first draft went all-out on extending the Clinton / Bob Dole crossword into another dimension. If I extended Joe Biden to Joseph Biden, then I could make JOSEPHBIDEN / DONALDTRUMP be the equivalent of CLINTON / BOBDOLE.
At this time, I had no plans to use 5D Chess with Multiverse Time Travel, since I knew nothing about how the game worked and had a limited amount of time before potluck. Most of my design time was spent on determining a placeholder extraction of any kind.
In this puzzle, some clues solve to two unordered answers. In any puzzle where this is true, you either need to find a way to order the pair, or use an extraction method that gives the same letter no matter how the pair is ordered. I first realized this when solving Split the Reference in GPH 2018, and have since noticed that pattern all over the place.
I read more presidential election Wikipedia articles (would not recommend), and noticed JOJORGENSEN was also exactly 11 letters. I mean, come on, you have to try doing something with that. This arrived at a “3 timeline” idea. Two timelines would be directly solvable from the crossword clues. Each two-timeline entry would then have a valid answer from a 3rd timeline, that would form valid words if placed into the grid. (i.e. CRAG / CRAW could be solved from the crossword clue, but CRAB would fit as well.)
This seemed like a horribly tight set of constraints, but I had no better ideas and went forward with construction. After reading even more presidential election Wikipedia articles (again, would not recommend), I found two other years where I could finagle three candidates that all had eleven letter names. It required dipping into the endless sea of 3rd party candidates and was awful, but it was good enough for a proof of concept.
The testsolve at potluck thought the grid fill was pretty fun. They got stonewalled on extraction, but aside from that it seemed promising. I dropped it to work on other puzzles (i.e. everything I talked about earlier in the post).
Fastforward to October, 8 months later. In a team meeting, the editors-in-chief mentioned we could use more crosswords in the Hunt for puzzle variety. Hey, I have an unfinished crossword idea! Let’s see if we can fix it.
I reflected on the design, and came away with these goals.
- As much as possible, I wanted the puzzle to look like a single grid. A 5D crossword can have many different projections into 2D space, but it should be viewable as a single crossword if you had a 5D perspective. More specifically, the given borders and black squares should match across all of the 2D grids.
- The potluck version extracted with just the alternate timeline entries. Once you figured this out about the puzzle, it’s the only part of grid fill that matters, and that’s a bit disappointing if you worked on other parts of the fill. (This was one of the bits of feedback I remember from writing Cross Eyed.)
- The other special entries in the grid were the time-dependent entries, that were only true in 1980 or 2004 or whatever. One option was to index into those entries to extract. To do so, I’d need to provide indices in some way, and I didn’t find a way to do so without giving away the a-ha that some entries were time-dependent.
- Really, it’s a shame the puzzle doesn’t use 5D Chess in any way, given how directly it’s called out in the title.
Remembering ✅ from GPH 2020, I considered the 5D Chess point more seriously. Suppose the puzzle did culminate in a 5D Chess problem. You’d want to solve the entire grid before doing the chess, because you’d want to make sure you found every piece. That made every clue matter. The puzzle would not need to label any of the special entries because it wouldn’t do any indexing for extraction. It would live up to the meme puzzle title. Thematically and mechanically, it just made sense to make it a chess puzzle. Since chess pieces could end up on any square, I’d need to make the crossword barred, and making the crossword diagramless would let me satisfy the first goal of keeping all given grids identical (since all 13x13 diagramless crosswords start off with a blank square).
Great, problem solved! Time to learn how 5D Chess works. How hard could it be?
Neither of the editors had played 5D Chess before, but they said this all sounded good and assigned me an answer from Boötes, with the reasoning that a 5D puzzle could accommodate a 2D answer. The answer I got had punctuation in it, which I agreed to try fitting into the puzzle. I played around with rebus entries, like cluing the screenwriter GAIL PARENT and filling it in the grid as GAI(T. The answer options weren’t great, but it wasn’t impossible.
The much bigger problem was the chess. Over the span of a month, I put increasingly deranged comments into the puzzle brainstorm channel, talking to myself about how 5D Chess worked and the constraints it placed on the grid fill. I’d say the default state of the editors was “confusion”, as I monologued my struggle learning 5D Chess to people who only sort of understood what I was struggling with.
I initially tried to learn the rules by watching gameplay videos. Within an hour I decided that it would be more efficient to buy the game, so I did. I mostly paid for Mystery Hunt with time. This was the rare puzzle that cost me money. Even now, I have yet to play a full game of 5D Chess with Multiverse Time Travel. However, I have played a bunch of the in-game checkmating puzzles, which are excellent and quite fun and are specifically constructed to teach you the rules.
After getting a basic understanding, I decided to have the puzzle only use bishops, knights and kings. Rooks were too boring in 5D, pawns could introduce questions about whether they had been moved yet or not, and queens were terrifying. A single queen in 5D Chess has, like, 60 possible moves. There are arrangements where if a queen and king are arranged properly, the queen can mate the king in 7 different ways. Trust me, using queens would have been a bad time.
To get early feedback on just the chess step, I ran some tests with a grid filled with random letters. What was immediately clear from those tests was that it was very easy for someone to skim a 5D Chess guide, believe they knew 100% of the rules when they only knew 50% of the rules, and then attempt to solve the chess puzzle with incomplete information. As a solver, there is really no way to distinguish “I do not understand the rules” from “I understand the rules and am just bad”. Like, they would be 50 minutes in, asking for hints, and we’d have a conversation like this:
“The future doesn’t exist yet” is such a great line. I recommend using it in daily life without context.
In response to the pre-test, I created some 5D Chess examples that could not be solved without understanding the basic rules of timeline creation and branching. This was part inspired by Time Conundrum, and part inspired by Cryptoornithology from EC Puzzle Hunt.
With this knowledge, the pre-test continued, and found valid checkmates that I’d missed during construction. At that point I decided that okay, I need to write code to verify my 5D Chess solutions, because I no longer trust my ability to verify 5D Chess by hand.
Using the game as a reference, I reimplemented the basics of the rules engine in Python, just enough to check mate-in-ones. I went back and forth between my code and the in-game puzzles to check my work. For timeline ownership, I skipped implementing it since I assumed it wouldn’t matter to the puzzle. This was a mistake, more on that later.
With this done, I worked on reconstructing the chess position. Having testsolved the meta for Boötes, I sent a question upwards: I know spacing is important. If I clue the answer directly, do my letters need to be aligned exactly like the answer? The editors sent this to Boötes meta authors, and the reply was: yes, if you aren’t using a cluephrase the spacing needs to line up exactly.
Well okay then I’m not going to be able to get the extraction to work that way, it’s too constrained on the chess side. I dropped the rebus ideas and switched to a cluephrase. I was worried it would be too hard to search, but editors tried it and didn’t have too much trouble.
During reconstruction of the chess position, I realized an important constraint that I hadn’t before. In chess, almost all pieces attack symmetrically. A knight can attack by going up or down, a bishop can attack along any diagonal. The only exception was the pawn, which I had already decided to exclude. This is true in 5D Chess as well. Suppose you have pieces in the same location in both timelines. Then, the checkmated squares across both timelines will also be identical.
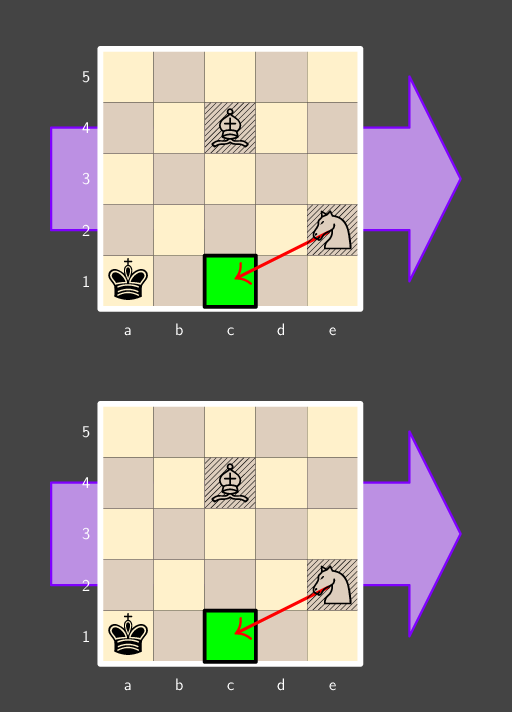
This is a problem for the puzzle, because letters are almost always the same between timeline, so your extracted letters are the same too. These symmetric mates forced letters to repeat in the cluephrase, and there were very few repeats to work with.
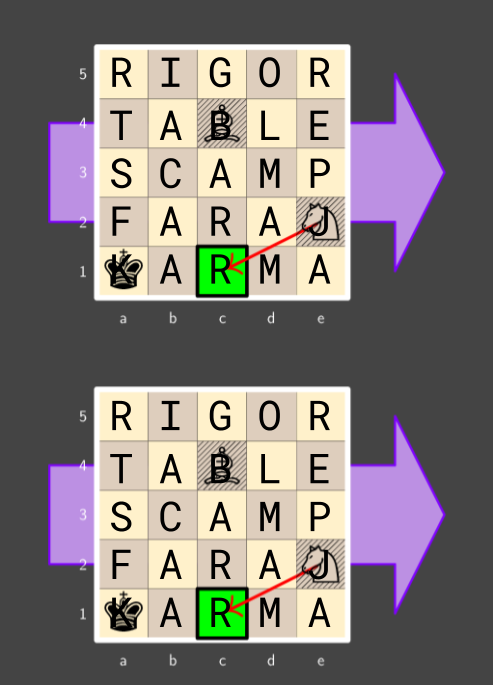
The only way to avoid this was to add symmetry-breaking by changing piece locations between timelines. This can only occur via the two-timeline entries. I was only planning to have 3-4 of those entries since each entry took a lot of real estate to support. (It’s about 25% of a grid per entry, once you account for the down crossings.)
Are you following me? If not, don’t worry about it. The short version is that every alternative timeline pair needed to satisfy one of the following:
- One has kings (K), the other does not.
- One has bishops (B), the other does not.
- One has knights (J), the other does not.
It also meant the crossword fill and chess problem could not be constructed independently. The puzzle needed to start from the two-timeline entries and their placement, and only then could the chess problem be made.
This is the only reason the 2008 entry for “Olympics host city” was BEIJING / BANGKOK. Bangkok failed in the very first round of IOC evaluation, and was never a realistic host city, but I desperately needed the Ks that BANGKOK would provide. Similarly the Kentucky Derby was picked for 1980 just because it was easy to find a historical winner with a K in its name.
For knights, this constraint also influenced choosing J for knights instead of N. Using N would have made grid fill way too hard, and J in particular appeared in both JOSEPHBIDEN / DONALDTRUMP and KENJENNINGS / LEVARBURTON to break symmetry. I wanted to use MAYIMBIALIK / LEVARBURTON originally, since it seemed fun to use “the Jeopardy host that isn’t Ken”, but it caused problems due to sharing a B in the same position.
With a better understanding of the requirements, I placed my seed entries in the grid, then wrote some code to greedily place kings until it had achieved 22 checkmates. It failed! The checkmate count went 17, 21, then got stuck. For reasons I don’t want to get into, there’s a parity issue in most 5D Chess grids that makes it hard to add an odd number of checkmates from just bishops and knights.
Hang on, 17 checkmates from one king? That had to be a bug. I added tons of debug print statements, and learned it wasn’t a bug. My brute forcer was running the rules correctly and had found a discovered mate, the kind that multiple teams got stuck on in the real Hunt.
I verified it in game, and went “holy crap that’s so cool.” But should it be in the puzzle? I tried banning my code from using discovered mates, and found it made construction nigh-impossible without placing a ton more chess pieces. That would make the chess step even harder, due to how many different moves you’d have available.
Essentially, I had two choices: use discovered mates and keep the search space to 30-40 possible moves, or ban discovered mates and make the search space 100-200 moves. I went with the former.
It was funny that I started with making the chess position by hand, switched to making it by code in the middle, and ended with doing a bit of both. I first placed the two-timeline entries to engineer a discovered mate, then had my code augment it to a 23 checkmate position, then fudged it by hand to push it back down to 22 checkmates. With this done it was finally possible to send it to another chess-only testsolve.
This testsolve went a bit better, but still had some trouble due to confusion on how to set up the chess problem and what “one move” meant. By this point the puzzle had evolved from “solve a crossword, get an answer” to “solve a crossword, congrats you’re 50% done”, and it felt like it was on the edge of being unreasonably long. I expressed these feelings of uncertainty to testsolvers, at which point they said that even though they had been stuck for 2 hours, 5D Chess was “exactly the bullshit I expect to see in Mystery Hunt” and I should keep it in the puzzle. I’d say a stronger statement is true: I don’t think this puzzle could exist outside of Mystery Hunt. The question was whether I wanted it to exist.
I think people believe that, like, I was super gung-ho about getting 5D Chess into Mystery Hunt, and I really wasn’t! All I wanted was a 5D time travelling crossword with a suitable extraction, is that so much to ask? All roads for that led to chess. There may be a world where the puzzle is just a 5D Chess puzzle, no frills, but I don’t think there’s a world where the opposite is true.
I kept the chess step, but added even more entries to the crossword fill to point towards the important 5D Chess rules. The intention was that no one should need to learn all of 5D Chess to solve the puzzle, just enough to get a readable extraction out. I was confident enough in the changes that I decided to go forward with completing the entire grid fill and testing the full puzzle on the next group.
Around the middle of the fill, I realized my placement of two-timeline entries had created some 1-wide columns, which I wasn’t too happy about. It wasn’t fully kosher to diagramless rules, but fixing it would have required regenerating the entire chess position that had already been testsolved…I decided I didn’t have time to fix it. Getting to this point had taken me a month, I’m guessing around 60 hours of work, and we had yet to do a single full testsolve.
In the first full testsolve, testsolvers’ initial reaction was “oh no”, which is pretty much what I was going for. The grid fill went great! The chess less so. I was discovering ever more exciting ways to play 5D Chess incorrectly, this time on how to arrange the timelines of the puzzle. Luckily TWO was already in the crossword, and I gave them a revision that was extra explicit about rules of 5D Chess they’d missed.
Once hinted towards the correct initial state, they were able to solve the chess problem without intervention. I’d say that was the first moment I started to believe the puzzle could pass testsolving and be done.
They did need to be given the total number of checkmates, which I initially did not give out of concerns you could use it to cheese the puzzle. If you find all squares that pieces could move to, and construct a regex to pull out exactly 22 letters, the extraction phrase is mostly readable from nutrimatic. Testsolvers told me that knowing they were missing so many checkmates was important for them to conclude that they were missing an important idea. Only 5 mates were findable without discovered mates, and you can assume that you’re missing 1-3 if you’ve made some mistakes, but missing 3/4ths of the checkmates forces you to eventually confront the possibility you’re missing an entire class of solutions.
The 2nd testsolve of the full puzzle went well. At this point the grid fill had been cleanly tested twice, and the chess step had been messily tested twice and cleanly tested once. I was looking to do a 3rd testsolve, but was told that our testsolve bandwidth was running low, and this puzzle did not need testsolves as badly as other puzzles did.
By this point, the puzzle had become a bit of a meme. I will admit that I deliberately cultivated that meme. About 1/3rd of teammate had testsolved it and another 1/3rd had heard a rumor that there was a “5D puzzle”. It was funny to realize that our hunt had a 3D puzzle in Some Assembly Required, a 4D puzzle in 4D Geo, a fractional-D cameo in Period of Wyrm, and now a 5D puzzle. “We have too many dimensional puzzles, non-2D puzzles are banned.”
The chess factchecking was easily the most terrifying factchecking experience of my life. When I’d set up my Python rules engine, I had ignored rules around timeline ownership in 5D Chess, but when I started factchecking I realized they were actually critically important to the correctness of the chess position. Now that I didn’t even trust my code to be 100% correct, I decided to install a 5D Chess mod that would let me load arbitrary game positions from JSON. Unfortunately, the game is hardcoded to only work for boards up to 8x8, so I could only verify parts of the puzzle in-game.
None of the testsolvers had bothered reading the rules around active and inactive timelines, nor had they checked any of these edge cases:
- Leaving a timeline unplayable for the other player by not moving in that timeline.
- Moving two pieces to coordinate a checkmate that was not doable by either piece individually.
- Forking two kings on an active board.
I did not realize any of these edge cases existed until after the puzzle had finished testsolving, and any of them could have threatened the correctness of the puzzle in a way that would have forced a complete rewrite of the chess position. The only recourse was for me to do what testsolvers had not: take my 90% knowledge of 5D Chess rules and do the work to bring it up to 100%.
It took me another month to analyze the puzzle enough to conclude that none of the edge cases were an issue. For the first, I had won a 50-50 coin flip with having black own the 2nd timeline instead of white. For the second, there were no issues, but I wasn’t expecting that to be an issue. The last edge case was 1 square away from being a problem, but wasn’t. In retrospect I think there was a 60% chance the puzzle was wrong, and I got very lucky I ended up in the 40% outcome instead.
In our PuzzUp setup, we can label puzzles by how difficult their postproductions will be. This puzzle was flagged as one of the hardest. The puzzle was short, but the solution was an 8000 word monster filled with diagrams that our auto-postprod tool failed to handle. Many thanks to Holly for factchecking all the crossword clues, and Evan for cleaning up all the chess diagrams with hundreds of lines of Asymptote code.
I’d say this level of excess is why I consider this my most important puzzle. It is this perfect encapsulation of what it’s like to fall down a rabbit hole by taking a joke way too far, and come out the other side with a coherent, self-consistent puzzle. Only two teams solved it forward, but given how many free answers there were and how scary the title is, I’m really not too torn up about it. I got most of my enjoyment from making it, not watching it get solved. (It helps knowing that one of the forward solvers said it made their top 5 puzzles ever.)
The one regret I have is the difficulty of finding the discovered mate. Testsolvers told me to keep it without hints, but I think there was a bit of positive bias coming from people who figured it out. As a standalone puzzle, I believe it is fine without changes. In the broader context of Hunt, including an example that was only solvable with a discovered mate would have made the ending a lot smoother and still given most of the a-ha.
November 2022
AH YES, WEBSITES ARE A THING
There were a…concerning number of things to figure out for the Hunt website.
A lot of it was classic stuff. Figuring out how to make the Factory round page meet the design spec, supporting different site themes per round, etc. The problems were straightforwardly solvable. There were just a lot of them and concerningly few people to work on them. My understanding is that a lot of people who planned to do tech were either busy with real life, or sucked into the Conjuri rabbit hole. This left a lot of infra tasks on the table.
For the Factory round page, Ivan had set up PixiJS, driven by a CSV file stored in Google Sheets. The source of truth for puzzles and interactive objects was stored in a spreadsheet. Artists would edit that spreadsheet, and our code would download it, parse it, and then compute what sprites should appear on the page and how they should move. This CSV was a nightmare, but was no less ugly than any other configuration system would have been. It was done over Google Sheets to get the tech team out of the loop of icon positioning. Later I learned we’d independently recreated a system similar to one used in Super Smash Bros. Ultimate’s development, although they used Excel instead of Google Sheets.
The Factory round page seemed well handled, so I offered to go more all-in on other tasks, starting with events.
Events
We decided events would act like globally unlocked puzzles, with some event-specific metadata to manually open them when the event was completed. Although events would not contribute to a meta of any kind, having them act like a puzzle with an answer was the easiest way to handle accounting of which teams had solved the event. We would not need to track which teams showed up to each event. Instead we could just announce the answer and watch the submissions come in later. Every recent Mystery Hunt has used this system. It just works.
If there is no events meta, what should events do? Editors-in-chief decided that events should act as either free answers (manuscrip) or free unlocks (Penny Passes). Free answers would only be usable in non-AI rounds, and free unlocks would be usable everywhere. We wanted event rewards to be useful at all stages of the hunt, but didn’t want teams breaking into the AI round gimmicks by redeeming free answers.
(Ah yes, what a solid argument, I’m sure no one will use free answers in AI rounds and things will go exactly as planned.)
I asked some pointed questions about edge cases. How do free unlocks affect meta unlock? Is all of Museum one round for unlock purposes or not? The real reason I was asking was because I wanted to figure out the implicit requirements list for the next major task.
Unlock System
gph-site and tph-site use a concept called “deep”. This comes from Mystery Hunt 2015, and the name stuck. In any case, “deep” is a measure of how far you are in a Hunt, and is used to decide when puzzles should unlock. How that works can be done in different ways.
Mystery Hunt 2022 chose to have a fixed, single track unlock order. All puzzles, both feeders and metas, were on that track. Mystery Hunt 2021 had per-round tracks, where each puzzle gave a lot of deep to its round, and some deep to other rounds. In that hunt, deep was called JUICE.
Our Hunt was looking like it would be more like 2021. AI rounds were going to have independent unlocks, since in-story each hunt was written by a different AI. But, we did want to track total AI round solves, to decide unlocks of new rounds and change the speed of animations in the Puzzle Factory. The Museum was slated to have a shared unlock track between all rounds, but with a min-solves-in-round threshold for metas. Factory rounds were going to be mostly normal, but would be slightly entangled with Museum solves to decide the initial round size (a team that solved the loading puzzle later would have fewer Museum puzzles left and should get to unlock more Factory puzzles).
The desired properties were changing quickly, and I decided that, you know what, we don’t know what our unlock system is yet. So, I am just going to implement the most generic unlock system I can think of. I arrived at what I’d call the “deep key” system.
- Every puzzle has a deep key (an arbitrary string), and a deep value (an arbitrary integer). A puzzle unlocks if the team’s deep for a deep key is at least their deep value for that key.
- By default, solving a puzzle contributes 100 deep to the deep key for its round name.
- This default can be overwritten at either the round-level, or the puzzle-level if certain puzzles need to do special things for unlocks.
- Puzzle solves can contribute any amount of deep to any number of deep keys, but puzzle unlocks are required to rely on just one deep key.
To justify this system, I gave examples of how to implement all of the proposals.
- Museum rounds: Every museum puzzle contributes 100 to “museum” and 1 to “X-meta” where X is its round. The meta for each round has deep key “X-meta” and all other puzzles have deep key “museum”
- AI rounds: each AI round puzzle contributes 100 to its own round and 1 to “act3-progress”. New AI rounds unlock at N act3-progress.
- Breakout / Loading Puzzle: all starting Museum puzzles contribute 1 to “factory”, and the starting set of Factory Floor puzzles could open at 1/2/3/etc. depending on how we wanted to balance the start of the round.
This is essentially a generalization of deep. Each puzzle’s database entry only needs to store 2 fields (deep key + deep value for that puzzle), making it easier to scan in Django admin. The heavy lifting of the unlock logic would be in Python. In the design notes, I mentioned that arbitrary string keys could potentially be hard to maintain, but I expected us to have at most 20-30 different keys and for the key names to be mostly self-explanatory.
I didn’t get any pushback on this proposal, and spent a day or so implementing it. Along the way, I implemented a “deep floor” system, to use for time unlocks. A deep floor is a database entry that says, “team X (or all teams) should always have at least Y deep for deep key Z”. Floors were created in a default-off state, then turned on manually whenever we wanted to unlock something. I also set up a magic endpoint that a team could hit to opt into a deep floor, to recreate the optional time unlock system that Palindrome had in 2022. (I asked Palindrome’s team where this was implemented in their codebase, and they told me it was implemented very rapidly during Hunt and I should just redo it on my own.) This opt-in unlock flow wasn’t finished before Hunt, and did not get used.
One important point of clarification: in our Hunt, there are actually two tracks of progress. One is deep, and describes puzzle solve progress. The other is story state, and tracks progress in the story. The two tracks were handled independently, and this would be the source of many fun bugs throughout the year.
Reactivation State Changes
Before I finished setting up the flow for automatically creating deep floors for all teams that could use them, Ivan reached out and asked if I could help on making the Hunt “feature complete” by December 1st. This was an internal deadline we’d set for creating a minimally viable Hunt, where a team could go in, solve puzzles, progress through the Hunt story, and reach the end of Hunt (assuming they solved all puzzles immediately).
When I looked into the TODOs for Wyrm and the midpoint of Hunt, there was a rather terrifying list of things to implement.
- How do we represent repeated Wyrm puzzles across the Museum and Wyrmhole?
- How do we handle physical puzzle pickup and other team interactions?
- Reactivation includes an unscheduled interaction with the team, how do we do that?
- Shutting down the Factory, and connecting story state to Factory display logic in general.
- Implementing teamwide dialogues and connecting their resolution into updates to unlock and story state.
I decided to take the Reactivation and Wyrm issues, while Ivan set up the dialogue and Factory logic (“it’s just Kyoryuful Boyfriend all over again”).
The Reactivation logic was wild. The plan for the midpoint story flow was:
- Teams talk to MATE as they reconnect the old AIs
- Mystery Hunt gets cancelled.
- teammate stops by the team HQ for the in person interaction.
- Only after this point should teams unlock anything tied to Act III.
Note there are 0 puzzle solves between any of these events. It all needs to be handled via story state triggers.
Tied to this was supporting live updates of round pages without requiring page refresh. This was originally labeled as an “optional but nice to have” issue, but I raised the point that shutting down Mystery Hunt would not work if the site didn’t live-update. Imagine that you talk to MATE, and the conversation stops, but the Factory is still brightly lit and everything is interactable. Only when you refresh the page does everything go dark. Doesn’t that really break the immersion?
Ivan went “oh shoot you’re right” and we immediately bumped it up to site blocking. To support it, I wanted to make as few changes to our site code as possible. The frontend gets its state initialized by an API call against the server that populates various React components. The solution that would change frontend code the least was adding a websocket-based trigger that said “resend your initial API call and update your component state with the reply.”
“Wait, do we need to worry about self DDOS-ing our site”?
Assuming an entire 100-person team was watching the story, we’d get a quick burst of 100 requests. That seemed fine. If every tab from that team fired at once, the burst would be more like 3000 requests at once, which seemed less fine. To handle this, the API call was put in a queue, and fired only when each tab was made active.
“Wyrm is a Special Child”
Near the end of Hunt, one of the team leads told me a secret: Wyrm was intended to be the AI round with the least tech work required. Boötes and Eye needed weird answer checkers, and Conjuri was clearly going to be a lot of work, but Wyrm was not supposed to have any crazy requirements.
This…did not end up being true. Eye ended up being the most straightforward round, since its round implementation was essentially the same as Museum, and diacritic / language canonicalization hell was less hellish than expected. In comparison, Wyrm had an endless maze of edge cases. Puzzles needed to be metas or not depending on round placement, which meant adding a Wyrm-specific API call. Art wanted Wyrm’s avatar to change with round progress, which meant a Wyrm-specific avatar path. The list of puzzles for Wyrm needed to convey its subround nature and looping nature, which meant a Wyrm-specific list of puzzles page.
Then there were the shared puzzles between Museum and Wyrmhole. After teams had their Reactivation interaction, the repeated puzzles from Museum would appear on the Factory Floor. Solving enough of them would unlock an interaction with Wyrm, and doing that Wyrm interaction would move the puzzles from Factory Floor into the Wyrmhole.
This meant the same puzzle would be displayed in up to three different contexts.
- As a puzzle in the Museum.
- As a puzzle on the conveyor belt in the shutdown Factory.
- As a puzzle in the Wyrmhole.
Each context needed to serve the puzzle from a different URL, have a different puzzle icon, and be styled differently. Additionally, we decided that the errata and hint state should be identical across a puzzle and its copy, but their guess states should differ.
We ended up representing each puzzle in the database twice, once as its Museum version and once as its Wyrmhole version. The Wyrmhole version would have a special “canonical puzzle” pointer to the Museum version. To handle the conveyor belt, the Factory puzzle API call was hardcoded to shove Wyrm puzzle data into its puzzle list if teams were in that ephemeral moment between shutdown and talking to Wyrm post-shutdown.
This was still not all of the Wyrm edge cases. It was easiest to unlock the Wyrmhole immediately after shutdown, but we needed to make sure free unlocks couldn’t be used until after the Wyrm interaction. The list of puzzles also needed to redact the Wyrmhole title, which propagated to redacting it in the list of rounds in the navbar. This also all needed to be tied to story triggers, not puzzle triggers, since the state change needed to occur during the Wyrm interaction, where no puzzle was getting solved.
In short, there was an inordinate amount of work done for a section of Hunt most teams sped through in 3 minutes. Of the Wyrm emotes, “:sadwyrm:” was definitely used the most, whenever “yet another Wyrm edgecase” appeared.

You might ask, was this all really necessary? And the answer is pretty much, yes, it was. Remember what I said earlier: the way you make a Hunt story tick is by considering every aspect of Hunt and making it self-consistent with where solvers are in the story. I don’t regret the work needed to make all of this happen, but it was a lot of work.
Interactions
After integrating spoilr code into tph-site, a lot of the flows around interactions had leftover bugs that needed to be fixed for our Reactivation use case. The Reactivation interaction needed to get connected to the Reactivation solve, and resolving the interaction needed to auto-advance story state. Discord alerts for all these events were also set up at this time.

For other parts of the Hunt logic, it was easier if the cutscenes with MATE contributed to deep, so we added a way to configure that too. This made it easier to force some cutscenes to be required for hunt completion. “Create bottlenecks, and direct team attention to those bottlenecks.”
December 2022
The End is Never The End is Never The End is Never
Hunt was becoming more real - people outside teammate are talking about it, wow! Boy they sure seem excited. Meanwhile I was working longer and longer hours on Hunt. It was decidedly crunch time and I was starting to take days off my job to work on Hunt instead. (My job caps vacation days and I was near that cap, so I was going to take vacation days regardless.)
I was feeling like I was always spending my time rushing for something - for work, for Hunt, for this blog, and I had not had time to stop for way too long. I needed a break.
There was a robot learning conference in New Zealand this year, which I was attending for work. I let people on teammate know that I’d be away from Hunt for a week attending the conference, then away for another week taking a real vacation from everything.
But before that:
Bedtime Stories, Castle Grounds, Easy as Pie, Fire Starter, Follow Me, Robber Baron
Puzzle Link: here
Walking Tour
Puzzle Link: here
We’d actually started ideating this puzzle at a Bay Area meetup in October. It was a pretty interesting meetup, since the first thing we did was testsolve Hall of Innovation. We were given most of the feeders for the Factory Floor meta, and told to testsolve it. After getting nowhere, the authors said “by the way, your team has unlocked a new round”, and we looked at the Innovation puzzles. We solved all of Hall of Innovation, then the observers said “Congrats! The Factory Floor meta you started with isn’t ready yet, come back in a few weeks”. Really one of the most trippy testsolving experiences I’ve ever had. They were testing whether a team could solve Blueprint without the Innovation answers. We didn’t, which was good, but it’s still wild that we were told to testsolve a meta, were given an entirely separate round of puzzles, and then were told the testsolve was over before we could use any of our feeders.
But! We are not here to talk about innovation in the Museum of Interesting Things. We are here to talk about innovation in the Tower of Eye. A number of Eye puzzles were written at in-person meetups like this one, since they needed more manpower to brainstorm. One of the major design requirements was that every Eye puzzle should be very strongly tied to its language. It was not okay to use Dutch in a token way. Dutch language or Dutch culture needed to be tightly interwoven with the puzzle. The same was true for every other puzzle in the round.
We considered many things: Dutch auctions, Double Dutch, something with tulips, etc. A teammate mentioned KLM Royal Dutch Airlines gives out Delft Blue house souvenirs that correspond to real locations in Amsterdam, showing the Delft Blue houses they owned. (We were at their place. They didn’t, like, carry Delft Blue houses with them everywhere.) There was a canonical list of KLM houses, with lots of data: number, year of release, address in Amsterdam, and more.
For any puzzle constructor, having a canonical dataset is immediate puzzle bait. That was how we arrived at a Google Maps runaround in Amsterdam, where the first a-ha was that you were in Amsterdam, and the second a-ha was figuring out KLM houses existed. During ideation, we found the airline published its own KLM Houses collecting app, which I still have installed on my phone despite owning zero KLM houses.
The idea seemed straightforward, but we sat on constructing it for two months. It got written at another Bay Area meetup in December. Much of the work was on defining what features to consider for each house, arriving at “blue shapes” to avoid having to define what counted as a window. Data for each house was put into a spreadsheet, then a bit of code was used to randomly shuffle different yes/no conditions until we found a set of five conditions that gave out the correct binary. The directions between houses were then written in parallel by each author, followed by a combination step to reduce overlaps in locations and location descriptions.
Since the conditions were generated by code, it took us a while to notice the 3rd bit of every letter in the answer was 1, an incredible coincidence. The question for that bit was swapped to a more thematic one. The puzzle testsolved cleanly without changes.
With this done, I was officially flying away to New Zealand. On the flight over, I spent most of my time writing up the Appendix of the 5D Barred Diagramless solution.
Funnily enough, there was a puzzlehunt at the conference! The puzzlehunt was a student outreach event, but was open to all attendees. It also…had real prizes? The first place team got $400 NZD (about $244 USD), second place got $250 NZD, and third place got $100 NZD. I knew there was going to be a puzzlehunt of some kind, because a professor who collaborates with my team at work was doing Mystery Hunt. They’d connected me with the student organizers running the hunt, and their students asked for puzzle writing advice. I replied with both the standard spiel (“testsolve everything”) and a non-standard spiel (“decide how tightly you want to tie your puzzles to the conference, and if you want your puzzles to be solvable if teams skip a poster session”). I had not seen any of the hunt prior to showing up, so I was free to compete. It had all the classic first-time constructor mistakes, but I had fun and ended up placing 3rd. I caught up with the organizers later, asking why there were prizes, and they told me that they had a student outreach budget and were well under it - so all the spare budget was turned into prize money. The $100 NZD I got was mostly spent on food. The last few pesky dollars were sent to a pony convention crowdfunding campaign to help them fill a COVID-shaped hole in their finances.
The vacation really helped. I needed a few days to get into the headspace of “you have no obligations today”, but once I did, it was nice to have no stress about deadlines for a bit. I also learned that if a coastal trail sign says “do not pass at high tide”, you should check when high tide is instead of assuming things will be okay. I waded through a half-mile of ankle and knee deep water before deciding you know maybe I should turn around.

The route I am supposed to take.
Of course, I wasn’t able to fully disengage from Hunt. One night, I ended up idly working out the design for one last puzzle.
Win a Game of Bingo
Puzzle Link: here
I run Mystery Hunt Bingo. It’s a tiny joke I threw together in an afternoon. Other people on teammate had asked me if I was writing a bingo puzzle this year, and I kept telling them I would if I had a good idea. I had not had any good ideas.
Well, it was December, and we were in our final puzzle writing push. The official puzzle draft deadline was December 1st, then pushed to December 11th, with an exception for Conjuri feeders. We were past December 11th and the Conjuri slots were dropping fast. If I wanted to make a bingo puzzle, it was now or never. It felt like an enormous missed opportunity if I didn’t do something, so I figured I’d give it another shot.
There was a previous Bingo puzzle in Mystery Hunt 2021, tied to scoring bingo boards. I didn’t want to do the same thing, but the Author’s Notes for the puzzle mention a different aspect of bingo: rigging the board by refreshing until you get a board that you like. Independently of this, I had considered making my site pseudorandomly generate boards based on a given seed, to make it easier to share bingo boards with other people. A puzzle about reverse engineering a randomization process had been in my mind for a while. One of my hobbies is watching “video game science” videos, for lack of a better word, and there’s been some really cool work on manipulating RNG that leverages pretty non-trivial number theory.
This inspired the core idea of creating a seeded bingo generator whose generator could be reverse engineered, then using the same seed on my website to do the last step of the puzzle. I wrote up the sketch while on vacation, saying I could take any answer, but wouldn’t be free to work on it until later. It got approved, and I was given “a meme answer”. (The puzzle answer has appeared many times in the past few years, and was pushed into our Hunt just to continue the pattern.)
My past experience with blackbox puzzles is that you don’t need to be very tight on designing the solve path. As long as the solution is unique, solvers can usually find a way. That’s not to say you don’t think about the solve path, but it is pretty hard for the puzzle to be fundamentally unsolvable once you have a proof that the solution exists and is unique. I was pretty confident that I could bash out the tech implementation in a day or two, since it was basically Collage but much easier.
The issue was that I had no idea how to design a unique solution, and I wanted to get it done ASAP so that I could spend more time on tech. The puzzle needed help. Justin (author of Functional Analysis) agreed to help out. I explained the rough idea, as well as the cluephrase that I’d pretested on a few people. So we knew the target seed length was 9 letters long.
This puzzle was in Conjuri’s Quest, which was targeted to be an easier round. There were a few reasons for this. It was the last round, and we wanted it to act more like a victory lap than a gauntlet. Since the puzzles would be opened last, hard puzzles were much more likely to get completely skipped. The focus of the round was meant to be the game, and it’d be better if more teams got to see the whole thing. Most importantly, feeder release of Conjuri was late due to delays in game development, so puzzle development time was shorter and needed to bias towards ideas that could be written quickly. This doesn’t inherently mean “easy”, but it’s usually faster to design a puzzle with one a-ha instead of two.
Justin suggested that in any game of Bingo, there were going to be three parties: you, your opponents, and the person calling out numbers. Nine splits into three nicely, so each letter could act as a function on one of the three parties. That decreased the “depth” of the puzzle, since you’d only need to reason up to 3 functions deep once you understood what was going on. He also suggested the core idea used in the puzzle: numbers in our grid should satisfy some property X (like “even”), numbers in our opponent’s grid should satisfy some disjoint property Y (like “odd”), and the numbers called should be very biased towards Y. The functions should then generally keep property Y true, except for a small number that push numbers towards X, and we’d use that to engineer a unique solution.
Based on that I decided it’d be easiest if our numbers started low and the opponent’s numbers + numbers called started high, with most functions adding and only a few functions subtracting. The functions needed to be noncommutative to give a unique order in the solution, which led me towards permutations. I figured they were a class of functions easier to derive from the data.
As I messed around with permutations, I found I didn’t have too much trouble designing the functions to give a unique solution for our grid + numbers called, but I had a lot of trouble designing the functions to make the opponent’s grid unique. To reduce work at solve time, I tried to have all functions apply identically to each grid, but it was very hard to prove the opponent’s grid would always win before our grid in every combination except one. So, I relented, and changed how the opponent grid worked, allowing letters to act differently between the opponent’s grid and the other ones. This increased the number of functions from 26 to 52, which was scary (combinatorial explosion grows fast). To combat this, the opponent functions were made much simpler to make them easier to derive.
During design, we were planning to require all seeds to be 9 letters. Editors pointed out it could be really hard to break in without a lot of data, since it’d be hard to examine functions in isolation. We adjusted to 1-9 unique letters to make it easier to get started. The nature of most blackbox puzzles is that they start very hard and end quite easy, and our thinking was that if you could enter 1 letter seeds, you’d be able to run any experiment you wanted without having to solve past unknown intermediate transformations. That ended up working exactly the way we wanted in testing.
When you win the game, the puzzle directs you to reverse the winning seed, which points you to Mystery Hunt Bingo, which solves the puzzle. This reversing step exists only to fight wheel-of-fortune attempts. All the testsolvers tried to nutrimatic from 3/9 letters, and the one Hunt write-up that mentioned Bingo did the same thing. I mean this in the best way possible: y’all are too predictable.
If you check the Mystery Hunt Bingo source code, the incoming seed is passed through a hash function to generate the seed for a PRNG, which is used to sample from the list of phrases. This makes it practically impossible to reverse engineer a desired board. However, as the site maintainer, I have control over the order of the phrase list! The PRNG outputs a list of indices, so after locking in the seed, I changed the order of the phrase list such that the generated indices lined up with the right phrases. It’s been a long long time since I’ve done any cryptography, but I’m pretty sure this protocol isn’t breakable even if you read the code before Hunt.
The side effect is that right now, I can’t adjust the phrase list without breaking my Mystery Hunt puzzle. Sometime I’ll get around to hardcoding the edge case or making a standalone copy to be hosted in the Mystery Hunt archive. One of the two.
In the actual Hunt, teams got more stuck on the last step than I expected. I have the stats on time between winning seed and solve - they are all longer than the 2-4 minutes I wanted it to be. We just never observed teams getting stuck on this step in testsolving, probably because a lot of teammate knows about Mystery Hunt Bingo. I do wish the game win message was more direct about what steps to do next.
I landed back in the US a bit after Christmas. With no plans for holiday travel, I was free to help on physical production of a puzzle that was a long time coming.
Weaver
Puzzle Link: here
They say all good stories end where they began. Weaver was one of the first feeder puzzles I helped brainstorm, and now it was one of the last I’d help make.
“Make” is a very literal word here. I did very little of the puzzle construction. That was done by Brian, and my role was more about internal testing.
Through experimentation with the hydrochromic ink, Brian confirmed Dan Egnor’s Amazon review: the ink felt chalky, and you needed to spread a lot to make the coat of paint cover up text. However, you did not need as much to hide white text, since the hydrochromic ink dried white and disguised it naturally.
The final version was wooden reeds of a tan color, covered with a coat of hydrochromic ink, then letters in regular white paint on top, and letters in regular black paint on top of that. The result very clearly felt painted, but since the entire strip was painted it wouldn’t be too suspicious. The background layer of white would disappear when wet, leaving the regular white letters visible. We assumed teams would not wet the reeds until instructed to, because if the paint washed away, they would be in trouble. (A few teams did start the puzzle by putting the reeds in water to make them bendier. When they sent hints asking if they made a mistake, figuring out what to tell them was pretty tricky.)
The testsolve at the October retreat went well. This left figuring out how to mass produce 80 copies for the live Hunt. Logistics people were looped in very early, and they were not able to find a company who understood and could handle all our constraints. That wasn’t too surprising, but meant we’d need to do it ourselves.
Over multiple Bay Area meetups, different production prototypes were created and sanity checked. The core idea in all prototypes was to build a stencil to send spray paint through. There would be four different stencils, for front-white, front-black, back-white, and back-black respectively. To maintain a consistent alignment, the reeds would be held inside a wooden frame. This frame was iterated several times, with the last one being two flat pieces of wood, each laser-etched with grooves where the reeds should go. The frames would be held together with binder clips for easier assembly and disassembly. A teammate with access to a makerspace in Berkeley ordered a bunch of wood to laser cut the stencils, frames, and triangles for The Legend.
The wood arrived! It was then stolen from their mailroom. So they had to ship another order, which pushed production back a few weeks. I’d ask “who steals a bunch of wood”, but, well, we were evidence that wood was in high demand. Maybe it’s easier to resell wood on the black market. (This is why people read my blog, for the riveting package stealing commentary.)
Once the first stencils were made, we did a test run. This trial showed that spray paint would dry and gum up the stencil holes really quickly. We’d either need to wash the stencil regularly to keep the holes clear, or do something else. If we had to wash the stencil repeatedly, it could not be made out of wood. Acrylic stencils were considered, but another teammate offered their airbrush instead. This did not have the same problem that spray paint did.
With most people free after Christmas, those of us still in the Bay Area met up over two days to do the final mass production push.

The Weaver assembly line (or puzzle factory) was set up in a garage to allow paint fumes to escape, and had many steps.
1. The reeds were delivered in large rolls. One person would cut the reeds to a reference length using a tree cutter.

The reference length was the size of the frame, plus a bit extra to give leniency.
2. The cut reeds would be painted with a coat of hydrochromic ink by hand. We did this by hand because it did not need to be precise, but we did need to save ink. The hydrochromic ink was manufactured in Europe and out of stock. We would not be able to ship another container before Mystery Hunt. The ink we had was the only ink we’d get, and it needed to stretch until 80 copies were made.


3. The loose painted reeds were placed inside an “oven”. This was a portable heater directed towards a cardboard tunnel, to dry the paint faster.

4. Once dry, the reeds were sent to a framer. Reeds that were too bent were thrown out. The remaining reeds were placed into a frame, then sent back to the painting station for touch-ups. Hydrochromic ink applies clear, so it was hard to tell if we had applied enough paint before it dried.

A completed frame going through touch-ups.
Every frame went through two painting passes. The funny part of hydrochromic ink is that when painted on top of itself, it makes the undercoat turn clear too, so even on the 2nd pass we had to remember where we had painted before.
5. After touch-ups, the frames were placed back in the oven for another round of drying.
6. The airbrushing station would take dried frames, and airbrush the remaining letters.

One person manned the airbrush, and a second person kept track of which stencil to use, did a final factcheck the letters were not too smudged, and bagged the reeds into individual puzzles.
The airbrush was the bottleneck, and it took 8 people manning the pipeline to saturate the airbrush. 4 painters, 1 framer, 1 airbrusher, 1 airbrush support / quality controller, and 1 cutter / painter. We ended up working 12-hour shifts both days to finish the puzzle, creating 83 sets. This gives a very rough estimate of 2.5 man-hours per puzzle.
We decided to livestream Weaver creation into our writing Discord, saying people could come “watch paint dry”. I don’t think they actually saw much paint dry, since our camera angle didn’t leave the oven in-frame.

Not many teams made it all the way through the puzzle without relying on the virtual version, which was unfortunate. It worked in the by-hand version, but the production differences in our mass production pipeline seemed to add up. My guess is that our coats of paint were lighter, and some paint was lost by friction in the flight to Boston. The natural loss of paint during weaving was then enough for a bunch of teams to not have enough paint left by the last step. Hopefully the intermediate a-ha was exciting enough to make up for the deficits of material science. If a team placed the weave underwater, and put enough effort into the last step, we decided we would just give them the answer, but this policy wasn’t advertised too well and probably should have been announced more loudly.
Email is Awful
We continued trying to anticipate the tools that we would want to have on Hunt weekend. One of these tools was email. The tph-site codebase had an email flow, spoilr had another email flow, and they had been sort of but not really merged. I did some plumbing work to connect them together, and fixed some longstanding bugs in our interactions flow along the way. The main piece added was predefined email templates for puzzles where teams submitted something to HQ, as well as templates for questions like “why is the loading animation not finishing?”
The implementation for this was awful. I hope to never write code that writes Javascript via Django’s template language ever again.
Wyrm (Continues) To Be a Special Child
Now that more art assets were in, we could finish setting up the puzzle icons. In the Wyrmhole, puzzle icons were non-convex and could be disconnected (this is easiest to see on the layer of fish). To support this, our plan was to make each puzzle icon the same size as the round art. Each icon would have an SVG mask that would cut out the icon from the full size rectangle. Overlapping all the disjoint masks would create the desired interface.
One of the rules we’d placed on round art was that you should be able to tell if puzzles are solved without interacting with the page. This rule was put in place to improve legibility of the hunt state. In the Museum round, this was done by showing the answer below a puzzle’s title on solve. In the Puzzle Factory rounds, the outer glow of the puzzle icon would change color. A subtle change, but better than doing nothing.
Neither of these fit for Wyrm. Any change would need to carry over when zooming between layers, and it felt like showing any puzzle info would distract from the work put into making the round art transition nicely.

Early iteration of Wyrm art
We decided to break our rule, just this once, and make the puzzle title + answer only show on hover. There would be a list of puzzles at the bottom of the page as a fallback for showing the solve state.
The puzzle icons had all worked back in October, but when trying it again in December with real art assets, the round was quite laggy. The problem was that in October, we had tested with 100 x 100 icons of different shapes, but now we were using full 1024 x 768 images, one per puzzle. Pop-in was a lot more obvious.
To solve this, we changed our code to send a single image for the entire background. Then, instead of brightening icons on hover, there would be six 100% transparent white rectangles, cut to the shape of each puzzle icon. Hovering over each div would toggle the transparency to 50%. A white rectangle could be done entirely in CSS, reducing the network + render cost from six 1024 x 768 images down to one.
This is leaving out many tedious details about dynamic z-index ordering, manual surgery of SVGs, code that treated “fish.png” differently from “fish.PNG”, and a long series of visual bugs. Suffice it to say that I learned much more about CSS than I ever wanted to, but somewhere along the way Wyrm had turned into my baby, and I was going to be damned if we didn’t pull it off.
Full Hunt Speedrun
I think every Mystery Hunt does a speedrun during its development cycle. The idea of a full hunt speedrun is not to testsolve the puzzles. It’s to test the overall logic of the Hunt structure and site. Teams get all the answers, go through the site, and report any bugs they find in the site behavior. Our site had a ton of intermediate states, especially in how much of the Factory was accessible and what the Factory monitors displayed, so this was extra important for us to check.
Much like the in-person retreat, the full site speedrun had its own set of secret objectives.
- Breakout: Our fully unspoiled test at retreat was “used up”, but a bunch of the team still didn’t know how the puzzle actually worked. Now that we’d implemented all the post-retreat nerfs, we could do partially-spoiled tests during the speedrun.
- Hall of Innovation: Testsolves of this round had always been done from a copy of the site where only the Factory Floor and Hall of Innovation rounds existed. With more puzzles and art assets complete, it would be harder to realize that the gizmos on the Factory Floor were what mattered to Innovation. Parts of the meta also relied on art, and it would be good to get a testsolve with the final art assets.
- Wyrmhole: Due to limited testsolve bandwidth, the full hunt testsolve was cancelled. Even if testsolvers only did puzzles with 0 testsolves, it was looking dicey if every puzzle would get two clean testsolves before Hunt. This is not a situation any team wants to be in, but there were real TODOs more important than testsolving, like “fix game-breaking crashes in Conjuri’s Quest”. Cancelling the full hunt testsolve was a major problem for Wyrm, since we’d planned to test the backsolve step in that testsolve. There had been some miscommunication between Wyrm authors and editors-in-chief, where the editors thought the last layer of puzzles would show Collage as the meta immediately on unlock, and that the last step was trivial enough to not require a test. After clarifying this was not the case, we added a backsolve test into the speedrun.
The more specific consequence of this was that a bunch of Wyrm art and tech deadlines were moved up 2 weeks. I’m very grateful to the artists of the Wyrm layers for getting art done so quickly after the new deadlines were conveyed to them.
The speedrun itself was split into three groups, due to how many people showed up. Of the three groups, one solved breakout cleanly, one was mostly clean, and the third needed to be given the megahammer email (but solved it immediately after). My group got to Innovation, I recused myself to go eat dinner, and I came back to people correctly deriving which gizmos went to which puzzle. This was considered “good enough” to fastforward them to the end.
This is an aspect of writing hunts that can be a bit disappointing. Your teammates write these really cool puzzles that you get to testsolve, but you won’t get to testsolve all of them. Everyone testsolving all puzzles is super inefficient. But everyone does need to be spoiled on most puzzles when writing hint responses and answering emails, so you are eventually forced to spoil yourself on things you don’t get to experience normally.
There were a number of speed issues reported in the Factory round page that hadn’t shown up within the tech team. We asked everyone with slowdown to report their OS and browser, which did not expose any clear patterns. This was itself useful information that the root of the issue lay elsewhere. It was finally debugged to inconsistent enabling of hardware acceleration. People with slowdown confirmed it got better when forced on, but unfortunately this was a fix solvers would need to apply themselves. We added an info icon with instructions for how to do this. Hopefully solvers would find it during the Hunt.
Once all three groups made it to Wyrm’s last layer, they were merged into one big group. Between all three teams, there were only 7-8 people who were unspoiled on the Wyrm gimmick. Two people in the spoiled group set private messages about identifying the looping puzzle in the art, which confirmed that flow could work. The unspoiled group eventually broke in by considering the triangle pattern in all previous metas, and looking for something triangular elsewhere. One person remembered testsolving Collage at retreat, and figured out how to backsolve, only noticing the looping art after the solve (“oh god, we’re dumb”).
I was mostly relieved that all the parts of breakout and Wyrmhole had worked the way we wanted, and that we could move them into the “done” column.
January 1-8, 2023
Oh No, Mystery Hunt is Soon
There are decades where nothing happens; and there are weeks where decades happen.
As we get closer to the start of Hunt, I’m going to need to segment things more.
The full hunt speedrun had found many more tech issues than I thought we’d find. “Wyrm should save its zoom level”, “I hit a 404 on this link that showed up”, “Notifications are going off-screen”, and so on. Each issue was prioritized and we went down them in order.
Meanwhile puzzle postprods and factchecks were getting merged into the codebase at an absurd rate. Thank goodness for the auto-postproduction script, because boy were there just a lot of words words words to copy into HTML. I caught up on writing a bunch of solutions that I’d been putting off for a while, but left their postproduction to other people since I was needed elsewhere. I did end up doing code reviews for most of the postproduction pull requests. It was a simple menial task to do, in between all the harder ones.
We set up a second full hunt speedrun, to run the last weekend before Mystery Hunt. Not everyone was free for the first one (given it was in the middle of the holidays), and it wouldn’t hurt to have another round of testing after we’d fixed more bugs.
I did more bug squashing, but then shifted my focus to something completely different.
Load Testing
This would be the third time I’d done load testing for a puzzlehunt. First I did it on my own for Puzzles are Magic. Then I was asked to do it for Teammate Hunt thanks to prior experience. And now I was still the person with the most experience on how to set it up.
Puzzlehunts are not that big. If anything, they’re quite small. My blog is fairly niche and got more page hits in a year than Teammate Hunt did. The difference is that puzzlehunts are very bursty in their load, where during the event you need to be firing on all cylinders. In my experience, I’ve seen two classes of errors.
- Your HTTP handlers are overloaded. In this scenario, requests to the server will be replied to very slowly, but the server and database will mostly not go down. They’ll just be very laggy. This is usually only a problem at the start of Hunt. You can either ignore it, or make the server CPUs more beefy.
- Your websocket handlers are overloaded. The websocket connection layer in tph-site uses Django Channels and is mediated by the database. Having too many websockets open at once causes the number of active database connections to rise. If the database connections go past a max limit, all new database queries will fail. This is a much worse problem, because websockets are designed to be persistent connections, and the most likely outcome is that everyone past the first N people will never be able to load the site. This is a configuration problem, not a server-size problem, and upgrading the server CPUs is not enough to fix it.
I was not at all worried about the first, and quite worried about the second. All my previous load test adventures were done using Locust, since I learned how to load test from reading example code in the Puzzlehunt CMU codebase. This time, I decided to try k6, based on a load testing script from Huntinality. The documentation for testing websockets in k6 was a lot more complete, and writing tests in JS made it easier to mock our React frontend.
Broadly, the way all these load testing libraries work is that you define the access patterns of a hypothetical user. “This user will login, wait a few seconds, open the list of puzzles, open a random puzzle, and submit a guess.” Something like that. The libraries then provide utility functions that let you spin up users according to some schedule, and provide statistics at the end. The main work for load testing is in defining user behavior and mocking the same requests real users would send.
I created a few different user profiles:
- Chatter: opens MATE, sends some chat messages, then leaves.
- Collager: opens Collage, sends 1 guess into Collage per second for a few seconds, then leaves.
- Browser: opens each round page to load art assets, then leaves.
- Jigsawer: opens the collaborative jigsaw from the loading puzzle, drags pieces to a new location every 0.3 seconds, then leaves.
The last was the one we most wanted to test. In the jigsaw, cursor locations are broadcasted to every team member on the page, which requires O(N^2) messages per update, and they’d be sent frequently. The update frequency was rate-limited to 0.3 seconds per update, but this would still be a lot.
One mock user doing the jigsaw.
I got the load test script done just before the second full hunt speedrun. For this speedrun, a small group of people acted as a mock HQ, and some puzzle answers would say “send a hint to get the answer”, “request a physical puzzle pickup to get the answer”, “oops this puzzle is impossible, redeem a free answer”. This was to get all those aspects of site behavior tested as well.
Once again, there was a secret objective: tech would make a deploy to the site during the speedrun, to measure the length of the deploy during active usage, and check how noticeable the interruption was. There was also an extra secret objective: I was going to spam the site with fake users. I’m pretty sure the only person who knew I was planning to do this was Ivan.
There was some slowdown on entering guesses on the site, but nothing too bad. There was much worse lag in the collaborative jigsaw. It was to the point where one person would drag a piece, and it wouldn’t change on anyone else’s screen for several seconds. I confirmed I saw the same lag, then killed the load test. It was quite a sight to see 20 jigsaw pieces all snap into place at once after the other load went away.
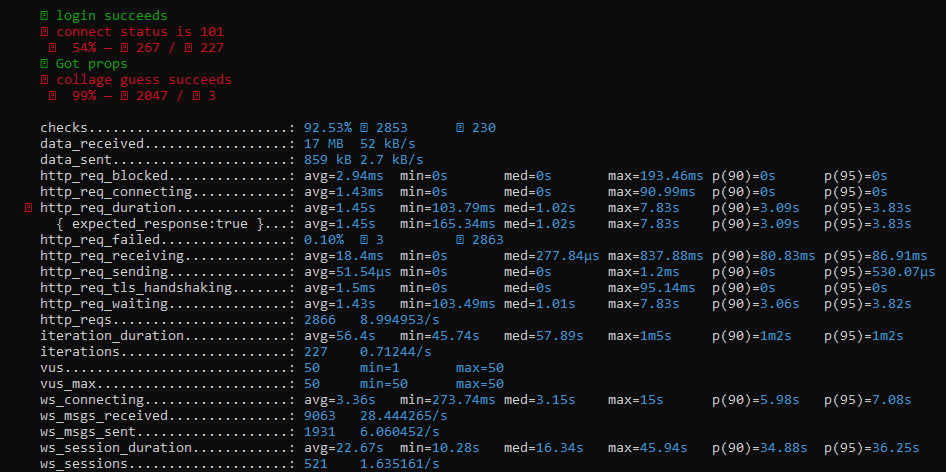
Brian was of the opinion that the stats would look much better if CPU load weren’t at 100%, but he’d also take a look at breakout and Collage to see if there were easy performance wins. He found some places to batch websocket updates and add more caching. This made the next run of 50 users better, but we made a note to try again with the full-size machine.
Monday Before Hunt
Hello, Boston
I had taken (another) week off work, but this time it was more justified. Even in a year where I’m not writing Hunt, I have trouble being productive the week before Hunt starts.
A bunch of teammate flew in for Hunt. I left the Bay Area Monday morning. We’d been warned our Tim Tickets wouldn’t work until closer to the event (and also that the Tim Ticket app was a mess).
I was still in the mode of “optimizing how I use my time”, so I prepared a bunch of work that I could do without Internet to do on the plane. It turned out my plane had in-flight WiFi (praise JetBlue), but I had trouble connecting to it from my laptop for whatever reason. My phone connected fine, so I ended up spending my flight doing code reviews from GitHub’s mobile site, working on the 5D Barred Diagramless appendix after I’d exhausted the queue of pull requests. As I tapped out a comment on my 8th code review of the flight, a part of me acknowledged that trying to squeeze Mystery Hunt writing into this many aspects of my life was really not a healthy thing to do.
For the week before Hunt, teammate would have an informal HQ in an AirBnB we booked near campus. Around half the team would stay there, and the other half had booked hotels or were staying with friends. The on-campus HQ would not be available until the Friday of Hunt, although we did get a classroom booked the Thursday before for the final team meeting before Hunt.
When I landed, I asked for directions to the AirBnB, and was told the best balance of money and time was taking the Logan Express. So, I stood at the Logan Express stop, checking directions on my phone, and wondering why it claimed taking public transit would take 5 hours. A few searches later, I found that the last Logan Express of the night had left 10 minutes ago.
Shit.
Luckily calling a rideshare wasn’t too bad, and I got there in time to see Ivan complain about responsive CSS and “why can’t all computers have the same size screen”. What a classic teammate puzzlehunt tech experience.
The Wyrm round art had a hardcoded width/height that didn’t fit on everyone’s computer during the speedrun, and I had pawned off fixing that to Ivan. This left me free to focus on connecting Conjuri, Terminal, and other interactives into my load testing script. For me, this was the best trade deal in history. I will take infrastructure over responsive frontends any day of the week, but I did feel bad about abandoning frontend hell.
I finished writing up the 5D Barred Diagramless appendix I had worked on during the flight, then went back to my hotel to sleep,
Tuesday Before Hunt
Factchecking
This day was a bit quiet, since not everyone had flown in yet. Most of my time was spent addressing factcheck feedback to puzzles.
A few months back, we had set up PuzzUp to auto-generate a factcheck template spreadsheet for each puzzle. Factcheckers would fill it out and it would auto-generate a comment in Puzzup when done. I’m not sure how helpful the comment was, we hit message length limits often, but the spreadsheet definitely helped!
The complexity in how we displayed puzzles on the site definitely contributed to difficulty of factchecking and postproduction. I think this could be useful for other teams, so I’m actually going to just directly copy paste the questions in our factchecking template. (In retrospect, it looks a lot like a prompt you’d give to a large language model.)
Instructions: Fill out this checklist. Completeness and Correctness are the most important points to check carefully. If it does not apply, note it can be skipped.
Completeness and Correctness
- With the help of the solution, I solved the puzzle 100% (all clues, no nutrimatic, etc)
- By using the solution, I did not need to think very hard to solve the puzzle.
- If there is “uniqueness” invoked in the puzzle, uniqueness is checked. e.g.. uniqueness in a logic puzzle, answers to clues, etc.
- Make sure facts are still true. List info that could change on or before 1/13/2023 under Other Findings.
Puzzle
- Copy to clipboard matches puzzle in both Firefox and Chrome
- Second person (if there’s any person at all), present tense narration
- Flavortext is italicized. Non-puzzle info (e.g. controls, accessibility, and contacting HQ) should come with the “info icon”
- Post-hunt note: this is a specific “circle” icon that can be seen on puzzles like Museum Rules
- Interactive components work for the intended solve path, doesn’t crash on incorrect/malformed inputs, any shared team state is tested
- No unintended source code leakage (inspecting code doesn’t spoil puzzle)
Display
- Puzzle is displayed (post-prodded) correctly and tested on small/large window sizes, interactions tested on both Firefox and Chrome (or note which browser was tested)
- Puzzle is displayed (post-prodded) correctly on a mobile device and fully navigable, if interactive, via touch
- Act 1 only: Puzzle looks correct in the void, i.e. no white on light text
- Post-hunt note: after solving Reactivation, teammate shuts down Mystery Hunt. Museum puzzles could still be accessed from the Puzzle Factory, but were put in dark mode (black background, white text) to signify that they were in a void “outside of puzzlehunt space”, so to speak. Sometimes a puzzle would hardcode text colors that worked in light mode, but not dark mode.
Accessibility
- Do all images with puzzle content have alt text? If there’s text in the image, can it be typeset with CSS instead of an image?
- Is the puzzle color-blind friendly? Does it rely on colors or can they be replaced with symbols or text?
- Do audio clips have transcripts when possible? Do videos have synchronized subtitles?
- For interactive puzzles, does it require very fine motor control? Is there an undo button if misclicks or typos will cause solvers to lose large amounts of work?
- Does the puzzle use inclusive language? If the puzzle talks about people, does it contain a representative sample (gender, race, age, etc.)?
- Print preview looks reasonable (can see all parts of crossword, clues, no unnecessary black backgrounds) on both Firefox and Chrome
Solution
- The answer is in Answerize format (bold + caps + monospace). All cluephrases are caps (not bold or monospace unless necessary).
- If puzzle involves images/visuals, they are included in the solution
- Solution is in first person plural (“we”, “our”, etc). It does not use terms like “the solver”, etc
- There are no typos or grammatical mistakes in the solution.
- Solution is displayed (post-prodded) correctly.
Depending on the puzzle, there could be up to four different “versions” of it to check (the displayed puzzle, its display in dark mode, its display in print preview, and its copy-to-clipboard). I think almost every puzzle I helped on failed its first round of factchecking due to issues in one of those versions or accessibility problems, so a lot of my time was spent fixing CSS issues, updating solutions, and writing better alt text.
In the days before Hunt, I had stopped using my time tracker app, because it felt increasingly useless - all my waking hours were spent on Hunt anyways, I wasn’t going to get insight from recording that fact. When looking for suitable work music, I learned that Demetori, my favorite music group of all time, had just released a new album after a 4 year hiatus. (They do Touhou remixes, mostly progressive metal.) I spent most of the week playing it on repeat. The Youtube comments taught me facts no one should know (“corgi” is edit distance 2 away from “orgy”), but I couldn’t help thinking about the album’s closer - “It’s Better to Burn Out Than To Fade Away”.
Wednesday Before Hunt
Load Testing
The tech work continues!
There were a rather worrying number of features left to implement, including fixing print previews, cleaning up yet more bugs in interactions, and adding a Contact HQ + puzzle feedback flow. Bryan had made a habit of speedrunning the Hunt daily for the past week, surfacing new site bugs whenever he found them.
All bets were off on code cleanliness, so the Contact HQ page was implemented by reusing our hint code. There was an internal puzzle called “Contact HQ”, which did not show up on the list of puzzles or contribute to unlock progress. It started with hints unlocked and had no cap on the number of open hints. Contact HQ requests would then fire alerts in our hints channel, where they could be claimed and resolved. Is this awful? Absolutely. But, it was the fastest thing to set up and we were at the point where everything needed to be speed.
Speaking of speed, I was testing Conjuri’s speed under load. I had zero idea how the game worked, or even how to fight any of the monsters, but I got some pointers from the main Conjuri devs for how to start games and move around. The load test was to login, connect to a Conjuri slot, then send a bunch of move commands (10/second, roughly the speed they fire if someone holds down the arrow key). Along the way I found a security flaw that could have allowed teleporting anywhere in the map, including past locked doors (oops).
My load test script would sometimes enter monster fights, and then immediately get stuck because you can’t enter move commands in the middle of a fight. I decided this was fine. The goal was to test load, and the server responded with a no-op when given a move command that it couldn’t apply. This still forced a reply of some kind, which is all I wanted to test.
Brian had provisioned the full-size hunt server, and I hit it with 250 users. This immediately had errors, but the site seemed fine, and the error message codes I was seeing looked more like networking issues. Having seen a similar error when load testing Puzzles are Magic, I asked if our AirBnB WiFi could handle 250 fake people at once, and then immediately answered my own question with “no of course it can’t”. (When load testing Puzzles are Magic, it took me a while to realize this was a possibility, and I spent two days trying to fix a bug that didn’t exist, which was a painful experience.)
Alex Gotsis had a spare DigitalOcean machine for personal stuff, and we moved load testing there. The new 250 user test went fine. Great! Let’s scale that up to 500 users. The CPU load looked fine, but we started seeing real site errors, ones that were breaking the site for other people on teammate.
Oh dear. I left it up for a bit so we could collect more stats, then turned it down. The errors were identical to the ones I’d seen when load testing Playmate from Teammate Hunt 2020. It was definitely a database connection issue. I went back to our 2020 docs (thanking the gods that we’d decided to write documentation in 2020), and told Brian to try setting up PgBouncer and optionally swapping our Redis layer in Django Channels to RedisPubSubChannelLayer (since someone on Huntinality had mentioned it made their load look better). While Brian set that up, Alex Gotsis came by with some news.
He explained that the site sent us an email whenever we had a server error. This was the mechanism we used to make server errors more noticeable for debugging. Sent emails create and save an Email object in our database, to integrate with our email handlers.
Now, suppose your site has no available database connections. It’ll error out. The server will send an email to tell us about the error. This creates an Email object, which will fail to save because there are no database connections left. So the site has another error, and sends an email to tell us about it. Which, once again, fails to save the new Email object, since there are no database connections. Which triggers a 3rd error, and a 3rd email, and a 4th error, and a 4th email, and so on.
I said “Oh no”, and he said “Don’t worry I’m fixing this”. Once that was fixed, we removed several thousand failed-to-send emails from our Hunt database and everything was fine. Phew.
After all the websocket improvements were in, I reran the load test and the site no longer broke at 500 users. The switch to RedisPubSubChannelLayer looked like it cut our CPU usage by 3x, which was cool. Between both of those, I was willing to declare the site battle-ready.
The one issue flagged was on Conjuri. All the Conjuri instances were running on the same server as the rest of the Hunt. The codebase had evolved that way and we did not have the time to refactor it to a separate machine and adjust our deploys accordingly. I gave my opinion that 500 users continually submitting guesses and moving 10 times per second in Conjuri was likely a big overestimation. I was pretty sure our true load would be a lot lower, and not too many teams should be on Conjuri at once anyways. That sounded fine to Conjuri devs - or at least, the game bugs to fix were more obviously important than hardening against load.
Physical Things
While all this tech discussion was happening, there was a flurry of work on set construction, driving things from A to B, and building all the physical parts of the runaround. I got pulled into a charades testsolve in between some tech discussions.
There were an incredible number of flight delays in the week before Hunt, which was quite scary for us. because every copy of Weaver was with one person. Thankfully their flight was fine. With load testing done, I could go back to some TODOs I had for the Wyrmhole round art, but before that point I stopped by the physical puzzle station and said, “I want a mindless task please give me something to do.”
“Great! Cut all these pieces of paper.”
It was for Tissues and I spent an hour using a paper cutter to slice large sheets into smaller sheets, and folding flat tissue boxes into box-shaped boxes.
Meanwhile, one of our two drivers reported a problem.
I’m about to wreck y’all’s day.
I probably can’t drive tomorrow.
I am currently largely fine, so don’t flip out, but as I was walking back to my car, a car hit me in a crosswalk.
THANKS UNIVERSE, THAT WAS A REALLY FUN CURVEBALL YOU JUST THREW AT US. JUST SWELL. Luckily the person who hit them was very apologetic, immediately taking the teammate in the accident to the ER. They were able to show up for Hunt and help out, aside from needing to use crutches. Post-hunt, they were diagnosed with a Grade 2 MCL sprain, and as of April, it is still recovering but the recovery looks promising.
Wyrm Art, Again

Ivan had figured out how to make the Wyrm round page scale with screen size, but there were a few lingering Wyrm art requests to handle.
First, switching out the zoom buttons. To fit the papercraft aesthetic, the buttons were made by hand - as in, they were literally pictures of construction paper, laid out by hand, then photographed. It was a bit surreal to be working on a tech task, then glance over at a real-life instantiation of an art asset I knew I’d need to add into our hunt site in an hour.
Second, the background. There was yet another Wyrm edgecase needed, this one to make sure the triangular grid in the header lined up with the grid in the rest of the background. For reasons I don’t want to get into, this did not work by default and needed to be hardcoded specifically for Wyrm, keeping up the theme of “Wyrm has an edge case for literally every part of Hunt”.
Last, the hole. The puzzles were supposed to appear out of the jagged hole. This required adding one final SVG to the site, to slice the rectangular image into the shape of the hole, and making sure it aligned properly with the hole. With this, Wyrm was now truly, finally done.
Thursday Before Hunt
Hunt Hunt Hunt Hunt Hunt
Thursday was the first day that we had a room on-campus. We were also starting to spot people who definitely-looked-like-Mystery-Hunters in the hotels we were staying at.
This time, we convened in a classroom on-campus. We first had a too-long conversation about whether we should draw the blinds on the windows to our classroom before we went into an incredibly spoiler-heavy presentation. The decision was “no that’s overkill”. We then had a presentation about the story of Hunt, structure of the rounds, and different responsibilities that would need to be filled to man HQ. The previous day, a spreadsheet had been shared, and people were asked to fill it out, but today that request was now a demand. “Sign up for a slot or we will find a slot for you.” I checked and had been pre-signed up for “tech on-call / contact”. Problem solved.
We then had a training session for how to use the hint and interactions interface, which I mostly tuned out because I’d been fixing bugs there for several weeks. Team T-shirts were distributed, all with a picture of MATE on the back, and we were told to make sure we wore a hoodie or sweatshirt, something that hid the back of the shirt, until MATE was revealed at kickoff.
The remaining time was allocated for people to finish up any last minute tasks for Hunt. I went through the list of tech TODOs, and it was very clearly at a point where we would not be able to finish all of it before Hunt. A lot of features were cut at this stage, including solve sounds.
This made some people on teammate quite sad, but there were just too many other things. “We don’t have bandwidth to do this. If you have bandwidth to help on tech, we’d prefer you’d work on these prioritized issues, but if you implement a deprioritized feature and send a PR someone will probably review it.” That is the only reason why the Hunt has solve sounds, someone decided to do just that.
Mystery Hunt is an enormous thing. It is big enough that even team leads are not aware of all the things going on. Nor should they be. The coordination overhead would be too big if they were. But, the natural consequence of this is that sometimes, people’s beliefs of what is getting done differs from what’s actually getting done. Tech is just one example of this. I got a copy of the MATE tutorial page that would be viewable before puzzle release, and ended up rewriting a bunch of it because it suggested using chat messages that would not pass our hardcoded parser. (The plan to try an ML-based intent classifier instead had long been abandoned.)
This is approximately the level of chaos I expected the day before Mystery Hunt, and although I was concerned, I wasn’t surprised. Logistics got ironed out, more bugs got fixed, and we made progress on the site. We started organizing our tech on-call shifts, and I signed up for the 1 AM - 7 AM shift originally, before reconsidering and asking if I could take the one ending at 1 AM instead.
Run (Slowly) Towards The Exit
As the last action item before Hunt, we did a “slowrun”, where instead of solving puzzles as fast as possible, a group of us would solve puzzles one at a time, pause at every meaningful state change, and verify the site’s behavior matched expectations. The original target was 7 PM, but it got pushed back, and back, and back…
The delay was bad enough that we were going to lose our room reservation on campus. Everyone not involved in verifying the slowrun was told to get some sleep before Hunt, while the rest of us headed towards the AirBnB HQ. It was going to be a long night.
The slowrun officially started around midnight. Over several hours, we proofread all the site pages, checked that puzzles and round pages unlocked properly, that the Puzzle Factory was gated properly, that story updates and interactions appeared at the right time and had the correct art assets and links, and more. There were around 10 “major” stopping points where we would go through the entire site, both Museum and Factory, to check nothing unlocked early and nothing unlocked late. We also checked display issues similar to the factcheck spreadsheet, like site functionality at different screen sizes. As we discovered bugs, we discussed if they were worth fixing now, would be fixed during Hunt, or not fixed at all. Those who want the gory details can go here. With some final touch-ups along the way, the slowrun finished eight hours later at 8 AM.
Kickoff was in a few hours and some people in the slowrun needed to go straight to rehearsal. I was not one of those people, had been up for a solid 24 hours, and decided to find a corner to take an hour long nap before Hunt got started. I really should have just gone to bed, but it’s the first Mystery Hunt kickoff after two years of remote Hunts. Proper sleep can wait.
Friday of Hunt
I arrived at Kresge a bit out of it, but intact enough to say hi to people lining up outside. I didn’t have too much to say. Talking about Hunt is something you do after, not before.
One very minor upside of pulling an all-nighter is that I did not have to remember to bring my “Museum of Interesting Things” staff T-shirt. I had put it in my bag yesterday afternoon, and then never made it to my hotel room, so I could just put it on directly (along with a hoodie to hide MATE on the back).
While ushering people into the auditorium, I got the sense it was about as full as previous years, which I wasn’t quite expecting. I figured there’d be less presence due to COVID concerns, but it didn’t look that way to me.

I saw kickoff for the first time with everyone else; I’d been too caught up in tech to see any of the rehearsals. The stage was decorated with a bunch of random decorations bought from Home Depot while getting construction supplies for set creation. Based on all the people taking pictures after kickoff, it looked like a few hunters were trying to image ID the decorations, just in case they were a puzzle. I’ve heard one group actually succeeded. The larger columns were painted cardboard wrapped around wood and pool noodles to give them rigidity.
Now, we unfortunately did not have our official HQ in Building 10 available at the start of Hunt. It would be available later that afternoon. For now, our HQ was two separate classrooms that we’d reserved for a few hours through MIT Puzzle Club. We could handle it, but it made the start of Hunt more complicated. There are just more communication hurdles when people aren’t in the same room.
Once we got to our rooms, we had a fun time trying to connect to the Wi-Fi. MIT had scheduled a wireless network change to happen the Friday of Hunt. We were aware of this beforehand, but MIT Puzzle Club both did not have the cachet to delay the change, and was also assured the migration would be fine.
Well, it wasn’t totally fine, because two things happened.
- Anyone who’d connected to campus Wi-Fi before the transfer (i.e. literally everyone on teammate) could not connect until they’d told their devices to forget the MIT guest network.
- Discord calls that worked yesterday didn’t work today. We were able to figure out it was a port issue - Discord uses a random UDP port from 50000-65535 for voice calls, and the range was blocked on the guest Wi-Fi.
I had the fun time of needing to enter a code that was sent to my phone or email to get my laptop connected, when my phone had no cell signal and I had no Wi-Fi signal. I was lucky enough to suddenly get a tiny bit of cell signal, just enough to get the code through, and successfully bootstrapped from there to full Internet connection. The Discord problem was something we’d just need to deal with.
As puzzle release approached, people on teammate started poking around our internal HQ pages, and immediately found a bunch of errors and exceptions on a bunch of them. This was disappointing, but not too surprising. Our speedruns and slowrun were all very focused on the solver experience, and we hadn’t exercised our HQ backend to nearly the same level of scrutiny. Tech immediately started preparing “hour one” patches, to merge in after puzzle release was deemed stable.
Puzzles go live! No guesses came in for a bit, which made us paranoid that our site had not released puzzles properly. Then some guesses started coming in, and we breathed a sigh of relief. T minus…we’ll find out, until the coin is found.
I realize I have yet to describe what our Hunt weekend organization looks like. Here is the list of roles:
- Huntcomm: People keeping an overall eye on the pulse of Hunt, comparing solve progress against different forecasts, and in charge of decisions for deciding on interventions to either speed up or slow down Hunt. Mostly made of people on hunt exec that were spoiled and had context on all of Hunt.
- Tech: Self-explanatory. On-call to answer any questions about the site’s functionality and implement any fixes or feature requests needed to run Hunt.
- Physical Puzzles: Handles giving physical puzzles to teams that ask for them.
- Phone: Answer call-ins are gone, but we have a phone number! In charge of answering the phone. We did not expect many phone calls, so this was merged with other roles.
- Dispatcher: The person to talk to if you are free and don’t know what you can do to help run Hunt. Tracks the point-of-contacts for tech, huntcomm, and other roles with on-call rotations.
- Runners: In charge of moving things between rooms. Generally not a dedicated role and only important at certain points of Hunt.
- Logistics: Very similar to dispatcher, but not exactly the same. Roughly, the dispatcher knows where everyone is, while logistics knows what those people are doing. But if you want, feel free to treat dispatcher and logistics as one big group.
- Food: Handled group orders for meals. Catering had already been ordered for the entire weekend based on a team interest form on Thursday, but there were smaller bespoke group orders too. (Boba runs, people who’d missed the food form, etc.)
- Acting: Played characters for Reactivation interactions. Only came up later in the weekend, although a few people acted as Museum employees when doing team check-ins.
- Hints, Contact HQ, Email, etc: Everyone else. In charge of replying to hints, emails, and other communication channels between solvers and HQ.
These were not rigid roles, and very often work was quite fluid and picked up by whoever is free.
The phone was pretty interesting. Two days before Hunt, someone on logistics told me they’d gone to MIT Puzzle Club’s storage, and found 10 phones in a closet. It took them a bit to figure out which phone was the correct one for the number we’d advertised on the website. I’m guessing these phones date to when you needed 10 phones to handle answer call-ins, and had been sitting around ever since. Why would you throw away perfectly good phones?
Remember me mentioning we were seated in two different rooms? This meant tech was half-split between rooms, huntcomm was half-split, and so on. Which makes things extra spicy when we got reports that the Puzzle Factory was leaking.
Many Hunt websites have an API endpoint that retrieves the list of all puzzles in JSON. We deliberately set up a non-user facing endpoint for this, to help any teams with coordination tools like Jolly Roger, Galackboard, or Checkmate. Internally, all teams start with Factory puzzles unlocked, but they are not linked and not accessible until the team solves the Loading Puzzle. In all of our speedruns, we had checked user-facing site pages to verify we did not show those puzzles. We had forgotten the puzzle API existed, and a few teams sent emails asking if they were supposed to see puzzles.mit.edu/2023/puzzlefactory.place links.
Nope! Nope nope nope. Nooooooope. We merged in a hotfix right away and thanked teams for reporting the problem. Luckily, knowing the URL does not let you access Factory puzzles early, and at most they spoil the puzzle titles and upcoming theme.
Things are fine for around the next hour, until teammates start reporting they’re having trouble loading the site. We start with triaging whether this is an admin-only issue or a site-wide issue. It’s starting to look like a site wide issue. Then the phone started ringing. The room goes quiet as the phone person picks up the phone.
“Hello?”
“Yes, we know the site is down. We’re working on it.”
(“Do we have an ETA for a fix?” “No, but tell them they don’t need to spam-refresh the site.”)
“For now, please avoid refreshing the site too much, that’ll make it worse.”
*click*
…Well, good to know the work spent finding the right phone wasn’t in vain! It was also funny to realize that there is still a good reason to have a phone number in the year 2023: it’s a good backup when your site goes down.
The logistics person in the room complains that conversation in the room cannot entirely stop if someone else calls the phone. We need to be able to discuss spoiler-heavy topics while phone calls are handled. The phone was moved close to the door, so that the person answering it can step outside when fielding calls.
It does not take long for tech to figure out why the site went down despite our load testing. The default behavior in tph-site is for all tabs from the same browser to connect to the same websocket. This lets live updates on one tab auto-apply to all other tabs. When we set up the chat interface, we’d made each tab use a different websocket, so that each tab could persist different chat histories.
The load testing script modeled a user as opening one tab, spamming tons of requests, then closing the tab. This was not the right model for Hunt. The correct model is one user opening 100 tabs, then spamming many fewer requests in just one of the tabs. Our server’s CPU load was way under the load we saw in load testing, while our number of websocket connections was way over. We are, once again, out of database connections.
We discuss a bit, and given that our CPU load was only around 30%, we believe the site will be fine if we multiply all our websocket handling numbers by a ton. If that causes us to run out of CPUs, we’ll handle that later. Once deployed, the site comes back up and stays up. CPU usage does rise, but is well within bounds. Phew, crisis resolved. (I just want to briefly point out that if we had not load tested as much, we would have just DDoSed ourselves from the email feedback loop. Things could have gone much worse.)
The main problem was that just like our internal testsolve at retreat, some teams would now surely be assuming the loading animation was caused by server load, and was not a puzzle. But that wasn’t really fixable, we’d have to see how it played out. No one had solved the loading puzzle yet, but most teams had not solved enough puzzles to get a long enough load time. I knew that projections of Hunt existed, but had not seen any of them. Huntcomm had, and was getting concerned that the first round was moving too slowly.
Still, teams were solving at a steady pace, and we got our first official breakout into the Puzzle Factory! Hooray! The Puzzle Factory reveal started cascading through the other lead teams, and we were glad the puzzle was working despite the site issues.
Huntcomm recommended opening hints early, rather than at our planned time of 9 PM. The way hints worked in our Hunt was that they would open when it was both past the global hint release time, and a puzzle had been solved by at least N teams. The default setting for N was 25, but this could be changed on the fly without redeploying the site. It was still early enough in Hunt that teams had not separated much in number of solves, and releasing with the default N = 25 would have practically opened hints on every puzzle.
As the tech point of contact for the half of HQ I was in, someone on huntcomm asked me to weigh in on the plan of changing N to whatever value would make hints unlock for the first 3 puzzles of the Hunt, which was N = 70. I told them that yes, this would work, but if they did this, huntcomm would be signing up to continually track solve counts and adjust N throughout the Hunt. Was that fine?
“Yes.”
Okay then! But then the logistics person in our room immediately pointed out that we were about to switch rooms to our official HQ location. Releasing hints at the same time as everyone moving rooms was a bad, bad idea. Huntcomm wanted to release hints now, and they got priority. We pushed moving rooms back by an hour and opened hints immediately. It was a gamble that no one would actually kick us out right when our room reservation ended, and that gamble was correct.
As hints came in, it exposed a few more bugs in our HQ pages for hint management, which I started looking into. We got our first emails from teams asking why puzzles were taking forever to load, and responded with a standard hint template. The initial rush of hints subsided, and this was as good a sign as any that we could start cleaning up to move to our more permanent HQ.
A runner asked if I could carry some soda. “It’s in Matt.”, they said, as they ran away.
Sorry, what?
We had named our temporary storage rooms Matt and Emma, and I did not know where either of them were. Luckily someone else knew the way, and after doing a few trips we’d moved everything to the Building 10 HQ. Back to hint writing.
Well, for most people, it was back to hint writing. A few teams were reporting that the collaborative jigsaw puzzle was stuck, with one piece missing. We weren’t able to reproduce the issue, and we didn’t have an easy way to reset the position of a single piece, the puzzle state was one giant JSON blob. The best solution we came up with was to manually skip the team past the jigsaw, by copying the solved jigsaw state from the admin team into their team, and manually adjusting the story state to mock the trigger they would have hit.
There was a new “stuck on jigsaw” email every 2-3 hours, so I wrote up a quick playbook for what to do, before everyone who knew the jigsaw backend code went to sleep. We also started getting emails reporting some of the known issues that we’d found but deprioritized the day before Hunt - no volume slider on solve notifications, accessibility issues in navigating the Puzzle Factory rounds, no solve log, and so on. I alternated between replying to emails acknowledging problems, and asking other web devs if they thought it was fixable during Hunt.
The volume slider was deemed doable, and got fixed. After a deep dive through the code, we figured out the complicated CSS bug that caused Factory puzzles to not be scrollable with arrow keys, and fixed that too. (Much later, a week after Mystery Hunt, we learned the accessibility fix in Factory CSS broke printing on all Factory puzzles. In general, please contact HQ if you have an issue with the site! We can’t do everything, but this specific issue only took 15 minutes to fix once we knew about it. We just never knew about it.)
A few teams start reporting that they do not see the puzzle icon for Cute Cats, and are asking if that’s relevant. We tell them it isn’t, and start investigating.
Do you want to know what happened? Part of our asset packing step generates random filenames
based on image content, to do cache busting. The filename generated was
https://cdn.mitmh2023.com/media/ad/*.png and this caused ad blockers to block the puzzle icon.
Easily the most “I hate programming” moment of the Hunt.
Huntcomm was still concerned about the pace of Hunt, so they decided to give extra event rewards for the first event. They asked if there was a way to see how many event rewards a team had used, because they wanted to see if teams were using event rewards or hoarding them. I pointed to the internal admin pages that would show this, but realized event usage wasn’t very legible and made a note to address this sometime.
On sending the extra event reward message, we found that some of our emails were not going through. Ever since Teammate Hunt 2020’s troubles with paid email services, we’ve run email through a self-hosted email server. Broadly, this works until it doesn’t. Somehow we’d managed to hurt our email reputation, and emails weren’t getting delivered to our Gmail. I still don’t know what happened. My guess is that when we self-DDoSed ourselves in load testing, it caused our Gmail to treat our email server as a spammer? In any case it was very annoying, we tried to fix it, it started working 6 hours later, and I’m pretty sure whatever we did had zero impact on making our email work again.
After I got dinner, Alex Gotsis came by, asked me how much sleep I’d gotten (“…1 hour?”), and relieved me of duty so that I could sleep. I didn’t leave, and an hour later he more directly told me I should go to sleep so that we’d have full on-call coverage later.
I got back to my hotel room, but set up Discord alerts on event reward usage and puzzle feedback before getting into bed.
Saturday of Hunt
Sleeping so early meant I woke up much earlier in the morning than usual, and I arrived at a mostly empty HQ. I caught up on overnight progress, then got back to answering hints.
In Palindrome’s AMA about writing Mystery Hunt last year, they mentioned the initially unlocked puzzles made up around half of all hint requests. That was looking true for us as well. When running a Hunt, it is very common to get new teams that essentially want to be handholded through the entire solve. Of course, we will answer the hints they send in, that’s how those teams want to have fun, but it did get a bit tiring when teams sent a new hint every time they wanted to confirm a single cryptic in Inscription or a single state in Museum Rules. Luckily, answering hints has a natural “get better with experience” phenomenon, where after your 10th hint on a puzzle, you can quickly figure out where a team is stuck and what to tell them.
Things were progressing, albeit more slowly than anyone had expected. Someone opened the soda I had helped carry yesterday, and the physical puzzle distributor stopped them, saying “Don’t drink this soda, it’s a puzzle.” This is really the kind of sentence you can only hear and believe at Mystery Hunt. I was as surprised as anyone, nobody told me it was for Fountain. I had placed it next to all the other food and drinks.
Running Hunt was simultaneously getting more boring and more exciting. Fewer things about the site were on fire, which was good. More teams were solving the fun submission puzzles. Our first tirades from A Twisted Theory had come in Friday evening, but now a bunch of other teams were solving the tirades puzzle and sending in even wilder speeches about Tim Tickets and Taylor Swift.
We did another round of team check-ins. Our first round was on Friday and went…okay. We had sent out three groups of people, one with Mystery Hunt organizing veterans and two with newer people. The new groups came back early, and the veteran group came back much later. What had transpired was that the veteran group was much better at asking questions that got teams to give real feedback and start a conversation about how their team was doing, rather than generically making smalltalk. The dispatcher (I think it was Edgar?) had that group write up a guide for how to run team check-ins, and I believe the 2nd round of check-ins went a lot better. I had planned to go on one of those runs, but did not because I was the main tech person awake that morning and needed to be on-call.
Speaking of tech, we had designed an entire interactions flow for team check-ins. There was a magic button in our site, which would unlock a “check-in” interaction for all teams. People could then mark check-ins as completed whenever they visited a team, reusing the work we’d put into our hint answering flow. I asked how that was going…and most of the check-in infra wasn’t used.
The main things missing from the dispatcher point of view:
- Interactions were ordered by team name, but the important feature was ordering by location. Check-in squads needed to be sent to regions of campus and the site didn’t support sorting by that.
- Some teams had special instructions they’d sent over email. Some were minor, like “knock first”, but others were more important, like “our team is very concerned about COVID, so we’d like anyone from HQ to mask up and present a negative rapid test before visiting our room”. This info wasn’t always in our site’s database.
- Bulk opening a check-in for everyone didn’t do a good job of ignoring teams that had self-reported they had stopped solving Hunt.
The people managing check-ins had decided to do everything over Google Sheets instead.
Teams were still behind huntcomm’s projections, so they handed out more event rewards. With reward alerting up, it was now very clear that lots of teams were stockpiling their rewards. Teams were making progress, but we needed teams to use free answers despite making progress. I understood why they weren’t using free answers, but understanding didn’t make it less stressful.
Huntcomm tried a lot of alternate wordings on the event page to nudge teams to use event rewards more aggressively, and none did very much. Eventually the event page was updated to say that free answers were usable in 8 rounds of Hunt, to let teams know where they were and imply there were more rounds after that. At the time of the swap, I believe leading teams were at most 6 rounds into the Hunt, and there was a clear uptick in rewards spent after the wording update.
The event reward flood had also exposed new edge cases in our event handling code. In testing, I had never tried redeeming multiple event rewards at once. Puzzles don’t unlock immediately in tph-site, they unlock lazily on the first page load after you’ve advanced the unlock track. The reward redemption page did not update puzzle unlocks in between event usages, so if a team spammed all their unlocks without refreshing, they could be debited more rewards than they could actually use. I sent in a bug fix and we gave back event rewards to affected teams.
Remember how I said running Hunt was getting more boring? Yeah, with all the pacing emergencies, that was no longer true. Huntcomm had already shipped a bunch of changes to unlock tracks, to open rounds sooner, open metas sooner, and increase puzzle width in existing rounds. They were now deciding that Hunt speedup needed to be even more drastic.
Anyone with an AI round puzzle was asked to brainstorm ways to pre-nerf their puzzle before teams unlocked it, so that we didn’t have to issue errata later. If we didn’t come up with a nerf, huntcomm was going to nerf the puzzle for them. All of these nerfs would not be testsolved (everyone who could is busy answering hints), so this restricted nerfs almost exclusively to flavortext nerfs or removal of intermediate steps rather than changes to existing clues and designs.
We Made a Quiz Bowl Packet was marked unnerfable due to requiring clue rewrites. 5D Barred Diagramless was also basically unnerfable. But, some of the other puzzles I worked on had easier nerfs. Period of Wyrm was given a more direct hint towards the Mandelbrot set with the names of the people, and Walking Tour had a reordering step removed.
By now the hint threshold had been lowered to N = 15, and huntcomm was hesitant to lower it any further. Partly it seemed unfair to bring N closer to teams that could be in contention to find the coin, and partly it was unclear if we had the manpower to widen the hint stream.
Hints tend to be more fun for solvers, but they don’t make Hunt end as fast as free answers do. One of the hypotheticals I’ve thought about after Hunt is what would have happened if we took N all the way down to 0 to open hints to all teams on all puzzles. I believe the consequence would have been an immediate collapse of the hint system. Every top team would send in their work-so-far on puzzles that we’d never answered hints for before. We’d spend 10-20 minutes deriving what they knew and what they didn’t, and once our reply went through, they’d immediately send a hint for a different puzzle. We needed ways to push Hunt forward that didn’t require us to be in-the-loop, and hints were not one of them.
Saturday evening, huntcomm announced that we were going to change the Reactivation requirement to 3/4 input metas instead of 4/4. (The incoming meta requirements were the Office meta, Basement meta, Factory Floor meta, and Museum metameta.) We would also change the scavenger hunt to reward free answers that were usable in AI rounds. This would cause a lot of weirdness in story, but was looking necessary to push teams through.
Changing logic close to Reactivation was especially scary. This was easily the most complex part of our unlock structure. It was the source of many bugs we fixed during the year, and now we needed to change it. Once we sat down to actually check the details though, making it unlock on 3/4 was actually not too bad, since the majority of the complexity was on what happened after Reactivation, not before, and everything post-solve was staying the same.
The AI round free answers, on the other hand, were more complicated. Way back when, we’d decided they wouldn’t be supported at all. As the person who set up event rewards, it was on me to implement this feature request in the next few hours.
I found the event reward code, and jury-rigged AI round free answers by doing a ton of copy-pasting of the old logic. I did not want to touch any of the existing logic if I could. I decided to call them “strong rewards”, because they were more powerful, and the name stuck because making a better one was the least of our worries. There were no plans to release strong rewards outside of the scavenger hunt yet, but I decided to implement the functionality for doing so now, in case it was needed later.
Our goal for all these changes was to get them into the site before any team unlocked the scavenger hunt. The Reactivation changes and strong rewards made it in with around 30 minutes to spare.
Speaking of Reactivation, people were rightfully very excited to go do the first Reactivation interaction. When completed, teams would chat with MATE, teammate would shut down the Puzzle Factory, and a few minutes later teammate would barge into that team’s on-campus room to tell them Mystery Hunt was cancelled.
Shutting down the Factory was automated, but showing up on-campus was not. Logistically, teams did not know we would be coming to their rooms, so we needed to know when a team was close to solving Reactivation. The transit time from our HQ to another team’s HQ could be up to 15-20 minutes at the extremes. We wanted teams to have nothing but a shutdown Puzzle Factory, to sit with the consequences of their actions, but we didn’t want teams to actually be stuck waiting for teammate.
Our solution was to send a Discord alert when 3/4 Reactivation minipuzzles were solved (time to prepare) and 4/4 Reactivation minipuzzles were solved (time to barge into HQ). Kind of like a “tornado watch” and “tornado warning” system, except with puzzles.

At 3/4, teammate members would leave HQ and nonchalantly hangout near the team HQ, trying to not be too obvious. At 4/4, they would converge. Sometimes the gap between 3/4 and 4/4 would be very short, like Cardinality going from 3/4 to shutdown in 5 minutes.

Sometimes, it was not, like when TTBNL solved 3/4, half of hunt HQ immediately left, and they didn’t come back for an hour because TTBNL was stuck on the last mini and guessing CONJUWU.

Meanwhile, hints were still coming in, with only half of staff available to reply. This made the dispatcher very upset, and he tried to get people who weren’t directly acting to stay behind in HQ and join a later run. But people were very excited to yell at teams, and I never expected the cat herding to succeed. I went back to answering hint requests, keeping an eye out for interesting ones.

We had now crossed another MIT campus closure checkpoint. I packed my things and helped bring physical puzzles to a hotel pickup point, checked they didn’t need tech help, and went to my room to set up alerts on strong reward redemption. I decided to sleep early (“early” = “4 AM”) so that I could stay awake through Sunday. Surely Mystery Hunt will end by then.
Sunday of Hunt
I only got around two hours of sleep. Waking up at 6 AM, I checked the team Discord to see if there were any issues. There were, with strong rewards. As implemented, they were only usable in the AI rounds. In the two hours I’d been sleeping, huntcomm had decided they did want to send strong rewards to everyone. To make those rewards useful to everyone, strong rewards needed to be redeemable outside AI rounds too.
“How urgently do you need this, like should I get out of bed right now?”
“Yes please.”
So I got up and spent the next hour making that happen.
Internally, event rewards work the same way as hints in gph-site. In gph-site, instead of directly storing the number of hints a team has left, the database stores the total number of hints a team has ever received. On every page load, the backend computes how many hints the team has used so far, then displays the difference to the frontend.
An advantage of this design is that you never need to worry about database transactions or keeping counts in sync across models. A hint is used if and only if the team has gotten back a useful hint response. Event rewards did not originally work this way, but on Saturday we’d had a bug where a team lost an event reward because an exception triggered during event answer handling, causing them to solve the event but not get the reward they should have gotten. To fix this, I swapped the logic to match the gph-site design.
A disadvantage of this design is that the more ways you can use hints, the more complicated it is to compute hints live. For example, gph-site supports intro-round only hints, so a pure “# hints requested” is no longer good enough - you need to check if a team’s last hint is only usable on intro rounds. I now needed to port similar logic into reward redemption.
The new logic would iterate through any event reward usage the team had, compare it to their total regular + strong rewards, and greedily use the “weakest” reward required. This did require describing the logic really awkwardly on the event redemption page, because there were edge cases where a team could gain a strong reward by spending a regular reward, or use a strong reward and only deduct a regular reward, which could be pretty confusing.
Once it was tested and reviewed, we shipped it to production and gave out the first set of strong rewards. I said I’d stay up until I saw the first alert of a team using a strong reward. That happened about 10 minutes later, and I told people I was going back to bed.
I woke up a few hours later, decided that was as much as I’d reasonably get, and walked to hunt HQ. You might think the mood was more somber, now that we knew Hunt was wildly behind schedule, but it really wasn’t. Maybe it was more panicky in huntcomm, but I thought the rest of HQ was holding up well and still running smoothly in an emergency.
A group of people were going to Tosci’s to do a double-check for Eat Desserts on Main before leading teams unlocked Conjuri. They said they’d do a group order for ice cream for HQ, which I immediately jumped on. I don’t remember what flavor I got, but it was good. Also, now that we knew around how many teams would unlock Fountain, we knew we had way too much soda. A portion of puzzle soda was declared “no longer a puzzle, please drink”, but a teammate complained that they’d only drink the soda if it were a puzzle. It was relabeled as “puzzle soda that’s okay to drink”. Drinking the soda, they described it as “perplexing”.
By now we were no longer getting many site bug reports. There was one issue in Wyrmhole links caused by colliding React keys. One part of our frontend had implicitly assumed that a puzzle title would never repeat in the same round. The fix was easy, the bug was minor, but when I realized that Wyrm was still causing havoc in our codebase in the middle of Hunt, I broke down laughing. It echoed the story so well!
We were also starting to get screenshots of teams’ first reaction to the complete nonsense of Boötes round answers, which was pretty great.
It was unfortunate this was mostly via free answers, rather than solving the puzzles, but the reactions were everything I wanted.
The drip feed of strong answers continued, along with nerfs delivered via errata. I’ve seen a bit of speculation about why we used errata to send nerfs. The deployment process for Hunt was based on Docker and includes a step where Next.js needs to build the application. Blah blah blah, tech tech tech, the short version is rebuilding and deploying our site after a code change took around 15 minutes, whereas errata is viewable immediately. It just looks a bit weird. I remember not liking the nerf given for The Scheme, it felt like it was just removing the puzzle entirely compared to other flavortext nerfs. It probably was helpful to push off the rabbit hole of reusing the layout from The Legend though.
Sunday continued on and on, with no team finishing Hunt. We did see teams spending one free answer on the scavenger hunt to get two free answers in return, which was simultaneously disappointing and delightful. It was like we’d given teams a free money hack in the universe. I mean, it was not actually free money, doing the scavenger hunt was probably easier than solving any AI round puzzle, but some teams don’t want to touch grass. What can you do?
A funny property of the scavenger hunt is that teams almost always overprepare for the scavenger hunt. Teams don’t know how harsh the judging will be, and want to leave wiggle room. The thresholds for the scavenger hunt had been pre-nerfed during Hunt (all point thresholds moved down by 10), but according to the judges, every team would have passed the original threshold, and the nerf had probably made the scavenger hunt better.
Teams were now doing runs in Conjuri’s Quest, and we were getting reports of lag. That was pretty concerning. In load testing, we had assumed not too many teams would be doing Conjuri at once, and our sims overestimated websocket load. We were wrong about both, due to moving Conjuri unlock earlier during nerfs, and not realizing the implications of one websocket per tab until too late.
There was a very brief tech meeting where we tried to figure out if there was anything we could to relieve load. I argued that at this point, we probably did not have time to improve our websocket code. The only reasonable fixes were to either heavily decrease websocket usage, or spin up another server.
I was not expecting either to be doable, so an hour later I was surprised to see huntcomm in the middle of migrating hunt progress to a second server. A lot of tph-site assumes it runs on a single server, so we would not be trying to sync databases between the two or auto-shard requests. Server load would instead be split manually. Some teams would be given the URL to the new server, and others would not. Only the original server would count for Hunt progress, but teams could use the second server to play Conjuri’s Quest. I sent out an FYI that some Discord alerts would get duplicated, and people should not worry about it.
Around Sunday evening, we got a complete flood of hint requests, most likely from teams that believed HQ was closing soon. We immediately drafted an email telling people Hunt was still going to slow down the flood, while trying to handle the backlog.
Strong rewards continued to be given out every hour, until multiple teams were at a point where they had every feeder answer in the AI rounds. Once that happened, the feed of strong rewards was stopped. It was now a waiting game to see which teams would crack the metas first.
No team had solved all the metas by Monday 1 AM, the next MIT campus closure window, but huntcomm was now quite confident that they could push a team past the finish line. If necessary, they would give increasingly strong meta hints until someone finished. The logistics lead decided to close hunt HQ for part of the Monday overnight shift, since we’d noticed very few pickups during the Sunday overnight shift, and we really needed huntcomm to catch up on sleep. Many had stayed up later than their planned shifts.
After I got back to my hotel, I saw that some teams had started the clickaround (MATE’s Team), and decided to stay up until they finished. Then I decided that no I don’t need to do this, they won’t finish until we’re allowed back on campus anyways, I’m going to get sleep. With a team on the clickaround, team leadership starts preparing a slide deck for wrap-up. They ask if I can get them a GIF of the full loop of the Wyrmhole round art. I tell them to give me a bit, and try messing around with generating it programmatically, but none of these options are as good as a screen recording of me clicking the zoom button a few times. This is the final GIF that made it to wrap-up.

If you want the version that zooms way too fast and may give you motion sickness, you can look here.
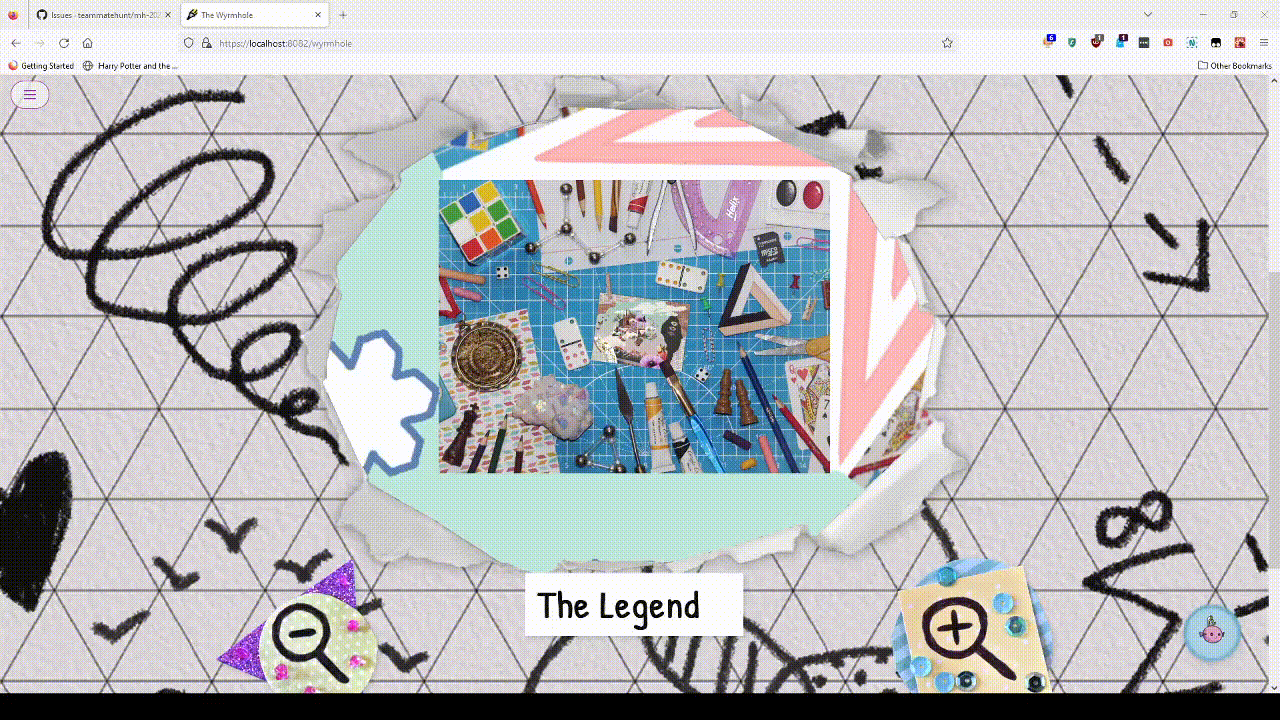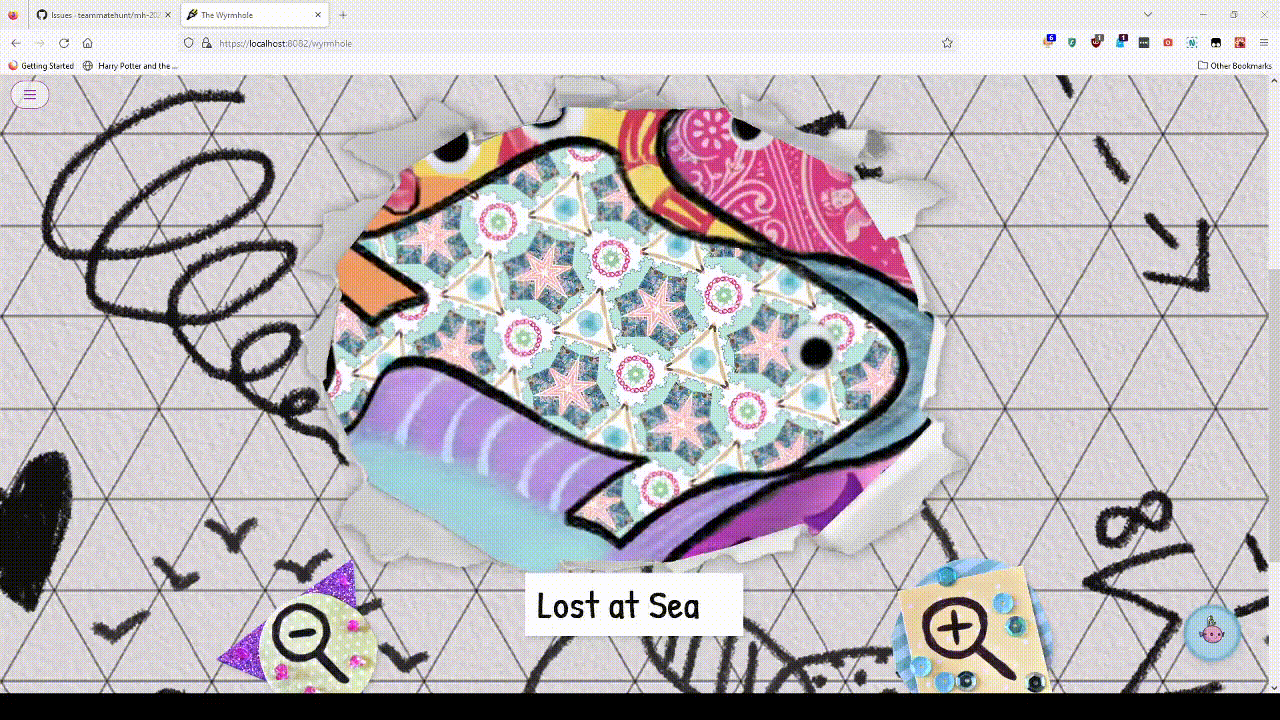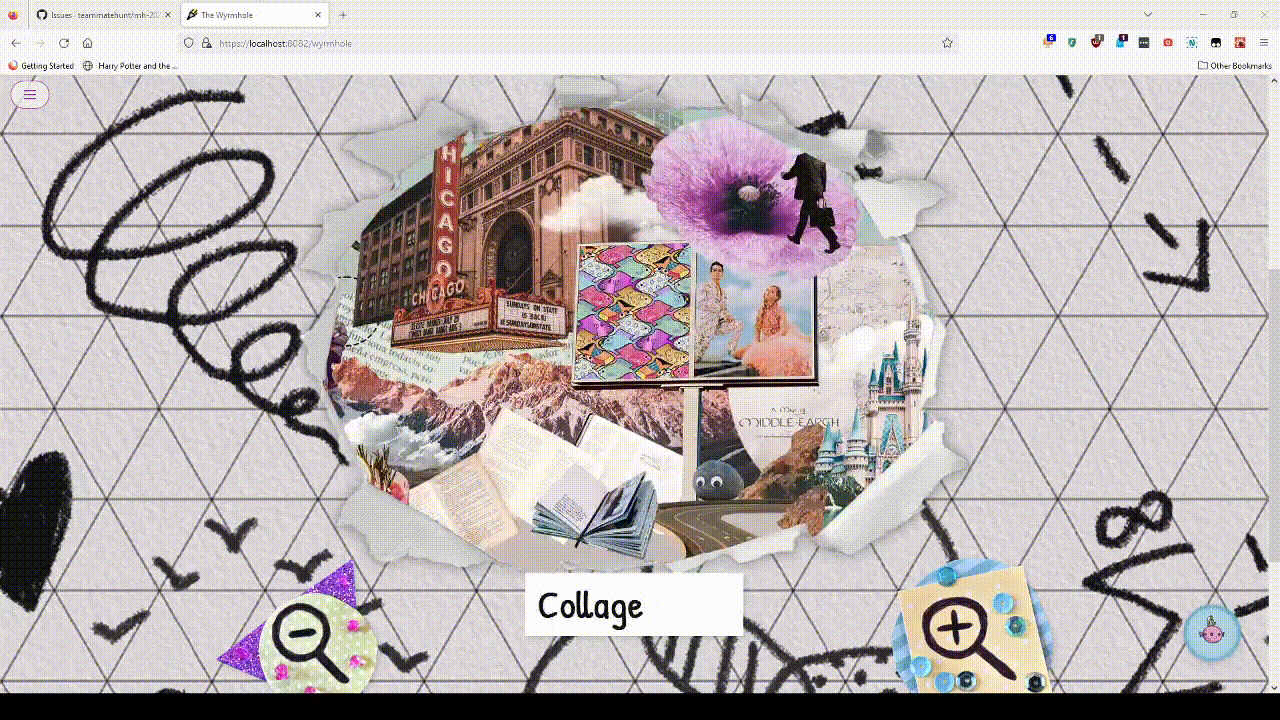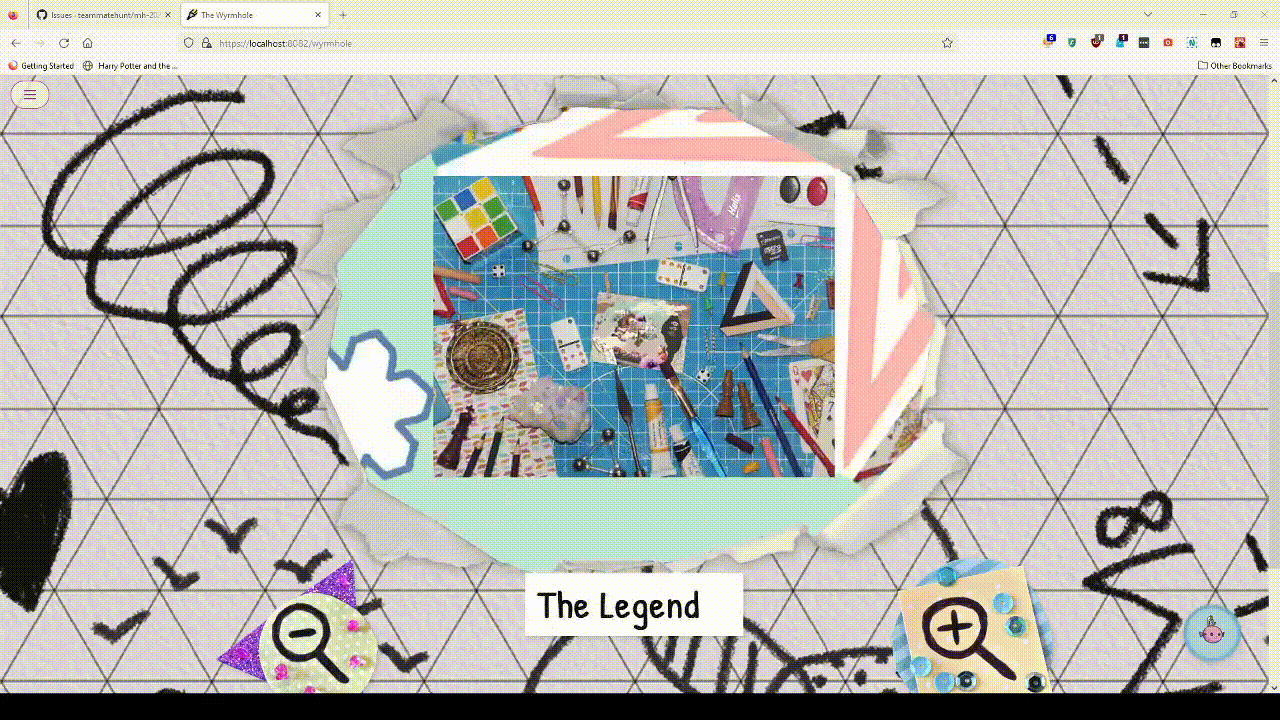{kind=link}
Monday of Hunt
Multiple teams finished the clickaround overnight. We send an email saying “the coin will have been found”, and schedule runarounds for Monday morning, which is…only a few hours from now.
I once again do not get much sleep and end up in HQ early to answer more hint requests. Perhaps in a more normal Hunt, this would be when we’d open the floodgates and time unlock everything and make hints available for all puzzles. But this year, it is 6 AM on Monday, and everyone is busy setting up final runarounds, which we plan to run right up until a 10 AM cutoff. With wrap-up two hours later, there is no energy to create more work or handle that work.
In betaveros’s post Hunt post, he mentions that if you have to choose between a Hunt that goes short and a Hunt that goes long, it’s clear people prefer a Hunt that runs short. Let me just say, MY GOD is this true on the organizing side too. One of the more silent consequences of a long Hunt is that you have less time to make your wrap-up, check your solution release, etc. We are now very certain that we cannot get solution release done by wrap-up, because there are too many things to check in the time we have left between end of Hunt and wrap-up. This is quite sad.
There are 4 timeslots for runarounds and more than 4 teams that finished. We end up grouping some of the later teams together as we try to make sure everyone who finished early enough gets to see everything. Then it’s time to close up for real. The Puzzle Factory is disassembled. I take one of the gears as a hard-to-explain keepsake for later.

Wrap-up happens, and if teammate sounded a bit out of it, well, that is not unique to long Mystery Hunts. I think the default state of Mystery Hunt wrap-up is that the presenters have stayed up too late and are trying to compress a very long story into a very short presentation. This is not something I’m that good at, if this post is any indication. I will say that wrap-up does not go as badly as I thought it would. Some people are mad online, but people in real life are civil, friendly, or reassuring.
After wrap-up, I catch up with puzzlehunting friends that I haven’t gotten to see all week because I’ve been busy running Mystery Hunt. I’m happy to hear puzzles I worked on listed in people’s favorites. People slowly file out of the room and soon it is just teammate. We do one more team photo for the memories, then disperse until dinner.
For lunch, I end up at Roxy’s (my 2nd time in 2 days). Someone from Galactic is there with us, and tells me they decided to 100% Collage for fun. They want me to guess what their last word was. I guess right on my first try. Then I doze off while eating, and decide I should take a nap before dinner.
The team dinner at Spring Shabu-Shabu is mostly uneventful. The hunt retrospective is officially postponed to a later date so people can catch up on sleep, but I head back to the AirBnB instead of my hotel because I am pretty awake after my nap, and don’t really have anything else to do.
When I arrive, a few other people from tech are working on getting solutions and basic puzzle stats out. Most of it is done by now, the main TODOs are on updating our stats pages to account for free answers and fixing access issues for accessing stats pages no matter what the team’s story state is. We successfully get solutions out that night. Figuring out static conversion of the site, or public access teams, is set for another day.
The official postmortem is not happening until later, but the part of team leadership staying at the AirBnB is doing an unofficial one anyways. They are going through various puzzles with the air of “why did we write so many teammate-friendly puzzles and metas when not all teams are teammate, why was this puzzle made so long, how could we miss this and this and this f*** f*** FFFF***”. Some of this self-criticism is fair and some is not.
(The next day, we’d get some advice from a previous Mystery Hunt organizer, where they 100% called that we had already done a panicked reflection on every mistake we’d made, then went through the reasons it’s bad to do that so close to Hunt.)
The world turns, and life moves on.
I do a Boxaroo! escape room on Tuesday, play some board games, then head to the airport to fly back home.
February 2023
Did You Think It Was Over?
The model you might have is that after MLK weekend, you can stop thinking about Mystery Hunt. This is sort of true? It depends. In general, if you work on Mystery Hunt tech, Hunt really does not stop after MLK weekend.
In our case, we have a big problem of figuring out how to make a public team on a site that makes assumptions about team state on, like, literally everything. There was then more work on getting canned hints onto our site, figuring out how and where to link the solution to a loading puzzle that doesn’t exist for the public team, and generating the customary Hunt stats page.
I start looking at the Mystery Hunt feedback form, but seeing feedback like “you did not mean for anyone to have fun with these puzzles” when you have just worked a 100 hour week trying to make sure people had fun with the puzzles is pretty disheartening. I force myself to stop, telling myself that if I read any more feedback, I’m just going to get depressed, and the stats page will get delayed until March, and nobody wants that. I’ll look later.
First things first: figuring out what we can even measure in our Hunt. In a typical Hunt, solve times and solve counts are pretty free, but in our case we have nonsense like Hall of Innovation. I don’t find a clear place where this information is saved in the database, it looks like our stats page only reports the last time a team has solved the puzzle due to us literally deleting old puzzle submissions whenever the gizmos change. I eventually figure out that I can get the information if I write a Discord script to crawl our entire #guess-alerts channel, and parse out the team and timestamp via some regular expressions on top.

I also need to figure out how to merge solve data from the server spun up for Conjuri back into the main server. We told teams only the main server would matter, but had little faith that teams would bother to resubmit the Conjuri feeders. Brian sends me some pointers to the database dump, and I figure out that all our existing documentation only applies to setting up a Postgres database from scratch. We don’t have any docs on merging databases together, since this just isn’t something we’ve done before. I end up loading both dumps locally and set up some hacky scripts to merge data appropriately.
That just leaves everything else. Most of the novel stats like number of chats are not too bad to derive in Django shell after I understand the data format. Data on when teams solved the collaborative jigsaw is partly incomplete for teams that had to get fastforwarded past the puzzle, since they never got credited with an official solve. I spend too long trying to reconstruct the full data from email logs before deciding it’s not worth it. Would anyone even notice the inconsistencies? Probably not. (They’re still there, if you look closely enough.)
The spoilr HQ page has some built-in solve charts based on chart.js, which solves many problems while introducing other ones. I get confused that the given chart.js code doesn’t match the chart.js documentation. Then, I figure out the chart.js version is out of date. There’s a feature I want that’s only in the most recent chart.js release, so I migrate past a breaking API change to get access to it. Then I learn that there is an undiagnosed performance bug in the newest version of chart.js that is causing the charts to render 2x slower, and sigh as I undo all my migration work. I care about speed more than making the charts display nicely on mobile.
As I generate the team size graph, I find it very cute that you can almost see the vertical lines where teams round their team size to the closest 5 or 10. It reminds me of an old Jon Bois video showing that American football plays are biased towards starting from multiples of 10, due to refs having some leeway for where to place the ball. You can see the lines of scrimmage, until Death & Mayhem breaks the illusion with their reported team size of 133.
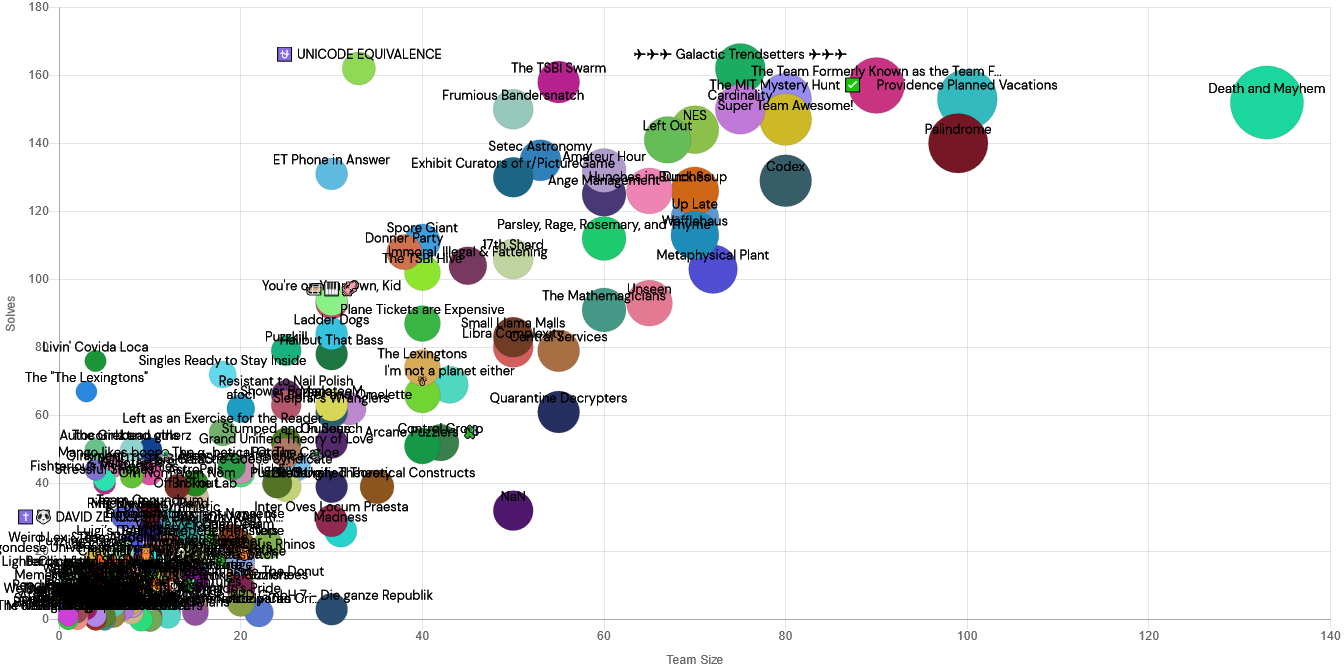
Over the rest of February, we figure out what we want our code handoff to TTBNL to look like, whether we should clean up our code or release as-is, and the list of tech TODOs to make all the interactive parts of Hunt stay working once the site is archived. Then I stop paying as much attention.
March 2023
The site is not converted by March. It turns out it is a lot harder to work on Mystery Hunt 2023 when the world has moved on from talking about Mystery Hunt 2023. There is no one left to prove things to.
I suppose that’s the deal. Write a tech-heavy hunt that strongly assumes a server exists, and it looks cool live, but it’s annoying to wrap up later. Given how long it took to package up Teammate Hunt 2020 and Teammate Hunt 2021, I was entirely unsurprised that Mystery Hunt was not done with static conversion.
Brian leads the push to get the relevant parts of the Python backend to work with Pyodide, since there is absolutely zero chance we are going to rewrite any of the Python code. I mostly contribute to documentation and code review sanity checks. The small reviews I do send are for fixing some hardcoded URLs, bugs in the static answer checker, and making sure solve sounds still play in the static version of the site. A cleaned up version of our modified tph-site and spoilr is finally released, here and here.
That brings us up to now.
Thoughts on Hunt
Obviously, some things went wrong. I’m not going to deny that.
The main thing this Mystery Hunt has reinforced for me is that expectations are the root of all suffering. “We normally see the entire Hunt, and didn’t this year.” “We wanted to solve the first meta, and didn’t.” “We thought Hunt would be easier due to your smaller team size recommendation, and it wasn’t.”
Do you notice the expectation in each one? I think these are reasonable expectations to have, but they are expectations nonetheless. There is unfortunately very little feedback from new teams, but the feedback I have seen is more positive than you would think. They went in knowing Mystery Hunt was enormous, and were given an enormous Mystery Hunt.
I think it’d be a shame if the only story of this Hunt in 10 years is “it was really hard”. As someone who spent a lot of time on non-puzzle aspects of Hunt, a lot of the stuff I’m most proud of is in supporting the structure and visual presentation of Hunt, rather than specific puzzles I designed. I never want to deal with responsive SVGs ever again, but my God we made them work for the jigsaw and for the Wyrmhole.
That being said, I did write a lot of puzzles too. I wrote more puzzles this year than I have in the past 10. (That isn’t saying much, given I had a 7 year hiatus in between, but still, it was a lot.) If anything, this has made criticism easier to go through. I’ve seen people simultaneously put my puzzles as their favorite and least favorite puzzles of Hunt, and this makes it easy to tell it’s not an attack on my character or self-worth as a person.
I think our story team wrote a good story, and art made some pretty art, and tech made a site that did what we wanted, albeit with an outage or two. And from what I heard, logistics was insane this year. After two years of remote Hunts we’d lost some institutional memory for how to run an in-person Mystery Hunt, and parts of doing so had to essentially be rederived. Yet it all came together.

The AI Rounds
In terms of planning, everything about the Hunt was building up to the AI rounds. I suspected that they would spark extreme reactions (both good and bad), and I think that was mostly true. I wouldn’t have it any other way. Think of them as experiments into what puzzlehunts are allowed to be.
![]()
Wyrm was pretty constrained, and earlier I have said it might have been too constrained for its own good, but I’d like to think the final reveal and art made up for this. From the start, the Wyrm pitch was “imagine all the cool art that we can put in this round”, and there was indeed a lot of cool art.
Boötes was stupidly cursed, but I think the gimmick pulled its weight in creating novel extractions for its feeder puzzles. The nature of the round gimmick pushed in that direction, and it certainly delivered on that front. The rise of emojis has taken ASCII emoticons out of popular Internet culture and it was fun to do a bit of a throwback.
Eye’s art was quite popular. Its gimmick was more of a mixed bag. My sense is that if you had someone who knew the language or culture, the puzzles hit incredibly well. If you did not, then the puzzles did not hit as well. The round concept pushed towards research heavy puzzles, and I suppose this is why so many free answers were launched at this round. Still, I think it was good to write puzzles that were deliberately not friendly towards English speakers. Puzzlehunting is a very Anglocentric hobby, but puzzlehunters are increasingly multicultural. Just compare the ethnicities from competitive programming or logic puzzles to the ethnicities in puzzlehunts, there’s a clear difference. Peking University is running a puzzlehunt this year that will be harder if you’re not a native Chinese speaker, and I think this is super cool. Spore Giants, a Singapore based team, unlocked How Come This Crossword Got No Grid One? and solved it in 1.5 hours. They didn’t make the stats cutoff, but this is 3x faster than the fastest non-free answer solve, and they were so excited that they asked if we could make an exception to get them onto the stats page. We didn’t, but I’m glad they got to see a puzzle made for them.
And then there’s Conjuri. Even while implementing Conjuri, I know some authors were suspecting that only 10 teams or so were going to get to see it during Hunt. A lot more than 10 teams ended up playing Conjuri by the end, and aside from the lag, I hope it was rewarding to play the game and get more experience at beating the monsters each run.
Ways to Improve the 2023 Hunt
I am about to go into a big list of interventions that I think could have addressed the Hunt difficulty and improved the Hunt. Before doing so, I want it clear that I’m still proud of the vast majority of the work I did for Hunt. It was a lot, and took over much of my life, and I’m not sure I ever need or want to go through the experience again, but I did it and a lot of it was cool.
At the same time, I think it is important and interesting to consider where things started going wrong, because I think some of the errors were pretty subtle. It is not an easy explanation, like “teammate was inexperienced”. We’re a younger team, but collectively I believe members of teammate have run 5-7 puzzlehunts before Mystery Hunt (some good, some bad). It’s not quite “teammate did not account for being biased towards their own puzzles”. This bias was known and a big topic in puzzle variety discussions, and is the reason the hunt is only half-littered with math and video game puzzles instead of completely-littered.
There were other things going on.
Calibration
If you forced me to pick one thing that went wrong, it would easily be calibration of difficulty. Puzzles were harder than their ratings across the board.
But, it’s interesting that they were consistently harder. The usual symptom of a Hunt that is undertestsolved is that some puzzles are much easier than expected, and some are much harder than expected. When you don’t have enough testsolve data, errors tend to go both ways. Here the errors went one way.
In Puzzup, puzzles are rated 1-6 in difficulty, and I believe those ratings were pretty consistent among our puzzle drafts. They just weren’t consistent with the stated rubric. A 3 on the scale is marked as “comparable to a puzzle in The Ministry”. Looking at some puzzles that averaged a 3.0, they were certainly not Ministry difficulty. Even the inside baseball solve times of teammate testsolving teammate’s puzzles are longer than our Ministry solve times. But they are easier than puzzles that averaged 4.0 difficulty or higher.
My sense is that there was a lot of independent overextrapolation on what a full-size Mystery Hunt team could do, relative to the 2-4 person testsolve groups we had per puzzle. The very common description of Mystery Hunt is that it’s big, and can support puzzles that can’t exist outside Hunt, and a number of puzzles I testsolved felt like Teammate Hunt puzzles, except larger. I think what is now clear is that the average Mystery Hunt puzzle ought to be easier than the average Teammate Hunt puzzle. Recommended solve times for puzzles started too high, puzzles got written to that bar, and other puzzles were written referring to that too-high bar.
If we had ever revisited a Ministry puzzle around the middle of the year, when feeders were getting written in earnest, it would have been very obvious that our difficulty calibration was off. But why would you solve a puzzle from an old Mystery Hunt, when there are a bunch of puzzles to testsolve for the upcoming Mystery Hunt? The clock is ticking, after all. Maybe the answer is that yes, you should actually go solve 1-2 old puzzles in the same conditions as your testsolves to calibrate your ratings. If you ever do this, let me know, because I have never, ever seen it done or heard of it being done. Usually, you assume your calibration is correct.
Calibration Part 2
The reason I point to calibration as the most important issue is because it has a lot of more silent downstream effects.
Throughout the year, we felt perpetually understaffed for testsolving. I agree with Eric Berlin’s comments on Hunt difficulty, where he says large fractions of your Hunt should testsolve in under 2 hours. However, I thought it was interesting that he casually mentioned testsolve teams of four to eight people. We would have killed to regularly convene four testsolvers! Our lower bound was often two to three people, and getting 5+ people was logistically challenging enough that it only happened for puzzles where editors could really push their importance (metas, mostly).
I think some people might have a mental model where making a puzzle is like placing one brick at a time, and you grow from a good 5 minute puzzle to a good 10 minute puzzle and so on, until you hit your time target. Anyone who has written a puzzle can attest that this is really not how puzzle writing works. As an art form, puzzles are partly defined by how well they fit together as a cohesive whole. You can have a multi-step puzzle with very disconnected steps, and it can even be fun, but it’s not what people imagine when they think of a good puzzle.
Usually what happens is that you start with some idea, and you try to expand it, as if you’re inflating a balloon. Holes will appear and you’ll tape over them, testsolvers will say it isn’t fun and you switch out the material, but eventually it comes together. And at the end, you’ve got a puzzle. But this can make it quite hard or time consuming to revise a puzzle to be shorter, because of how it builds on itself.
Out of curiosity, I looked up author data from 2018 to 2023, and plotted each author’s writing contribution to that Hunt. Authors are ordered from most prolific to least.
|
|
|
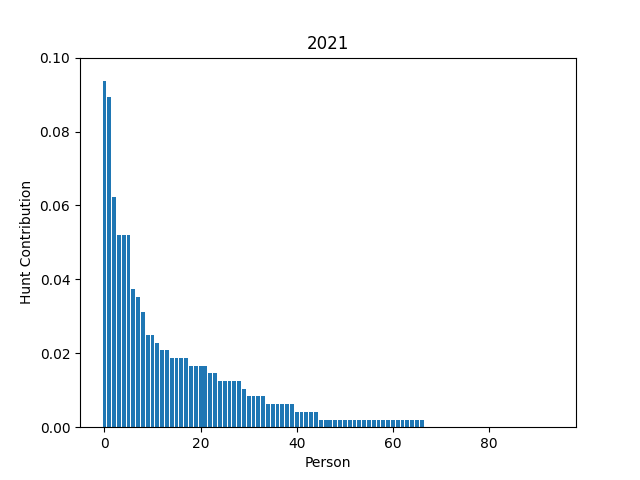
|
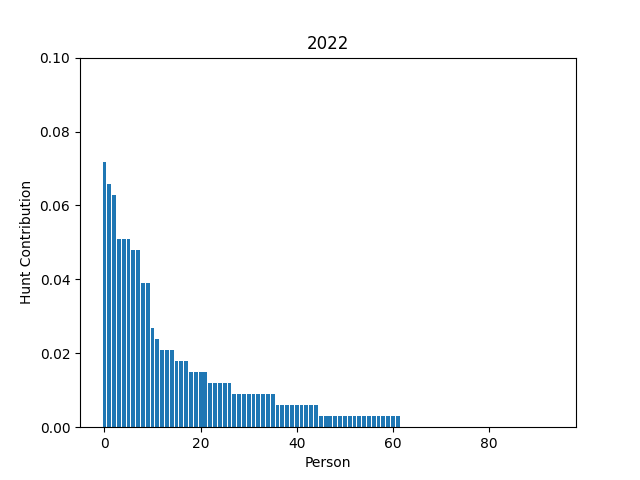
|
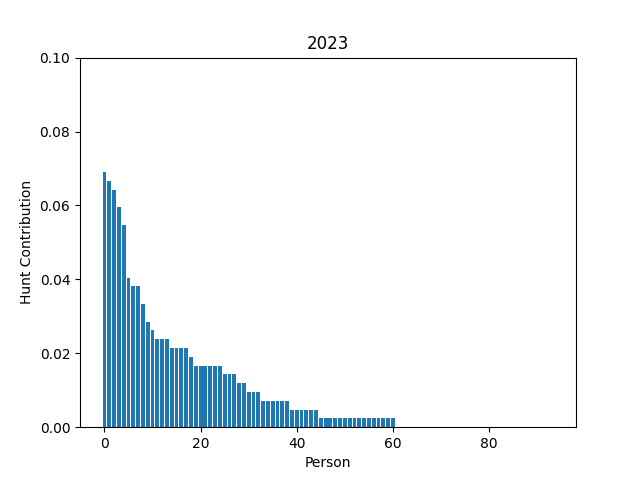
|
The 2018 Mystery Hunt is an outlier Hunt written by Death & Mayhem, one of the largest teams every year. Otherwise, Mystery Hunt is remarkably stable at around 60-65 puzzle writers per year. Left Out and Setec won with around 60 people, and ended with 60ish writers. Galactic was I believe around 80 people at time of win, and ended with 60ish writers. teammate won with around 55 people, and grew to 60ish writers. If every team has 60 writers, and teams work equally hard every year, and the distribution of work per person is similar, it seems reasonable to assume every year gets the same number of puzzlemaking hours.
If puzzlemaking hours are constant each year, and teammate started with a difficulty bar that makes puzzles 1.5x longer than they should be, the only way that’s possible is if every puzzle had 1.5x fewer testsolving iterations. There’s no other way to fit it into the fixed time budget. You cannot push one up without pulling the other down.
The standard bar for puzzlehunts is two clean testsolves, but it’s worth considering why the bar isn’t three or four clean testsolves. The answer is that time is finite, and to write a puzzlehunt you have to ship things. We started with a bar of two clean testsolves, but had to relax it to two clean testsolves of every step across all testsolves. Even still, testsolving ended up going to the wire. I suspect 1.5x fewer testsolve iterations is why. Much of the later testsolve iterations are the ones where you observe the long-tail of solve experiences and revise the puzzle to be smoother and cleaner. A lot of puzzles that could have been edited more were not, because they were written at the end of the year and editing for late puzzles became more perfunctory to catch up to our internal puzzle deadlines.
If a puzzle got rated as fun, it probably went in as is, even if it may have been too long. Part of following the fun is to not throw out things that testsolvers have told you are fun. I think that is totally fine. The problems arose when a puzzle was rated as sort-of fun, and editing it would take a lot of time - those puzzles were rounded to “let’s ship it and move on”.
The provocative way to put it is that we knew we had some clunkers, but we understood exactly how they were clunkers, and a clunker was better than no puzzle at all.
Although there was a miss on overall difficulty, most negative feedback I’ve seen on individual puzzles mentioned flaws that authors knew about before Hunt. I remember Palindrome saying the same thing - that most feedback was framed as “you overlooked this problem”, but they usually had not overlooked the problem and had left it alone to fix bigger problems. I think this feedback hurts the most, because you knew the problem existed, and know why you did not fix it at the time, but that doesn’t change that the problem is still there and made someone sad.
(Please don’t let this stop you from pointing out flaws in puzzle feedback forms though. I think authors know what problems exist but don’t always know what problems people will consider important. Feedback forms are a way to see which problems are repeated most often.)
What actionable advice would I give about this?
- Do difficulty sanity checks more often. Even if the estimates are incredibly noisy, take them seriously, because they’re all you’ve got.
- If puzzle difficulty is either trending too easy or too hard, raise a warning early. The goal in a Hunt is to create 150+ units of fun (puzzles). Creating fun is harder than creating difficulty, and revising difficulty can be hard once you’ve made something fun. You will have better odds of success if you keep old puzzles as-is and update length requirements for new puzzles to adjust the average.
- It is okay to push for puzzles that are easier to iterate (closer to well-known puzzle archetypes). Conjuri feeders were told to act this way, due to the late answer release, and I think those puzzles came out better. The shift to encouraging such puzzles should probably have happened sooner. (Team leadership knew and considered this option, but chose to spend hack weekends prodding people to finish their existing drafts of complex puzzles, rather than start new drafts of simpler ones.)
Testsolve Affinity and Bias
A team tends to do better at testsolving its own puzzles, because teams tend to grow around common interests, or people get pulled into interests of people on the team.
I want to talk about something more specific. Midway through the year, we created a “testsolving logistics” position. Normally, authors were responsible for soliciting testsolvers. This was taking up a lot of time. Authors would feel bad if they only got 2 people to sign up for a puzzle that wanted 4+ solvers, and not everyone is good at cat herding. So we created a testsolving lead. The testsolving lead volunteered to be spoiled on testsolving requirements for all puzzles in Hunt. Every team member filled out a survey with puzzle preferences and availability. Authors would describe their hours estimate and number of people estimate, and the testsolving lead would connect A to B, scheduling testsolves and building + wrangling testsolve groups.
This definitely saved time, and people in off-peak hours (i.e. Europe and Asia time zones) felt having someone handle their logistics allowed them to testsolve more. However, in retrospect it may have done too good a job of pairing testsolvers to puzzles. Math puzzles were routed to math people, geography puzzles were routed to geography fans, and so on. I’m not saying every puzzle was directly routed to people who’d have an easy time with the puzzle, but that was definitely a bias of the selection process. Someone having a spreadsheet of everyone’s preferences and availability is different from someone posting an async message and taking the first N people that sign up. It may have created the testsolve affinity problem at an individual level, rather than just the team level.
I guess the advice is…don’t do this? Don’t create a role that will save you time because it will have subtle biasing effects? I don’t know, that might be the correct conclusion, but recommending something that makes Hunt take longer to write sounds completely insane. Maybe it’s okay if the lead is less aware of puzzle specialities, but this seems hard to balance, sending a person who doesn’t like word puzzles into cryptics hell isn’t a good outcome either.
The more obviously good advice is that you should make sure there are off-ramps for killing unproductive testsolves. In testsolving, we only did formal feedback after groups had solved the puzzle. Some testsolves got very stuck, and odds are they should have been killed early, or we should have pushed people to write testsolve feedback throughout the solve. I tried to write feedback-so-far every time we paused a testsolve, but this was not a universal practice, and asking for puzzle ratings right after the solve may have biased difficulty estimates down.
Starting Big Puzzles Is Hard
During testsolving, you are usually encouraged to stick with a puzzle, so that other people don’t need to be spoiled and can be saved for future iterations. You convene at a fixed time, and start a puzzle with your full group at once.
When testsolving Moral of the Story, I thought it seemed okay. We had four people doing the first step and were able to speed through it pretty quickly. Then the rest was very parallelizable after the a-ha. We did not have much trouble and rated it decently high on fun.
In the live Hunt, it was less popular. Now, part of this is because the relevant Wikipedia page was edited after testsolving, in a way that made the puzzle much harder. But part of it is also that in a real Hunt, teams are roaming to decide what puzzle they want to work on, then puzzles accumulate people over time. The start of the puzzle was grindy in a way that was not exposed in testsolving, because both clean testsolves had started with a larger group of people.
It is a less important factor, but assume that tolerance for grind in a real Hunt is lower than tolerance for grind in testsolving.
Complexity and Scope Creep
teammate wrote some wild puzzles this year. Some wack metas, some crazy feeders, all sorts of stuff. Let me go requote the team goals from the start of the year.
- Unique and memorable puzzles
- Innovation in hunt structure
- High production value
- Build a great experience for small / less intense teams
It’s possible we overreached in trying to deliver innovation in both puzzles and hunt structure. Every year, you get a certain amount of complexity budget, limited by your available person-hours to design and testsolve puzzles. We spent a lot of it early when deciding to create the AI rounds, then spent more on the Museum metameta structure, then more on Innovation, then more on reusing puzzles between Museum and Wyrmhole.
The gimmicks also made it hard to shuffle puzzles between acts if they tested harder than expected, although I’d guess this effect was smaller. We have shuffled puzzles between intro and main rounds before in Teammate Hunt, if they test much harder or easier than expected. This happened a bit in Mystery Hunt, but not very much. Structural requirements differed more between rounds, and puzzles often had to be designed for the round they fed into.
I think there was a compounding effect, where creating more complicated hunt structures made feeders release later, which created more time crunch for writing ambitious puzzles, and the ambitions of both grew over time. Here is a message from all the way back in January 2022, when we started theme ideation.

teammate does rise to the occasion of the constraints we set for ourselves, but not without a lot of effort and struggle. Teammate Hunt 2020 started design with one Playmate game as the final runaround, and ended with eight games throughout the Hunt. Teammate Hunt 2021’s design proposal for the Carnival Conundrum said “7-9 intro puzzles, 7-9 main round puzzles per half, 6-8 pairs of puzzles”, and the final hunt ended with the top of each band: 9 intro puzzles, 9 main round puzzles per side, 8 pairs of puzzles, and each pair was more like 2.5 puzzles worth of effort. I was not in the design process for Hall of Innovation, but I remember someone telling me it also grew in scope a lot from the initial proposals. (It started writing in April 2022 and was still going through touchups in January 2023.)
I don’t know if this is an issue other teams will have. As a team we were off a streak of creating two well-received puzzlehunts and had some internal pressure to one-up ourselves and dust off ideas that could only work in Mystery Hunt.
My guess is that you can make a hunt with complex hunt structure, and you can make a hunt with complex puzzles, but you should give some pause before trying to do a lot of both. Still, I would rather people try to push Mystery Hunt than feel required to play it safe. I want to see the new ideas constructing teams come up with.
Time Unlocks
This year, rounds were time unlocked as a whole, up until Reactivation, and no time unlocks were done past that point. I’ve seen some speculation that we did not time unlock past Reactivation because doing so would have spoiled the answers to Reactivation. Personally, no, I don’t think that mattered. If a team wants to see more rounds they can probably live with skipping one puzzle of Hunt.
I’d say the main reason we did not time unlock past Reactivation was because the story was integrated so strongly into the Hunt that we didn’t have a good answer for how to time unlock past it. The entire point of Reactivation is that it is a breaking, irrevocable change in how solvers use the site, and the solvers’ objectives with respect to Hunt, and it is triggered directly by solving Reactivation, rather than a skit where teammate described the story. This was heavily woven into how the site functioned. Solving Reactivation would force the Factory to shutdown and make the Museum site 404, saying “Team X broke Mystery Hunt”.

We did not have an answer for how to time unlock a team past these changes, which were required to make site functionality work. You don’t just make a site start 404-ing without saying why beforehand.
A lesser but still important reason is that we had pulled a literal all-nighter verifying site behavior assuming the narrow path of a team progressing through the Hunt normally, and did not have any time to verify behavior if story state and solve state diverged out of that narrow region. Even the relaxation of 4/4 metas to 3/4 metas to unlock Reactivation caused Hall of Innovation to stop working in some edge cases until we fixed it live. This was part of why it took us a while to set up a public access team, we kept running into bugs tied to a team that had 100% of the story unlocks with 0% of the solves.
I think the devil’s advocate argument is that not all teams care about story, and they would have gladly taken discordant UX to see new puzzles. But teammate is a team that does care about story, to the point that story is occasionally allowed to make the user experience of the site worse if it makes the story resonate better. This is not something that any other team does.
There was probably a way to make time unlocks work, if we made them self-service, gated them on scheduling a team interaction with teammate where we could break the fourth wall and describe the story beats teams were skipping, and did the tech work required to support skipping required cutscenes and bottlenecks. They are all solvable problems that are not solvable when your team’s top priority is getting Mystery Hunt to finish.
Once again, I am not sure if this will be a challenge for other teams, because it seems likely they will face fewer challenges in implementation. I think the only viable solution to this is keeping time unlocks in mind from the beginning of the design process. They were not in our tech spec, the time unlocking that does exist is only whatever I was able to set up in side project time, and this made it hard to retrofit time unlocks later.
Difficulty Buckets
One of the common points of criticism is that the intro round was not really an intro round. Some of the puzzles were quite involved and difficult.
I think it is more accurate to say that the Atrium was not designed as an intro round. During writing, there was guidance for three difficulty bands: Museum puzzles, Factory puzzles, and AI round puzzles. There was then no further guidance within that, and puzzles were to be ordered afterwards by hunt exec. This has never been a problem in past Teammate Hunts, where the intro round was 8-9 puzzles. Ordering within the Museum was done about two days before Hunt ran.
There were 40 puzzles among the Museum rounds, and all rounds had some tricky puzzles in them. This left a trilemma where not all three could be true at once:
- Puzzles are mostly ordered by difficulty.
- A meta for a round is unlocked only after all its feeders have unlocked and a solid fraction of those feeders are solved.
- A meta is unlocked early in Hunt.
teammate ended up picking the last two, and this created the perception that Atrium was the intro round. If we had known how hard Hunt was going to be, we probably would have picked the first and last instead. This would have looked like starting with 3-5 rounds, where only their easy puzzles were unlocked. Some of the Museum metas are not very backsolvable or doable from partial information, and I think it would have been safe to unlock those earlier. It’s still not ideal if you can’t get enough feeders to solve them until much later, but having the meta is at least more exciting psychologically.
I’ve been told puzzles were ordered by difficulty in the December speedrun. There was feedback that it was weird that solving a puzzle in a round would unlock puzzles in totally different rounds, rounds would somtimes have all-but-one feeders solved with no meta open, and there was no way for a team to concentrate effort in a single round if they wanted to focus on solving that round’s meta. This feedback made hunt leadership change their mind and adjust unlocks to the current Hunt, and this is now pretty conclusively considered a mistake. I think this is easy to say in retrospect though. In the universe where the ordering doesn’t change, teams that normally solve 20 puzzles are likely upset their puzzles are scattered across 5 rounds and they never have enough data to solve any metas. (This did happen to some teams for the Emotions round in Mystery Hunt 2018, for what it’s worth.) The ordering change did avoid that - by creating a bigger problem in its place.
Now, the real fix is to make sure you are not in this trilemma to begin with. Three buckets was not enough buckets. There should have been more difficulty divisions within the Museum / Factory / AI round puzzles. The curve would have been smoother if Atrium was easier among Museum puzzles, Factory Floor was easier for Factory, and Wyrmhole was easier among AI round puzzles. And maybe you just cannot have an intro round of more than 10 puzzles in a modern Hunt.
(Just as one final point: although I am framing puzzle ordering as if you should order puzzles from easiest to hardest, this is just one of many criteria people can use for puzzle ordering. Variety of unlocked puzzles, avoiding too many grindy puzzles at once, avoiding too many a-ha reliant puzzles at once, dodging difficulty walls, and so on are also all important. These criteria often compete with each other, making optimizing all of them hard. I have literally been in 8 hour long meetings for ordering puzzles in hunts that were 1/4th the size of Mystery Hunt, so I don’t place much blame on mistakes made here.)
Small Team Objectives
One of the experimental decisions we made was to have the discovery of the Puzzle Factory be the equivalent of solving the 1st meta as a small team objective.
Setting aside the difficulty of the opening puzzles, how well this worked is probably directly related to how cool you found the Puzzle Factory and what expectations you had around Hunt. If you went into Hunt with the goal of solving 1 meta, you may not have been hyped to unlock a new round with new puzzles instead of more Atrium puzzles.
We did a lot to funnel teams towards unlocking the Puzzle Factory, including gating the release of the Atrium meta at > 7 solves, since 7 solves was the point the loading animation became infinite. In the original hunt unlock spec, a team can hypothetically solve 11 puzzles without solving the loading animation. It is literally impossible to get enough Atrium solves in the first 11 puzzles to unlock the Atrium meta, since too many Atrium puzzles will be stuck in an infinite loading state. I know some teams were not happy about this, especially if they did not figure out the loading animation was a puzzle.
I’ve been told this was discussed to death, and the conclusion was that if a meta was unlocked before the loading puzzle finished, the most likely outcome was that teams would only look at that meta, and no one would look at the loading animation for a while. I don’t think the argument is wrong. But as implemented, even after solving the loading animation, teams were often 1-3 solves away from unlocking the Atrium meta, since they needed to solve the now-loaded Atrium puzzles to get the meta they wanted.
The issue was that we created an implicit constraint based on the number of solvable Atrium puzzles. If we wanted to gate Atrium meta until after the loading puzzle was solved, it would have been better to create the explicit constraint and directly gate the Atrium meta on solving that puzzle (i.e. make the unlock threshold something like 5/9 Atrium puzzles + loading puzzle). That would have hit the design goal more directly, without creating an awkward overhang. After we’d sent out the loading solution email, we did cut Atrium meta unlock down to 5/9, now that directing teams there mattered less.
Story-wise, the in-story version of teammate is trying to not draw attention to the Puzzle Factory. Teams were supposed to feel like they were breaking the rules by exploring the Puzzle Factory. I think that created tension with how to make teams feel like they had done something important. The original theme proposal had a story interaction with MATE immediately on unlocking the Factory, where MATE would confront solvers but let them explore anyways. I think it got dropped among other TODOs, but probably would have helped here.
I suspect future teams will not have this problem, because they will just make solving the 1st meta the early objective for small teams.
Leadership Positions
Although we had accessibility checks throughout our Hunt writing process, we didn’t have an accessibility lead until quite late, and this was declared a mistake in retrospect. We cared about accessibility but it was something that people had to advocate for individually, and the benefit of having an accessibility lead is that it empowers someone to make a fuss.
Our positions we wish we had in retrospect: a program manager to handle prioritizing tech issues, and a small / new teams advocate. We had someone unofficially argue for new teams during Hunt and I think it was helpful. As for a PM, maybe other teams will not need this if they do less tech than we did.
Unordered Advice
Here are some smaller points that I feel less need to elaborate on, which I think are still important. This is not good prose, but, whatever.
- Hunt writing is very much a marathon. Make sure you are not burning out too early.
- Pay attention to the processes you’re creating. Hunt is big enough that there are pretty significant benefits to improving them early.
- Disasters will happen, this is just what it is like to work on a big project. I would stay positive about them, usually they are fixable.
- You will not always get your way, this is also just what happens in big projects. Try to deal with it.
- Puzzle writing seems to be yet another thing that follows Zipf’s law, with lots of work on a few people and more work on the long tail. Let me just put in the team contribution graphs again, they explain it better than I could.
|
|
|
|
|
|
|
|
|
- Remember to structure things such that the long tail of one-off contributors have something they can do. You are going to want all the help you can get.
- Hunts empirically need around 60 writers. If you’re a team thinking of trying to win Hunt, and are smaller than 60 people…then, well, you should have an idea of who you’ll try to recruit.
- Absolutely do not feel obligated to do as much tech and art as teammate did in this Hunt. We went all-out on both because teammate has a lot of artists and a lot of software developers, as well as active experience with running complex hunt websites. Out of recent Mystery Hunts, Galactic’s and teammate’s are easily the most tech-heavy. It is not a coincidence that both Hunts were written by teams that ran yearly puzzlehunts with a reputation for interactive puzzles. I do not think our Hunt site would have been possible if the tech team had not written puzzlehunt code in the same codebase for much of 2020 and 2021.
- Mystery Hunt got a lot more popular during the pandemic. For reference: the 2020 Hunt had 150 teams and the 2023 Hunt had 300 teams. Keep an eye on things that scale with the number of teams (hints, answering emails, scavenger hunt judging). Make sure your flows there are seamless. I would be shocked if answer call-ins came back, no team is equipped to handle 2x the phone call volume.
- Mystery Hunt is also becoming more multicultural. There are a larger number of foreign teams where English is their second language. Maybe this is PTSD from hinting non-native speakers through Inscription, but consider having your intro puzzles not depend on fluency with English language or US culture. Otherwise something like this might happen.
- Read all the post-Hunt posts you can to see how people react to Hunt, then don’t take them too seriously. The class of Mystery Hunt writers is usually biased towards top teams and doesn’t reflect everyone.
So…Why Do People Write Puzzles?
Look, man, I don’t know. It’s a thing to do? This was touched on a bit in CJ’s post about Mystery Hunt. That post argues that puzzlehunts are passion projects made by fans. New hunts come from fans wanting to pay back towards the fun they’ve had before.
I think this is true. Most of the reason I got back into puzzle writing was because I wanted to marry my niche My Little Pony interest with my niche puzzle interest, and was insane enough to follow through. The MLP fandom has always had a culture of creation and going hardcore if you find something to be hardcore about. “There is no price for passion, so everyone does what passion demands.”
Although passion is a good answer, it’s missing the reasons I kept writing puzzles. In the long run, I’ve gotten more motivation from the higher-level process of figuring out how to create an interesting solve path, and making a puzzle rhyme with itself as much as possible. Designing a puzzle is itself a puzzle, where you’re trying to figure out what steps are interesting and guess what wrong turns a solver could make. It is a very direct exercise in identifying the first place a testsolve started or could start going wrong, and finding what to do about it. It is a game where you are very limited in what information you can give, because the nature of puzzles is that every bit of extra information can be misleading. It’s an artificial challenge, often made in a constraint prison of your own creation.
It’s fun to participate in that challenge, but the trade-off is that it’s a pretty poor way of relating to people. The difficulty of design is hard to explain to people who did not live it. The core tension between puzzle solver and puzzle constructor is that puzzle solutions are not obvious. They must be indirect. You must leave enough space for solvers to work with the puzzle and discover the answer for themselves, since that is what puzzlers live for, but that always opens the possibility for failure.
The key to making a detective game fun to puzzle out is that you have to give the player as many opportunities as possible to be wrong. If you steer them through finding the clues and give away the answer anyway, then they can never be wrong. If you give them three dialog options to pick from then it’s pretty easily brute forced. Meanwhile, [Return of the Obra Dinn] has you fill in multiple blanks that all have multiple possible entries, and there could be hundreds if not thousands of wrong combinations. And you can’t brute force that, your only recourse is to actually be smart enough to figure it out.
(“Great Detective Games Let You Fail Miserably”. Also, play Return of the Obra Dinn, game’s great.)
If it’s impossible to get completely lost, then it’s not a puzzle. If you get completely lost, you will probably not appreciate the puzzle. That’s how it goes. On some puzzles I’ve written, I’d be satisfied if just 1 person had fun solving it end-to-end. There are things I get out of the puzzle construction experience that do not require the puzzle to be solved, in the same way I get things out of the writing experience that do not require people to read it. I’d say this is my answer to why people spend so much time creating such ephemeral experiences.
And, in the same way as blogging, I would be lying if I said that was the only thing that mattered, because as much as I get from doing it for myself, there are things I get from broadcasting things as well.
AIs and Puzzles
teammate has an unusually large number of people who work in machine learning, but I don’t think this had any role in our decision to write a hunt about AIs. The rise of increasingly good diffusion models and ChatGPT was convenient for making our hunt feel topical, but I did hear it caused late revisions on how to present the Hunt’s story in a time where automated creativity is a hot button issue.
We tried using ChatGPT to solve cryptics or write puzzles out of curiosity, and found it really could not do either, even with lots of prompt attempts. In general, people’s intuitions about what ML models can do is incredibly bad. Much like 5D Chess, people really like to assume AI acts according to their own conceptions of how it ought to act like, rather than the reality of what it is. Unlike 5D Chess, people are fascinated with AI and love to talk about it.
Although models are pretty bad at solving puzzles right now, I can easily see them getting better. The main issue with GPT-3.5 was that it was really bad at mixing semantics and syntax, a key duality needed for puzzle solving. GPT-4 is a lot better at this and it seems reasonable a future iteration could be good enough to solve puzzles for real.
I’m not sure where this goes. I don’t want to be depressing, but my expectation is that at some point we will have ML models that are good enough to solve puzzles, yet not good enough to generate interesting puzzles, and we’ll have to decide how to adjust the current status quo where all computer tools are fair game. But even then, MIT Mystery Hunt will continue. It is too resilient to break from something like that.
The Start of the Rest of My Life
I do not have any burning puzzle ideas left to write, but I told myself this in January 2022. In the “do we want to win Hunt” survey, I said I did not expect Mystery Hunt to encourage me to work harder on puzzles, and then it did. I claimed I would work 10 hours/week, and here is the true chart.
(Excludes the week before Hunt, which was around 110 hours.)
I have, very continuously throughout the year, asked myself if this was all worth it. The answer was not clearly yes.
Still, to flip the question on its head, if you asked me what deal I would take to agree to never write puzzles again, I’m not sure what it would have to be. Right now, if you offered me a thousand bucks, I would immediately say no.
Will you see me again in a hunt’s author list? Uh, not sure. Ask me later. I care about puzzles a lot. I wouldn’t have written for Hunt if I did not care. That continues to be true. Puzzles are cool. I’m just tired and want to do other things in my free time. I want a hobby, not a job. We climbed the mountain, and came back down. Everything afterwards is uncertain, but I am looking forward to putting Mystery Hunt 2023 behind me, and I can’t wait to see what happens next year.
Thanks to Jacqui Fashimpaur, Bryan Lee, Lumia Neyo, Nishant Pappireddi, Alex Pei, Olga Vinogradova, Ivan Wang, and Patrick Xia for providing feedback.