Thoughts on ICLR 2019
ICLR did terrible things for my ego. I didn’t have any papers at ICLR. I only went to check out the conference. Despite this, people I haven’t met before are telling me that they know who I am from my blog, and friends are joking that I should change my affiliation from “Google” to “Famous Blogger”.
Look, take it from me - having a famous blog post is great for name recognition, but it isn’t good for much else. Based on Google Analytics funnels, it doesn’t translate to people reading other posts, or reading any more of my research. I’ve said this before, but I blog because it’s fun and I get something out of doing it, even if no one actually reads it. I mean, of course I want people to read my blog, but I really go out of my way to not care about viewership. Sorta Insightful is never going to pay my bills, and my worry is that if I care about viewership too much, I won’t write the posts that I want to write. Instead, I’ll write the posts that I think other people want me to write. Those two aren’t the same, and caring about viewers too much seems like the first step towards a blog that’s less fun for me.
Favorite Papers
Every conference, when I’m doing small-talk with other people, I get the same question: “What papers did you like?”. And every conference I give the same answer: “I don’t remember any of them.”
I try to use conferences to get a feel for what’s hot and what’s not in machine learning, and to catch-up on subfields that I’m following. So generally, I have a hard time remembering any particular poster or presentation. Instead, my eyes glaze over at a few keywords, I type some notes that I know I’ll never read, I’ll make a note of an interesting idea, and if I’m lucky, I’ll even remember what paper it was from. In practice, I usually don’t. For what it’s worth, I think this conference strategy is totally fine.
People still like deep learning. They still like reinforcement learning. GANs and meta-learning are both still pretty healthy. I get the feeling that for GANs and meta-learning, the honeymoon period of deriving slight variants of existing algorithms has worn off - many more of the papers I saw had shifted towards figuring out places where GANs or meta-learning could be applied to other areas of research.
Image-to-image learning is getting pretty good, and this opens up a bunch of interesting problems around predictive learning and image-based models and so forth. And of course, generating cool samples is one of the ways your paper gets more press and engagement, so I expect to see more of this in the next few years.
It’s sad that I’m only half-joking about the engagement part. The nature of research is that some of it looks cool and some of it doesn’t, and the coolness factor is tied more towards your problem rather than the quality of your work. One of these days I should clean up my thoughts on the engagement vs quality gap. It’s a topic where I’ll gladly preach to the choir about it, if it means that it gets through to the person in the choir who’s only pretending they know what the choir’s talking about.
Can We Talk About Adversarial Perturbations?
Speaking of cool factor, wow there were a lot of papers about adversarial perturbations. This might be biased by the poster session where all the GAN and adversarial perturbation papers were bunched together, making it seem like more of the conference than it really was (more about this later), but let me rant for a bit.
As a refresher, the adversarial perturbation literature is based around the discovery that if you take images, and add small amounts of noise imperceptible to the human eye, then you get images that are completely misclassified.
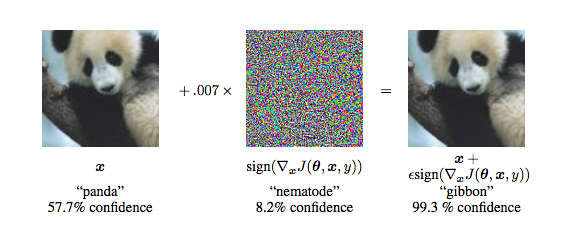
Source: (Goodfellow et al, ICLR 2015)
These results really captured people’s attention, and they caught mine too. There’s been a lot of work on learning defenses to improve robustness to these imperceptible noise attacks. I used to think this was cool, but I’m more lukewarm about it now.
Most of the reason I’m not so interested now is tied to the Adversarial Spheres paper (Gilmer et al, 2018). Now big caveat: I haven’t fully read the paper. Feel free to correct me, but here’s my high-level understanding of the result.
Suppose your data lies in some high-dimensional space. Let \(S\) be the set of points your classifier correctly classifies. The volume of this set should match the accuracy of your classifier. For example, if the classifier has \(95\%\) accuracy, then the volume of \(S\) will be \(95\%\) of the total volume of the data space.
When constructing adversarial perturbations, we add some \(\epsilon\) noise to the input point. Given some correctly classified point \(x\), we can find an adversarial example for \(x\) if the \(\epsilon\)-ball centered at \(x\) contains a point that is incorrectly classified.
To reason about the average distance to an adversarial example over the dataset, we can consider the union of the \(\epsilon\)-balls for every correctly classified \(x\). This is equivalent to the set of points within distance \(\epsilon\) of any \(x \in S\).
Let’s consider the volume of \(S\), once its expanded by \(\epsilon\) out in all directions. The larger \(\epsilon\) is, the more the volume of \(S\) will grow. If we pick an \(\epsilon\) that grows the volume of \(S\) from \(95\%\) of the space to \(100\%\) of the space, then we’re guaranteed to find an adversarial example, no matter how misclassifications are distributed in space, because every possible misclassification is within \(\epsilon\) of \(S\). The adversarial spheres paper proves bounds on the increase in volume for different \(\epsilon\), to increase the volume such that it covers the entire space, specifically for the case where you data lies on a sphere. Carrying out the math gives an \(\epsilon\) below the threshold for human-perceptible noise. This is then combined with some arguments that the sphere is the best you can do (by relating volume increase to surface area and applying the isoparametric inequality), and some loose evidence real data follows similar bounds.
Importantly, the final result depends only on test error and dimensionality of your dataset, and makes no assumptions about how robust your classifier is, or what adversarial defenses you’ve added on top. As long as you have some test error, it doesn’t matter what defenses you try to add to the classifier. The weird geometry of high-dimensional space is sufficient to provide an existence proof for adversarial perturbations. It isn’t that our classifiers aren’t robust, it’s that avoiding adversarial examples is really hard in a 100,000-dimensional space.
(High-dimensional geometry is super-weird, by the way. For example, if you sample two random vectors where each coordinate comes from \(U[0,1]\), they’ll almost always be almost-orthogonal, by the law of large numbers. A more relevant fun fact is that adding \(\epsilon\) noise to each coordinate of an \(n\)-dimensional point produces a new point that’s \(O(\epsilon \sqrt{n})\) away from your original one. If you consider the dimensionality \(n\) of image data, it should be more intuitive why small perturbations in every dimension gives you tons of flexibility towards finding misclassified points.)
The fact that adversarial examples exist doesn’t mean that it’s easy to discover them. One outcome is that adversarial defense research successfully finds a way to hide adversarial examples in a way that’s hard to discover with any efficient algorithm. But, this feels unlikely to me. I think defenses for adversarial attacks will be most useful as a form of adversarial data augmentation, rather than as useful stepping stones to other forms of ML security. I’m just not too interested in that kind of work.
A Quick Tangent on Zero-Knowledge Proofs
I don’t want this post to get hijacked by an adversarial examples train, so I’ll keep this brief.
Ian Goodfellow gave a talk at the SafeML ICLR workshop. I’d encourage listening to the full talk, I’d say I agree with most of it.
In that talk, he said that he thinks people are over-focusing on adversarial perturbations. He also proposed dynamic defenses for adversarial examples. In a dynamic defense, a classifier’s output distribution \(p(class|input)\) may change on every input processed, even if the same input is replayed multiple times. This both breaks a ton of assumptions, and gives you more flexible and expressive defense models.
This may be a completely wild connection, but on hearing this I was reminded of zero-knowledge proofs. A lot of zero-knowledge proof schemes integrate randomness into their proof protocol, in a way that lets the prover prove something is true while protecting details of their internal processing. And with some twisting of logic, it sounds like maybe there’s some way to make a classifier useful without leaking unnecessary knowledge over how it works, by changing \(p(class|input)\) in the right way each input. I feel like there might be something here, but there’s a reasonable chance it’s all junk.
Poster Arrangements
Hey, do you remember that comment I made, about how all the adversarial example and GAN papers were bunched up into one poster session? At this year’s ICLR, posters were grouped by topic. I think the theory was that you could plan which poster sessions you were attending and which ones you weren’t by checking the schedule in advance. Then, you can schedule all your networking catch-ups during the sessions you don’t want to visit.
I wing all my conferences, getting by on a loose level of planning, so that’s not how it played out for me. Instead, I would go between sessions where I didn’t care about any of the posters, and sessions where I wanted to see all the posters. This felt horribly inefficient, because I had to skip posters I knew I’d be interested in reading, due to the time crunch of trying to see everything, and then spend the next session doing nothing.
A friend of mine pointed out another flaw: the posters they most wanted to see were in the same time slot as their poster presentation. That forced a trade-off between presenting their work to other people, and seeing posters for related work in their subfield.
My feeling is that ICLR should cater to the people presenting the posters, and experience of other attendees should be secondary. Let’s quickly solve the optimization problem. Say a subfield has \(N\) posters, and there are \(k\) different poster sessions. As an approximation, every poster is presented by \(1\) person, and that person can’t see any posters in the same session they’re presenting in. We want to allocate the posters such that we maximize the average number of posters each presenter sees.
I’ll leave the formal proof as an exercise (you’ll want your Lagrange multipliers), but the solution you get is that the \(N\) posters should be divided evenly between the \(k\) poster sessions. Now, in practice, posters can overlap between subfields, and it can be hard to even define what is and isn’t a subfield. Distributing exactly evenly is a challenge, but if we assign posters randomly to each poster session, then every subfield should work out to be approximately even.
To me, it felt like the ICLR organizers spent a bunch of time clustering papers, when randomness would have been better. To quote CGP Grey, “Man, it’s always frustrating to know that to literally have done nothing would be faster than the something that is done”. I’m open to explanations why randomness would be bad though!
The Structure and Priors Debate
This year, ICLR tried out a debate during the main conference. The topic was about what should be given to machine learning models as a given structure or prior about the world, and what should be learned from data. I got the impression that the organizers wanted it to be a constructive, fiery, and passionate debate. To be blunt, it wasn’t.
I’m in a slightly unique position to comment on this, because I actually took part in the ICML 2018 Debates workshop. I’d rather people not know I did this, because I was really, really winging it, armed with a position paper I wrote in a day. I’m not even sure I agree with my position paper now. Meanwhile, the other side of the debate was represented by Katherine and Zack, who had considerably more coherent position papers. It was like walking into what I thought was a knife fight, armed with a small paring knife, and realizing it was an “anything goes” fight, where they have defensive turrets surrounding a fortified bunker.
But then the debate started, and it all turned out fine, because we spent 90% of our time agreeing about every question, and none of us had any reason to pull out particularly heavy linguistic weaponry. It stayed very civil, and the most fiery comments came from the audience, not from us.
When talking to the organizers of the ICML debates workshop after the fact, they said the mistake was assuming that if they took people with opposing views, and had them talk about the subject they disagreed on, it would naturally evolve into an interesting debate. I don’t think it works that way. To get things to play out that way, I believe you have to continually prod the participants towards the crux of their disagreements - and this crux is sometimes not very obvious. Without this constant force, it’s easy to endlessly orbit the disagreement without ever visiting it.
Below is a diagram for a similar phenomenon, where grad students want to work on a thesis right up until they actually sit down and try to do it. I feel a similar model is a good approximation for machine learning debates.
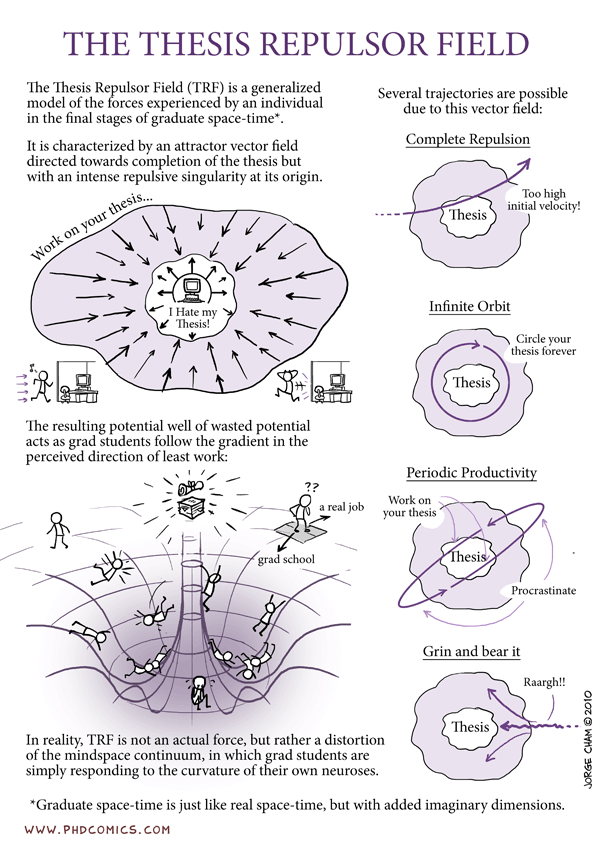
Source: PhD Comics
Look, I’m not going to mince words. Machine learning researchers tend to be introverted, tend to agree more than they disagree, and are usually quite tolerant of differing opinions over research hypotheses. And it’s really easy to unintentionally (or intentionally) steer the conversation towards the region of carefully qualified, agreeable conversation, where no one remembers it by tomorrow. This is especially true if you’re debating a nebulous term like “deep learning” or “structure” or “rigor”, where you can easily burn lots of time saying things like, “Yes, but what does deep learning mean?”, at which point every debater presents their own definition and you’ve wasted five minutes saying very little. The context of “we’re debating” pushes towards the center. The instinct of “we’re trying to be nice” pushes way, way harder away from the center.
I think ML debates are cool in theory, and I’d like to see a few more shots at making them happen, but if it does happen again, I’d advise the debate moderators to go in with the mindset that ML debates need a lot of design to end in a satisfying way, with repeated guidance towards the crux of the debaters’ disagreements.
Conclusion
ICLR was pretty good this year. New Orleans is a nice convention city - lots of hotels near the convention center, and lots of culture in walking distance. I had a good time, and as someone who’s lived in California for most of their life, I appreciated getting to experience a city in the South for a change. It was great, asides from the weather. On that front, California just wins.