MIT Mystery Hunt 2020, Part 2
Now that My Little Pony: Puzzles are Magic has wrapped up, I have time to finish my posts about MIT Mystery Hunt 2020. And only well over a month after Hunt too!
This post is long. I decided to bundle all my remaining thoughts about Hunt into one post, to motivate me to finish it once and for all. This post will have spoilers for both MIT Mystery Hunt and Puzzles are Magic.
Before Hunt
Before MIT Mystery Hunt officially starts, people on our team like trying to identify hidden Mystery Hunt data before the hunt officially starts. This year, we had two targets: the emails from Left Out, and the wedding invitations.
Every email we got from Left Out had a different signature. There was “Like Pluto, Left Out”. Another said “Like J in a Playfair Cipher, Left Out”. Then there was “Like a cake in the rain, Left Out”. Some people felt this was just Left Out’s gimmick (every signature is about something that’s left out), but maybe they were a puzzle, so we kept track of all of them.
When we got all the emails about the overnight situation, all without custom signatures, I argued this was weak evidence in favor of the emails being a puzzle. The argument went like this: for the emails to be a puzzle, Left Out would need to make sure they sent out N exact signatures for some number N. If the signatures were a puzzle, any surprising emails they needed to send (like the ones for the overnight situation) shouldn’t have custom signatures, and none of them did.
Someone else pointed out that given the seriousness of the situation, Left Out wasn’t likely to include a jokey signature, whether or not the emails were a puzzle. That convinced me the emails weren’t a puzzle.
The wedding invitations, on the other hand…

We recognized the first invite was a reference to the 2011 MIT Mystery Hunt invitation, but the second invite looked weirder. Why did the alignment look a little off center? Why was WED LOVE YOU TO JOIN US! missing an apostrophe in WE’D? Was it just “WED” for “WEDDING”, or was it something more? And so on.
Last year, our “is this a puzzle” theories were all in a channel named #innovated-shitposting
(later renamed #ambiguous-shitposting).
This year, it was #wed-love-u-2-shitpost. The working theory was that “join us”
meant “draw connecting lines”, “to” meant “connect the 2s”, “love” meant
“connect the hearts in 12:00 EST”, and “you” mean “connect the letter Us”.
So, uh, yeah, that’s where all those red lines come from. We also thought it might have involved folding, so we tried that too.
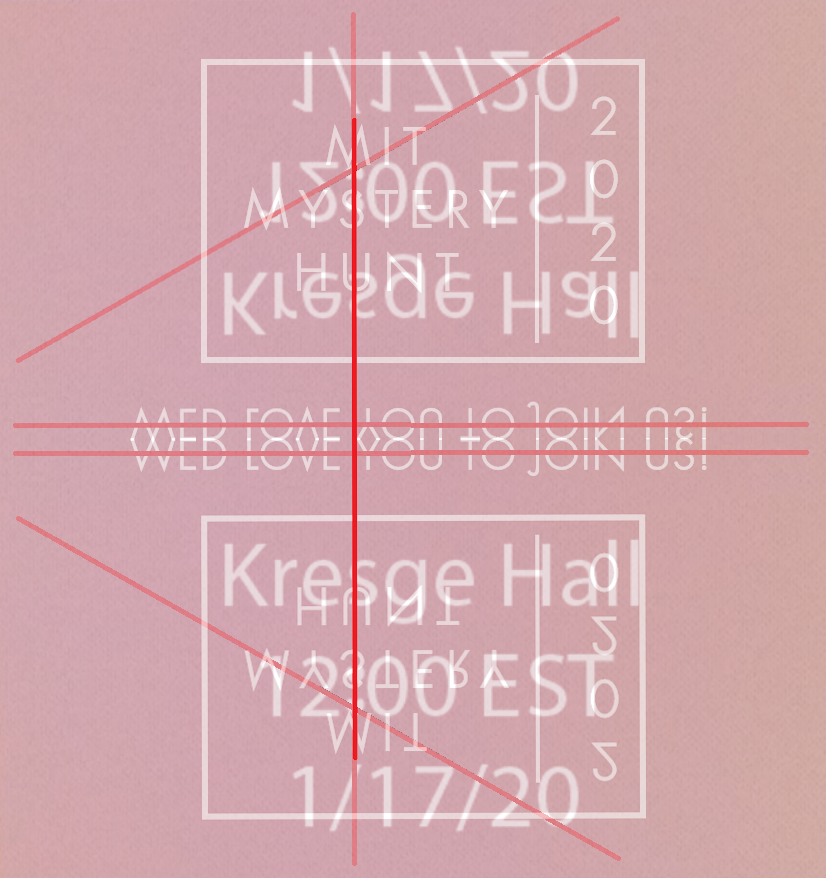
As I was boarding my flight to Boston, my position was that the invite was more-likely-than-not a puzzle (say, 60% chance), but it would come with a shell that we wouldn’t see until Hunt, so until then I wasn’t going to try anything.
Meanwhile, two teammates on teammate had a $20 bet on whether the email signatures were a puzzle. One was adamant they were, the other was adamant they weren’t. They agreed to a bet, and to quote the loser, “I got a lot less confident in my bet after I read all the emails.”
The day before hunt was spent socializing, figuring out who would get power strips (me), and figuring out our Mystery Hunt Bingo for the year. One teammate refreshed until they got a board that would give a bingo if it had puzzles we wanted to see. (“I like this board, because we’ll get a bingo if there’s a puzzle about video games and a puzzle about anime.”) But, was cherry-picking a bingo board ethical? We discussed it at the social, and Rahul proclaimed “It’s okay to cheat at bingo”. Cherry-picked bingo it is.
We did get the bingo line that used video games and anime, although it was a close call. We needed an anime that came out in the past 2 years, and Wanted: Gangs of Six came through with JoJo’s Bizarre Adventure: Golden Wind.
A Tangent About Guessing
In the minutes before Hunt, we learned there would be an automatic checker this year. That’s as blunt a segue as any to talk about guess rates.
As has been said many times elsewhere, teammate is an outlier on submitting tons of guesses during Mystery Hunt. Speaking personally (and definitely not for others on the team), here’s why I tend to guess a lot during Hunt.
To me, good puzzle solvers are distinguished by their ability to correctly generalize from limited data, solve around mistakes they’ve made in data collection, and rapidly form and discard hypotheses about how a puzzle works. More concretely, if you can reliably solve puzzles from 80% of the clues, it takes 80% of the time per puzzle. Except, in practice, it works out to faster than 80%, because the last 20% of clues are the hardest ones. The same principle holds for metapuzzles. If you can solve a meta from 60% of the feeders, then you get to skip the hardest 40% of that round, so you save more like 50% or 60% of the time you’d spend in a 100% forward solve.
Because of this, if you want to solve hunts faster, you should shortcut as much as you can, and that includes making low confidence guesses that rely on a few of your assumptions being true. The answer checker is a binary signal between “all your generalizations were correct”, or “at least one of your generalizations was wrong”, and although it’s a very low-bandwidth signal, it’s a signal that’s there. So if the hunt lets you be more aggressive on guesses, I’ll naturally submit a lot of aspirational guesses. It’s not personal towards the puzzle author - their puzzle is one of many puzzles within the cohesive whole that makes up MIT Mystery Hunt. I’m not going to abuse OneLook to solve a cryptic crossword by itself, but I may abuse OneLook to solve a cryptic crossword that’s part of a larger hunt, once I’ve gotten through all the clues that look fun.
Did this pay off? Here’s a chart of puzzles solved versus guess accuracy of that team.
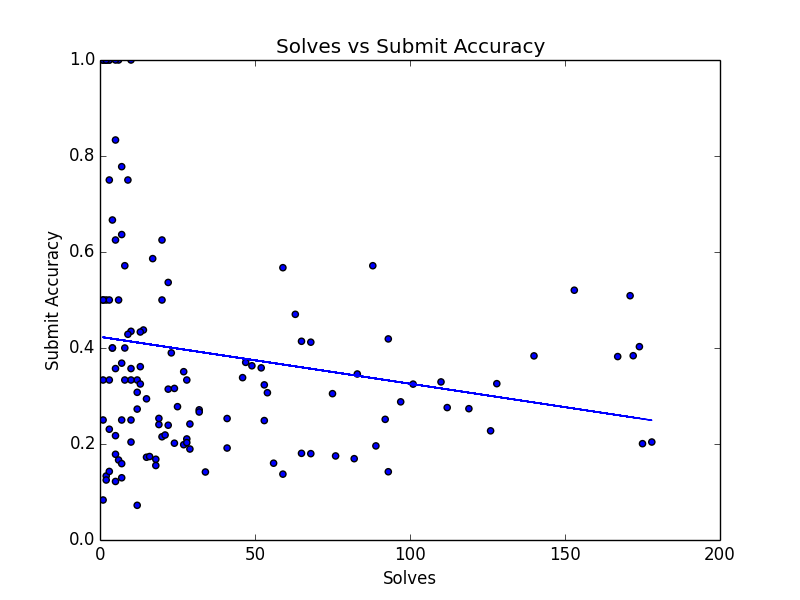
The trend line of this chart definitely suggests that teams with lower guess accuracy solved more puzzles. But hang on a second: there are bunch of teams with 100% success rate that only solved a few puzzles. Here’s the same plot, if we remove all teams that solved fewer than 10 puzzles.
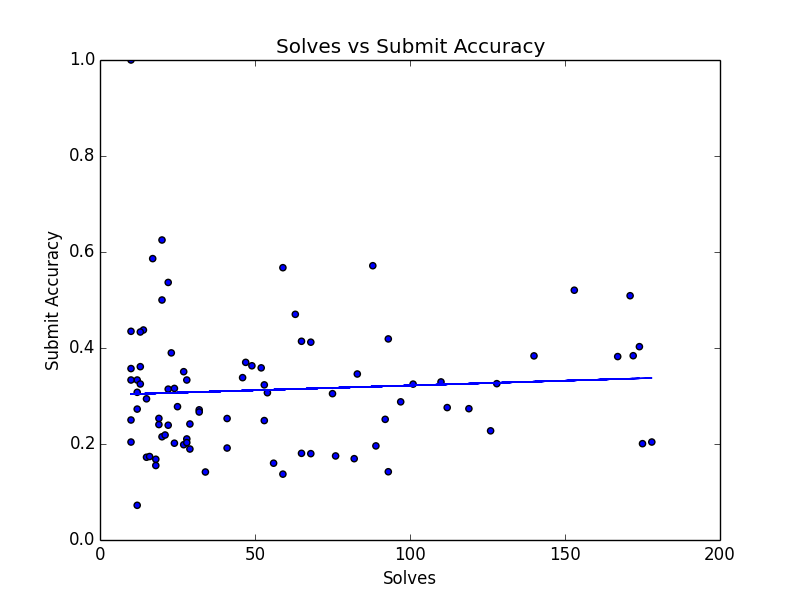
Now, the downward trend line is gone.
My feeling is that yes, teams that guess more did do better this Hunt. However, the size of that effect is small, and puzzles solved is still dominated by general solver ability and luck in how fast a team figures out the metapuzzles.
One other tangent is that I feel a lot of the discussion about guessing has focused too much on backsolves. I’m worried people will think high guess rates come mostly from backsolves. This isn’t true - crazy guesses come from both forward solves and backward solves.
During Puzzles are Magic, I got curious about forward solve vs backsolve rates. I went through the guess log, made a list of all answer guesses that looked like backsolves, and computed forward guesses vs backward guesses for each puzzle.
The results are linked on the full stats page. Excluding meta puzzles and endgame puzzles (puzzles that couldn’t be backsolved), across the entire hunt there were 4.38 guesses per forward solve, and 5.36 guesses per backward solve. So yes, backsolves did have more guesses on average that hunt, but it wasn’t by a big margin.
Admittedly, because Puzzles are Magic confirmed partials, and had very minimal rate limiting, we encouraged teams to submit more guesses than they would in a Mystery Hunt.
I don’t think Mystery Hunt should confirm partials, and I do think you want a strong rate limit if you’re doing automatic answer checking. MIT Mystery Hunt shouldn’t need the guardrails that partials give you. We added those guardrails to Puzzles are Magic just because we wanted an easier hunt.
Puzzle Stories
These stories are roughly told in chronological order, but I’ve grouped puzzles I worked on by round. During the Hunt itself, I jumped between rounds much more than mentioned here, so some stories are slightly out of order.
Grand Castle and Storybook Forest
I looked around a few puzzles at the beginning, but the one I started first was Goldilocks. I filled in a few clues, then moved to setting up indexing when I failed to get any more clues.
The next one I worked on was The Trebuchet, and here it was a similar story. By the time I got to the puzzle, they had Boggled a few words (the voice actors from Bolt), and after we realized the ammunition were all puns, the rest of the walls fell pretty fast. I identified a few more words (wtf SHAQ LIFE is a show??), then constructed the final wall. We expected the blocks to fall into place automatically, instead of acting like a dropquote. I noted we were a few swaps from GEORGE BAILEY, and someone solved it from FOE OF GEORGE BAILEY.
With that puzzle done, I jumped back to Storybook Forest. I got excited by Hackin’ the Beanstalk, immediately recognizing the tortoise-and-hare algorithm when typing random letters. I opened the sheet for it…and every single algorithm had already been IDed. Our team has too many CS majors. We had the ordering, and were a bit stuck on extraction, until someone threw a regex at it and saw SOURCE FILES was the first option. It was right.
I looked at Toddler Tilt, which no one had touched yet. However, I had trouble getting the toddlers to tilt in the right order. I noticed the people who joined me were getting it much faster than I was, and I decided my time would be better spent on the meta.
For the Storybook Forest meta, we had some tic-tac-toe theories. We had a lot of 9 letter answers, and the puzzle art was arranged in a 3 x 3 grid.
(9 puzzles, 3 x 3 grid, three animals in a row in the meta’s art. It must mean something!)
I tried extracting the same way the Dolphin meta worked from MIT Mystery Hunt 2015. This sort of worked, but some answers extracted 2 letters instead of one, and there weren’t great ways to use the 11 letter answers. I started looking for tic-tac-toe variants that might use 11 in an interesting way, and in the middle of doing so, someone who didn’t believe any of our tic-tac-toe work solved the meta.
With that finished, I went back towards The Grand Castle meta. We had 4 answers in that round, and after some false starts based on “stately” and “capital”, someone discovered the Texas panhandle. I immediately noted that the panhandle had 26 counties, but out of the final answer of OILMEN, A-to-Z conversion of our answers gave LMNO, which made us think it was an ordering. Each answer in this round was a two word phrase, and reading the word that wasn’t the county gave “MISTER RACHEL UNCERTAIN SIX”. I proposed that the 2nd words were going to form a cryptic whose answer was six letters. Someone noticed that “Rachel uncertain” might mean anagram RACHEL, giving CHARLE, which could complete to a famous ruler, CHARLEMAGNE. That sounded great! We tried it, and it was wrong.
The next feeder we solved was the E from OILMEN, and the second letters gave this grid.
| CRISPIN | |||
| MISTER | RACHEL | UNCERTAIN | SIX |
Ah, so clearly, we were going to fill in the box between CRISPIN and SIX, get two cryptics that shared SIX for the enumeration, and we’d combine them to get a 12 letter answer! We tried CHARLEMAGNES (plural), and that was wrong too. Someone found Six Flags Over Texas, which provided an ordering on the clues, and now that we had an ordering, A-Z letters looked much better, and we solved it.
Spaceopolis, Wizard’s Hollow, Balloon Vendor
With those rounds done, it was time to look at Spaceopolis. I watched our teammates sing karoake. I did data entry and indexing for the Masked Singer a-ha, but the extraction looked bad. While puzzling over the sheet, someone walked by and asked for volunteers to solve Magic Railway, the konundrum we had just unlocked. Two of us agreed. I played a mean house elf master for about an hour, briefly tried chemical elements instead of classical elements, and got the answer, GRACE UNDER FIRE. Checking the status sheet, we saw Karoake had been solved The two of us who left checked to see what we had missed. It turned out we had extracted the right letters, and just failed to read properly.
We unlocked TEAMWORK TIME: Hat Venn-dor, and joined the effort for that. In general, I really liked the TEAMWORK TIME puzzles, except for the ones where you only wanted 3 or 4 people interacting with the puzzle at once. But Hat Venn-dor was well-suited to lots of manic guessing, and I liked that. After that, some of us had a good laugh at No Clue Crossword, but we didn’t get it and had to backsolve the puzzle. We thought it might have been words that appeared in a crossword clue lookup when you entered “No clue” as the clue, but that didn’t seem very good. I forget exactly when we got the Balloon Vendor meta, but it was cute.
YesterdayLand
The next puzzle I did major work on was Food Court. The main thing this puzzle taught me was that I was horribly out of practice on probability. Back in undergrad, I definitely would have solved all of the math questions without issue. After solving one of the problems, I saw we had answers for most questions, so I started transcribing the probabilities into code to compute the steady state of the Markov chain. Another teammate had found an online tool for this, but said “it’s garbage, it’s only accurate to the hundredths place”. That actually would have been good enough for the puzzle, but due to incorrect data, we weren’t getting the right steady states. Given how the puzzle worked, it seemed clear we needed to check our work. I loudly went around asking people to help us do math, and was told three times that someone was on it. I wasn’t really listening (my mistake), and on the third time, they sat me down and explained that
- They knew someone who made Nationals of MATHCOUNTS.
- They weren’t doing Hunt, so it was okay to ask them for help.
- They solved probability problems in their spare time for fun.
- They were very fast and very accurate.
About 30 minutes later, they got back to us, saying “I believe three of your answers are wrong, I got this.” We fixed them, reran the Markov chains, and saw the steady states were all exact hundredths from \(0.01\) to \(0.26\), with small errors from floating-point approximation. So, that was that.
A Digression on All-or-Nothing Extraction Mechanisms
One big lesson I learned from making Puzzles are Magic is that you always want to check how robust your puzzle design is to errors. Solvers will always, always make errors in solving, even if your clues are 100% unambiguous. So, if possible, you want to make your puzzle robust to a few errors. For example, crosswords are naturally robust, because each letter is checked twice, once by the Across clue and once by the Down clue.
The less robust your puzzle is, the more likely it is that solvers will do 90% of the work for a puzzle without finishing, or they’ll apply the right idea and get garbage due to their mistakes. Either one feels bad. Things that make a puzzle less robust are partial cluephrases using uncommon letters, and all-or-nothing extraction mechanisms, where a single error cascades into complete junk, even with the correct extraction mechanism.
Food Court had an all-or-nothing extraction mechanisms, because changes to any transition probability must influence state probabilities everywhere else. Otherwise, Markov chain theory says it literally can’t have a unique steady state.
I don’t like mechanisms like this in a vacuum, but not every puzzle can be made robust without compromising its idea. The core idea of “you solve a bunch of math problems that seed a Markov chain” is compelling. So, in short, I liked this puzzle. I think you just have to accept the all-or-nothing extraction is a consequence of its design, and move on.
Back to YesterdayLand
Now we come to Change Machine. Oh boy.
I moved to this puzzle because I was told there was a lot of mindless drudgery that needed to be done to the spreadsheet, and I was too tired to do any real solving. The puzzle was all about the Omnibus podcast, and everything was IDed, but they had been IDed independently. Now that the Omnibus connection had been found, they wanted help merging all the data by Omnibus episode.
I was still confused, and at some point I said “Okay, it’s 3 AM and I’m very tired. I need you to give me idiot-proof instructions for what you want me to do.” Which they did, so props. After everything was ordered, I suggested indexing the KJ number into the Bible verse (treating KJ as short for King James, instead of Ken Jennings). Reading in episode order gave AD AMUSEMENT COMPANY IS KEY.
We were confused. During this process, one person had been reading the Ken Jennings subreddit, and discovered a Reddit post where someone asked what the hell was up with the RIDE ENHANCERS COLLECTIVE?
We had a mini mental breakdown. Was this seeded information from Left Out? Did AD COMPANY mean Reddit? Was this actually how we were supposed to solve the puzzle? I dug into the post history of the Redditor, to see if they posted on other puzzle subreddits, but all I found were posts on r/ottawa and r/Curling, dating back several months. This was made extra confusing because another Redditor had made Ride Enhancers Collective fanart in the middle of Hunt.

Applying the left-over offset numbers to RIDE ENHANCERS COLLECTIVE was giving good letters, but we were still confused about the life choices we’d made that led us to that moment. Solving the puzzle with ENCYCLOPAEDIA BRITANNICA, we were still incredibly confused and on the verge of a bigger mental breakdown. (Remember, this is at 3 AM, when the universe is a magical place and everything is funny in a cosmic sort of way.) After a bunch of “WHAT DID WE JUST DO AND WHY DID IT WORK”, we figured out that RIDE ENHANCERS COLLECTIVE was mentioned in an ad from the Omnibus episode that came out the weekend of Mystery Hunt, and we must have skipped a bunch of steps that would have told us to listen to the Omnibus.
Reading the solution, there were three cluephrases, and we only got the last one. So thank you, Omnibus fans. Your confusion about the RIDE ENHANCERS COLLECTIVE was not in vain, and your Reddit post provided just enough search engine signal for us to shortcut the puzzle.
Big Top Carnival
With that done, I looked at the new Big Top Carnival puzzles. I didn’t do much, until someone said, “Hey, so all our answers are Kentucky Derby horses”. We piled onto the meta and got to *I*R*D*R*, which we guessed was “something RIDER”. Noticing that horse names had mostly unique enumerations, we asked if anyone was working on a puzzle in Big Top with known answer length. The group working on Weakest Carouselink said they had (4 4). Finding PINK STAR as a horse option, someone proposed PINK SLIP. The Weakest Carouselink solvers said “that seems bad”, and I pointed out it was thematic to Weakest Link (you get fired), so we called it in and it was right. That gave us *S*I*R*D*R*, and within 30 seconds we went from that to “STIRRUP?” to “STIRRUP DRAMA!” to “AHHHHHH WE SOLVED A META WITH 5 OUT OF 12 ANSWERS”.
The really good backsolvers were all asleep, but we had 7 puzzles to backsolve, of course those of us awake were going to try. We got 3 in the next hour, got stuck on the rest, and left the backsolves for others to finish up as we went back to the YesterdayLand meta.
YesterdayLand Meta
One rather boring puzzle skill I’ve always been proud of is my diligence in filling out spreadsheets. When Jukebox first unlocked, I opened it, and carefully transcribed the given blanks, their arrangement, and the colored numbers into the meta spreadsheet. I made some notes about how I wanted the puzzle to extract, and went off to solve other puzzles.
After the Big Top Carnival flurry died down, we looked back at Jukebox. Someone got the modernized answer break-in, and I got a warm fuzzy feeling when my due diligence meant we could jump straight into filling everything out. I had DUBSTEP for modernized DISCO, which seemed okay. That changed to EDM MUSIC, which was worse, but then someone noticed we had the blanks for ELECTRONIC DANCE MUSIC, freeing up the seven-long slot for the modernized PENTHOUSE, PORNHUB. After a brief “oh no they went there”, we had enough to get to the READ UNDER COLOR NUMBERS cluephrase. We didn’t have enough feeders to get the meta, but I was getting pretty tired, and decided to get some sleep, trusting it would be done by the time I woke up.
Saturday’s Safari Adventure
After I woke up, I caught up on what had happened.
- The remaining Big Top Carnival puzzles had been backsolved.
- YesterdayLand’s meta was solved.
- We finally solved the scavenger hunt, after figuring out all answers in Creative Picture Studios were emoji.
- We had unlocked Safari Adventure.
I ended up contributing the most to Safari Adventure, which is to be expected - it was a really big round. For regular puzzles, I worked on Golden Wolf (figured out the Gashly kids a-ha), Lion (finishing one of the final NYT puzzles), and Sheep (looking up Mega Man characters, pointing out all the last words were 11 letters long, and spending an hour not indexing by game number until someone else tried it and solved the puzzle.) I also worked on Snake, where we got IAMB from *A*B, guessed TROCHEES just in case, then got PACES from PACESA (we had some errors that we guessed through).
I didn’t work on Hyena, but there is a fun story for it. The group working on it was convinced one answer was the letters in SRT, in some order, but they weren’t sure what. They decided that, well there were only 6 permutations, so…

Working on the second answer, they got the letters CAM, and again, they tried 4 of the permutations, but stopped there out of fear of answer locks. During the Hunt, we thought answer lockouts applied to the entire round. They didn’t want to lock out people forward solving Safari puzzles, so they abandoned it. Much later, we backsolved Hyena, and discovered the answer was one of the 2 permutations we hadn’t tried.
In the middle of Safari Adventure, we unlocked First You Visit…. At the time, we were split across 3 rooms, and it was really funny to hear the groans cascade across the hall as each room discovered the puzzle 5 seconds after each other. Out of Puzzle Traumatic Stress Disorder, no one worked on it, and we didn’t even backsolve it.
For Safari metas, I looked at a few. For The Cubs Scout, my incredibly-minor baseball knowledge helped with how to read the extracted letters. In Sam, I figured out the stars-and-stripes idea, but didn’t get the every other trick. For Zeus, we got Altered Beast really fast, but got stuck on how to extract. The person who eventually solved it said they watched an hour of Altered Beast gameplay, then was inspired to map everything onto BEAST. (Note that nothing about Altered Beast’s gameplay was relevant, except for what animals to use and the ordering of those animals.)
We initially thought the Tiger would be a regular puzzle that was part of 5 metas, which we would have to backsolve entirely. Once we got to a 6th meta that needed Tiger, we realized it had to be the metameta. The Safari metas were getting solved pretty fast, and not every meta solver noted what backsolves were left. In teammate’s tech setup, spreadsheets are made automatically for each new puzzle, but this breaks down when you’re collecting data for a puzzle that doesn’t exist! A group of us ended up making a Tiger spreadsheet manually. After unlocking the metameta, we transferred our manual sheet to the generated sheet, and while doing so someone got the Tyger Tyger a-ha, which just left finishing enough Safari metas to extract.
A PennyPass Postmortem
I haven’t talked about the PennyPass system yet. In this Hunt, teams would get PennyPasses. Each pass could be spent to unlock a puzzle in any open round.
I thought this was a neat choose-your-own-unlock-adventure, without the downsides of 2018’s experiment. In 2018, teams chose which round to unlock, which was cool, but it also meant you might randomly pick the hardest round instead of the easiest one. The organizers also had to be prepared for literally every in-person interaction as soon as teams passed the intro round. It hasn’t come back yet, and I don’t think it should. It adds randomness and tons of logistical headaches for not much benefit.
On the other hand, I wouldn’t mind seeing the PennyPasses again. They’re a nice way for teams to add help in rounds they decide they need help on. Our strategy was that unless we were obviously stuck, we would optimize for the width of the Hunt - the number of unlocked puzzles.
In each round, solving one puzzle unlocked one more puzzle in that round. So, solving within a round either kept your width constant, or decreased your width if you had no more puzzles to unlock in that round. This meant that we always used PennyPasses on the most recently unlocked round, because that round would have the fewest solves, and we’d have a +1 width increase for the longest period of time.
We had one PennyPass left, that was expiring in an hour, and the only round it was valid for was Cascade Bay, since we had unlocked everything else. We therefore had two options.
- Use it right away on Cascade Bay.
- Wait to see if we could solve the 10 puzzles we needed to unlock Cactus Canyon, and use it there.
It seemed really unlikely we’d solve 10 puzzles in an hour, so we spent the pass on Cascade Bay. The pass disappeared, but nothing happened.
We had already guessed Cascade Bay’s gimmick: puzzles from one level would “flow down” into puzzles below. But, we didn’t realize this meant the first meta bottlenecked unlocks in the next level. Our PennyPass wasn’t going to give us a new unlock until we finished more of Cascade Bay.
After the Hunt, there was a postmortem on whether we should have been able to infer that the PennyPass would work this way, based on Cascade Bay’s art. With our backsolving speed on Safari, we actually may have finished 10 puzzles before the Penny Pass expired, and we heavily needed more unlocks in Cactus Canyon at the end of Hunt. By the time the extra unlock kicked in for Cascade Bay, we had already figured out all three meta mechanics, and didn’t need more help.
teammate was tied with Galactic until Cactus Canyon, where they separated from everyone else. If we had been able to use the PennyPass on Cactus Canyon, we may have been able to keep pace. I believe we made the right call for the PennyPass in the moment, and even if we had kept pace with Galactic, I think they still would have figured out the Workshop metameta first, but it’s hard to say.
Cascade Bay
Now that we knew we needed solves in Cascade Bay, the call went out for unattached solvers to help solve puzzles in that round. We had solved Water Guns thanks to an insight from a remote solver, but that still left several puzzles to finish.

(The Pokemon we drew for Water Guns)
I saw my options were Breakfast Menu, or The Excelerator. I looked at the people solving Breakfast Menu, saw “heraldry Waffle House”, and went “This is amazing. I don’t want to do it.” The Excelerator it is!
It looked crazy, but we had the phrase FIND ELEVEN STARTING POINTS. The previous solvers had only found 10 red trigrams, not 11. On a second look, we found the 11th, and it was a decently smooth solve from there. I grinded through some trigrams, and confirmed we wanted to read horizontally along each chain rather than vertically, but it was someone else who noted the four letter words could all be treated as ranges. We had some trouble getting all the range formulas to work, because Google Sheets “helpfully” reorders ranges that are written in reverse order, but besides that it was neat.
Solving The Excelerator gave us the 4th solve in Cascade Bay, which was enough for the meta crew to get the Lazy River meta. For Coast Guard, we had variations on THROWN FOR A LOOP for ages, but were missing the P and L in the cluephrase. Our forward solves kept confirming letters in THROWN FOR A, and we didn’t solve the meta until we finally, finally got the P from a forward solve.
The Swimming Hole unlocked, the meta crew immediately got acid/base, they got some letters and told people they wanted the answer to end in NEUTRALITY, and I moved back to Safari because I figured they’d finish in a few more forward solves, and I wanted to try breaking open more metas.
Finishing Safari Adventure
We were quite close to the end of Safari when I got back. We were just missing 3 metas: The Trainer, Anne, and Ms. Cunningham. Meanwhile, we were stuck trying to take the index of the Tyger Tyger word inside the line it appeared, instead of converting the line number to a letter.
I took a look at Ms. Cunningham, which had no progress. After some false starts, I decided to look up who Ms. Cunningham was, which got me to TaleSpin. Coincidentally, the other 2 metas had break-ins at the same time, and everyone got really excited about finally closing out the round.
My TaleSpin break-in didn’t actually do anything, because we had already determined the Ms. Cunningham animals by process of elimination, and the given clues weren’t even the extraction order. In effect, my only contribution was convincing other solvers we had made progress when we hadn’t, but hey, I claim that still counts.
We solved Safari Adventure metameta with 10 of the 11 metas, got a message saying we should finish all the metas as well. and solved Ms. Cunningham a few minutes later, leaving just two things left: Creative Picture Studios meta, and all of Cactus Canyon.
Creative Picture Studios Meta
A few people had monopolized a whiteboard for several hours, brainstorming movie plots and moving emojis around.

They had made a lot of progress, including a backsolve of King’s Ransom minutes before an hours-long forward solve was about to finish.
First, there were 3 people yelling movie plots at each other. Then 4, then 5, then 6. There was a lot of shouting about letters to take, which emojis should go where, and guesses on where the missing movies would fit chronologically. A teammate turned to me and said, “There are too many people here.” The two of us left the room to leave it at 4 people yelling at each other, figuring that would be good enough. After 40 minutes (caused by two answer lockouts), they got it.
Cactus Canyon
I didn’t look at the meta in this round. I made small contributions to TEAMWORK TIME: Town Hall Meeting (left when I noticed it didn’t need many people) and Wanted: Gangs of Six (identified the ponies, Big Hero 6, some Watchmen, then left).
For Spaghetti Western, I looked up Spaghetti rules, and got stuck on how to figure out the starter words. Another solver bailed me out by getting the starter words, and with those, the minipuzzles got a lot easier.
Mine Carts was stuck for a long time on trying to pair the Left Track and Right Track carts. (Yes, we knew the counts didn’t work for this. Yes, we tried pairing them anyways.) Eventually we figured out we should form a chain between the carts in each track. Embarrassingly, I missed the My Little Pony chain. In my defense, our spreadsheet was a list of unpaired answers, so I missed that each mine cart mentioned the category we wanted. I recognized SPITFIRE was a pony (she has a fun pony music video), but missed LIGHTNING DUST. (I knew who she was, she’s a key part of two episodes, but she’s also an asshole).
We got GRACE UNDER FIRE as part of extraction for Mine Carts, and that gave me an epiphany. GRACE UNDER FIRE was the answer to Magic Railway! All the Outer Lands had a gimmick to their puzzle structure. Creative Studios used emojis, Safari had puzzles go to several metas. Cascade has metas cascade into lower ones. This had to be the Cactus Canyon gimmick! We were going to get pairings between Cactus Canyon puzzles and other puzzles in the Hunt, and this would be relevant to the meta! All of this was wrong, but I really wanted it to be true.
As we moved to the next stuck puzzle, the people we sent to the Workshop came back with more pennies, and the news that a team had just solved Cactus Canyon’s meta.
“Wait, what? How do you know?”
Here’s what happened: as they left the Workshop, they heard the solve jingle for Cactus Canyon from the Tinkerer’s computer. Why would the Tinkerer from Left Out have solve jingles? Well, suppose a team solved a meta. Left Out would want to prepare for that team picking up their penny. What if they reused the solving jingles to let the Workshop person know what round to prepare? If that were true, then the Cactus Canyony jingle meant a team had just solved Cactus Canyon’s meta, and they were about to start endgame.
This all sounded plausible, but if it was true, there was nothing we could do about it besides solve more puzzles. (We caught up with Galactic people after, and confirmed our penny pick-up matched their Cactus Canyon solve time, so our hunch was correct.)
Remember how I said we thought answer lockouts were per-round? The 40 minute delay in solving the Creative Studios meta was weighing heavily on people’s minds, and we ended up appointing an answer guess dictator. All guesses had to go through them. This led to some tense moments - on opening Cowboy Campfire, many of us wanted to immediately backsolve with HOMECOOKED MEAL for theme reasons, but were overruled because the number of clues didn’t match answer length.
The last puzzle I worked on was Snack Bar. Most of the hard work had been done already, and we split between trying to find new flavors, checking our existing flavors, and trying different arrangements of the flavors in the grid. At one point, we had 10 different copies of the grid, with everyone making copies trying to find a good arrangement. It got complicated when two people duplicated a sheet at the same time. It turns out Google Sheets does not like this, giving you sheet names like “Conflict_of_23812739”.
One of us reported having something promising. We all moved to “Copy of Copy of Copy of Nathan’s sheet”, and solved it. The answer for Snack Bar was very surprising to the meta crew, resolved a bunch of ambiguity (still not sure how), and was the last answer they needed to solve Cactus Canyon’s meta.
Workshop
If you’re interested in the story for this, you can go read Part 1. The short version is: we got very excited, left our HQ to pick up the last penny, got stuck, got extra stuck, and retreated back to HQ as our laptop batteries started dying.
We set aside some floor space for the pennies, and had people cycling between looking at the pennies, looking at our spreadsheets, and backsolving puzzles when people got sick of doing either of those two things.

There was nothing unfair about this puzzle. It was just hard. There was a lot of data, and the phrases were tricky to find if you didn’t know what you were looking for. You needed to look at both the text and pictures to have a chance of getting the a-ha, but only our physical copy had the text and pictures co-located with each other - all our digital copies either had just the text, or just the pictures, but never both side-by-side.
We have really good solvers on teammate, for all types of puzzles, but I believe our edge is that we have a strong team-wide intuition for when we can use tools and programming to speed up solving, or to skip insights entirely through brute force. For example, although we didn’t solve High Noon Duel, our solve went like this.
- Identified the movies and characters.
- Got stuck.
- Note that there are 14 pairs of clues, so there are 14! different pairings of cowboys to get semaphore.
- That’s a bit big for brute force (87 billion), but not impossible with some heuristics, assuming the reading order was by the given order of left cowboys.
- I put together a short script to generate random pairings, and reported that about 14% of permutations gave valid semaphore, approximately 1 in 7.
- Since there are repeat directions in the black cowboys, we have much less than 14! permutations. If we combined lazy unique permutation generation with the 1 in 7 filtering, then added some English language heuristics on top, it should be brute-forceable.
Would this have worked if we coded it up? Well, no, because the cluephrase wouldn’t make sense without understanding the puzzle’s intended mechanic. I mention it because 3 people, all new to the puzzle, independently asked if we should try brute force.
As another example, we gave Number Hunting from Puzzles are Magic to a few different testsolvers. This is all very anecdotal, but many of the testsolvers from teammate had the same realization - once you solve enough to find the list of candidate answers, it’s much faster to export the list of all answers, and use coding to search for matching answer enumerations, instead of forward solving the clues. When I checked the stats for Number Hunting, I was not surprised that a teammate team got the fastest solve. That’s just how we are as a team.
The pennies were definitely not a puzzle where coding trickery or tool knowledge got you to the answer faster. You just had to solve it. We didn’t.
Edit: Correction from the team that got fastest solve on Number Hunting: they actually solved the puzzle by guessing the answer from flavor, after solving a quarter of the clues. So that solve was more about enthusiastic guessing than anything else. My bad!
Runaround
After Galactic found the coin, Left Out called us to give us hints, and we decided we’d rather jump straight to the runaround instead of solving Workshop.
I did the runaround for Cascade Bay. Our gimmick was on the easier side. We played the role of water inside a water pipe, starting in a water pipe above a sign on MIT campus. Along the way, we looped through an all-gender restroom, got lost in some walls, came out of some sprinklers, and solved the puzzle by getting our last letters from some nautical ships.
Meeting back at Left Out’s HQ for the finale, we brought back the Heart of the Park. At one climactic moment, we were supposed to chant the Workshop answer, but because we skipped past it, we ended up chanting “SPOILER FREE ANSWER PHRASE, SPOILER FREE ANSWER PHRASE”, which was delightfully goofy.
I know there are videos of the finale at wrap-up. What that video doesn’t capture is that for some reason, there are twelve projector screens in that room. It is one thing to watch the final Penny Park video. It is another to have it broadcasted to you from twelve screens covering every wall in sight.
Closing Thoughts
I really liked this year’s Mystery Hunt. The puzzle structure got stretched in neat ways, there were a lot of in-person puzzles this year (a side-effect of automatic answer checking freeing up people elsewhere?), and the production value was nuts. Seriously, they made puzzle-specific art in a consistent style for every puzzle in the Hunt? I’m not sure people realize how insane that is. It’s completely insane.
I am a bit worried by the number of puzzles. The number of puzzles in Hunt has definitely trended upwards, and I’m not convinced that’s sustainable. One lesson I remember reading about Random’s 2015 Mystery Hunt was that easy puzzles took the same amount of time to write as hard puzzles, and they were only able to do the School of Fish round because they had a ton of writers. I’m pretty sure this year’s hunt had more puzzles than 2015, and I don’t think Left Out had more writers than Random did…
In lieu of the Coin, we distributed the pressed pennies instead, as mini-Coins. I joked that “oh boy, I get to keep a reminder of the puzzle that caused us incredible pain”, but you know what, it really doesn’t hurt at all anymore, and the penny still looks nice.
As for what’s next: teammate and Galactic had an agreement that if either team won, we’d help each other write Hunt. Some of teammate is joining Galactic to write, but some are planning to solve instead. The team is reckoning with an uncomfortable chain of facts: there’s a chance we could win Hunt, and the team wants to win Hunt if we’re in position to, but we were implicitly relying on help from Galactic to write Hunt if we won. Assuming that no one wants to write MIT Mystery Hunt two years in a row, if teammate wins next year, the cavalry’s not coming from Galactic. It will be less WHOOSH Galactic Trendsetters! NYEEEOW, and more WHOOSH please let us sleep ZZZZZZZ.
The skill set to win Hunt is not the same as the skill set to write Hunt. There’s definitely heavy overlap, since experienced solvers know what good puzzles look like, but that still leaves all the time estimation, organization, theming, and tech required to make the Hunt tick. MIT Mystery Hunt exists because people keep making it happen, and if you can win Hunt, you have the responsibility of continuing to make it happen. The most direct consequence of our strong performance this year is that teammate has had serious discussions about how we can build more puzzle writing expertise.
And, that’s it for MIT Mystery Hunt 2020. Jeez, this got really, really long. For puzzlers looking for new hunts, Cryptex Hunt starts in a few days. It’s my first time doing it, so no idea what to expect, but it should be fun.