Quick Opinions on Go-Explore
This was originally going to be a Tweetstorm, but then I decided it would be easier to write as a blog post. These opinions are quick, but also a lot slower than my OpenAI Five opinions, since I have more time.
Today, Uber AI Labs announced that they had solved Montezuma’s Revenge with a new algorithm called Go-Explore. Montezuma’s Revenge is the classical hard example of difficult Atari exploration problems. They also announced results on Pitfall, a more difficult Atari exploration problem. Pitfall is a less popular benchmark, and I suspect that’s because it’s so hard to get a positive score at all.
These are eye-popping headlines, but there’s controversy around the results, and I have opinions here. For future note, I’m writing this before the official paper is released, so I’m making some guesses about the exact details.
What is the Proposed Approach?
This is a summary of the official release, which you should read for yourself.
One of the common approaches to solve exploration problems is intrinsic motivation. If you provide bonus rewards for novel states, you can encourage agents to explore more of the state space, even if they don’t receive any external reward from the environment. The detail is in defining novelty and the scale of the intrinsic reward.
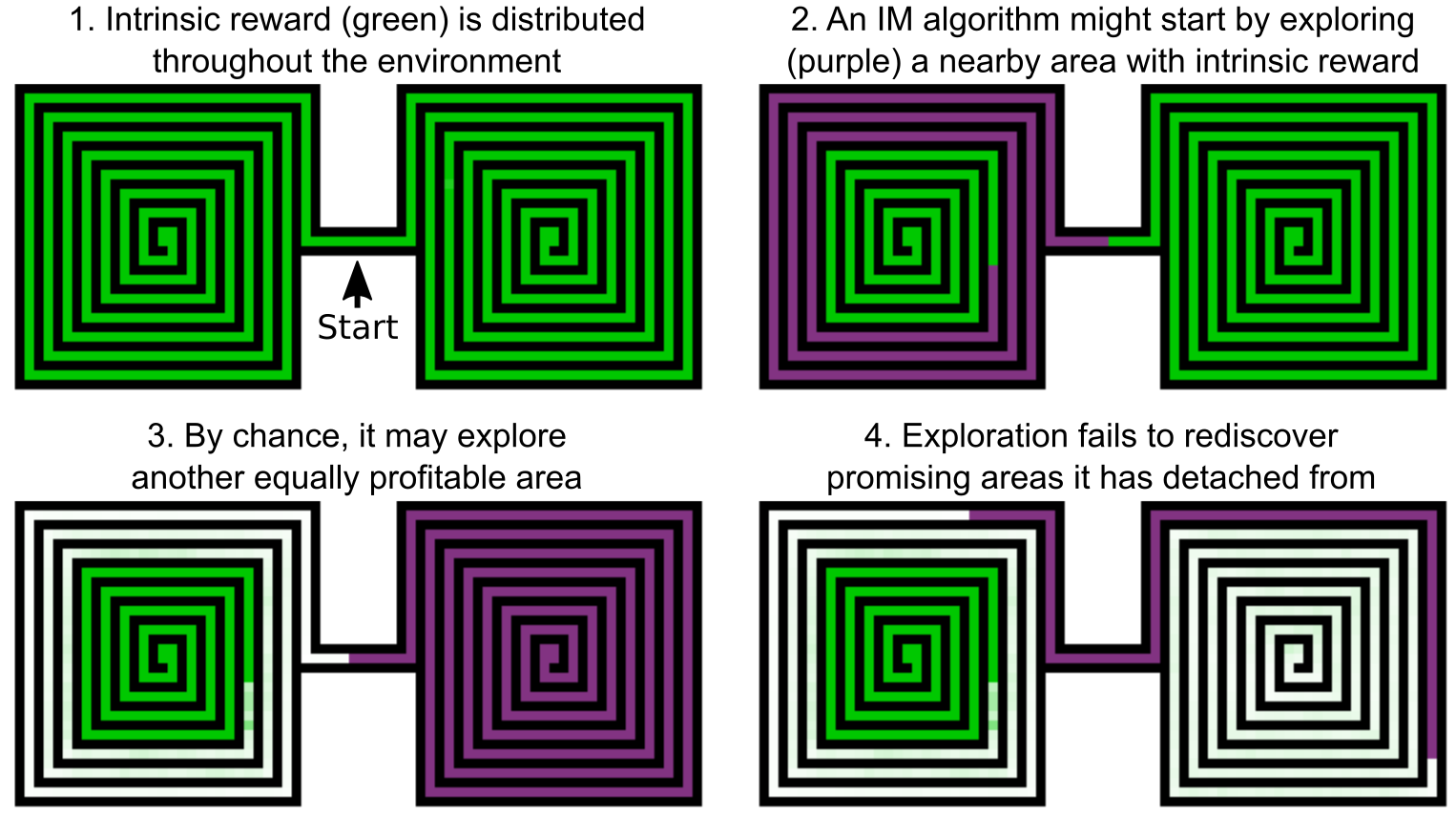
The authors theorize that one problem with these approaches is that they do a poor job at continuing to explore promising areas far away from the start state. They call this phenomenon detachment.
(Diagram from original post)
In this toy example, the agent is right between two rich sources of novelty. By chance, it only explores part of the left spiral before exploring the right spiral. This locks off half of the left spiral, because it is bottlenecked by states that are no longer novel.
The proposed solution is to maintain a memory of previously visited novel states. When learning, the agent first randomly samples a previously visited state, biased towards newer ones. It travels to that state, then explores from that state. By chance we will eventually resample a state near the boundary of visited states, and from there it is easy to discover unvisited novel states.
In principle, you could combine this paradigm with an intrinsic motivation algorithm, but the authors found it was enough to explore randomly from the previously visited state.
Finally, there is an optional robustification step. In practice, the trajectories learned from this approach can be brittle to small action deviations. To make the learned behavior more robust, we can do self-imitation learning, where we take trajectories learned in a deterministic environment, and learn to reproduce them in randomized versions of that environment.
Where is the Controversy?
I think this motivation is sound, and I like the thought experiment. The controversy lies within the details of the approach. Specifically,
- How do you represent game states within your memory, in a way that groups similar states while separating dissimilar ones?
- How do you successfully return to previously visited states?
- How is the final evaluation performed?
Point 1 is very mild. They found that simply downsampling the image to a smaller image was sufficient to get a good enough code. (8 x 11 grayscale image with 8 pixel intensities).

(Animation from original post)
Downsampling is enough to achieve 35,000 points, about three times larger than the previous state of the art, Random Network Distillation.
However, the advertised result of 2,000,000 points on Montezuma’s Revenge includes a lot of domain knowledge, like:
- The x-y position of the character.
- The current room.
- The current level.
- The number of keys held.
This is a lot of domain-specific knowledge for Montezuma’s Revenge. But like I said, this isn’t a big deal, it’s just how the results are ordered in presentation.
The more significant controversy is in points 2 and 3.
Let’s start with point 2. To return to previous states, three methods are proposed:
- Reset the environment directly to that state.
- Memorize and replay the sequence of actions that take you to that state. This requires a deterministic environment.
- Learn a goal-conditioned policy. This works in any environment, but is the least sample efficient.
The first two methods make strong assumptions about the environment, and also happen to be the only methods used in the reported results.
The other controversy is that reported numbers use just the 30 random initial actions commonly used in Atari evaluation. This adds some randomness, but the SOTA they compare against also uses sticky actions, as proposed by (Machado et al, 2017). With probability \(\epsilon\), the previous action is executed instead of the one the agent requests. This adds some randomness to the dynamics, and is intended to break approaches that rely too much on a deterministic environment.
Okay, So What’s the Big Deal?
Those are the facts. Now here are the opinions.
First, it’s weird to have a blog post released without a corresponding paper. The blog post is written like a research paper, but the nature of these press release posts is that they present the flashy results, then hide the ugly details within the paper for people who are more determined to learn about the result. Was it really necessary to announce this result without a paper to check for details?
Second, it’s bad that the SOTA they compare against uses sticky actions, and their numbers do not use sticky actions. However, this should be easy to resolve. Retrain the robustification step using a sticky actions environment, then report the new numbers.
The controversy I care about much more is the one around the training setup. As stated, the discovery of novel states heavily relies on using either a fully deterministic environment, or an environment where we can initialize to arbitrary states. The robustification step also relies on a simulator, since the imitation learning algorithm used is the “backward” algorithm from Learning Montezuma’s Revenge from a Single Demonstration, which requires resetting to arbitrary states for curriculum learning reasons.

(Diagram from original post. The agent is initialized close to the key. When the agent shows it can reach the end state frequently enough, it is initialized further back in the demonstration.)
It’s hard to overstate how big of a deal these simulator initializations are. They can matter a lot! One of the results shown by (Rajeswaran & Lowrey et al, 2018) is that for the MuJoCo benchmarks, wider state initialization give you more gains than pretty much any change between RL algorithms and model architectures. If we think of simulator initialization as a human-designed state initialization, it should be clear why this places a large asterisk on the results when compared against a state-of-the-art method that never exploits this feature.
If I was arguing for Uber. I would say that this is part of the point.
While most interesting problems are stochastic, a key insight behind Go-Explore is that we can first solve the problem, and then deal with making the solution more robust later (if necessary). In particular, in contrast with the usual view of determinism as a stumbling block to producing agents that are robust and high-performing, it can be made an ally by harnessing the fact that simulators can nearly all be made both deterministic and resettable (by saving and restoring the simulator state), and can later be made stochastic to create a more robust policy
This is a quote from the press release. Yes, Go-Explore makes many assumptions about the training setup. But look at the numbers! It does very, very well on Montezuma’s Revenge and Pitfall, and the robustification step can be applied to extend to settings where these deterministic assumptions are less true.
To this I would reply: sure, but is it right to claim you’ve solved Montezuma’s Revenge, and is robustification a plausible fix to the given limitations? Benchmarks can be a tricky subject, so let’s unpack this a bit.
In my view, benchmarks fall along a spectrum. On one end, you have Chess, Go, and self-driving cars. These are grand challenges where we declare them solved when anybody can solve them to human-level performance by any means necessary, and where few people will complain if the final solution relies on assumptions about the benchmark.
On the other end, you have the MountainCar, Pendulums, and LQRs of the world. Benchmarks where if you give even a hint about the environment, a model-based method will instantly solve it, and the fun is seeing whether your model-free RL method can solve it too.
These days, most RL benchmarks are closer to the MountainCar end of the spectrum. We deliberately keep ourselves blind to some aspects of the problem, so that we can try our RL algorithms on a wider range of future environments.
In this respect, using simulator initialization or a deterministic environment is a deal breaker for several downstream environments. The blog post says that this approach could be used for simulated robotics tasks, and then combined with sim-to-real transfer to get real-world policies. On this front, I’m fairly pessimistic on how deterministic physics simulators are, how difficult sim-to-real transfer is, and whether this gives you gains over standard control theory. The paradigm of “deterministic, then randomize” seems to assume that your deterministic solution doesn’t exploit the determinism in a way that’s impossible to reproduce in the stochastic version of the environment
A toy example here is something like an archery environment with two targets. One has a very tiny bullseye that gives +100 reward. The other has a wider bullseye that gives +50 reward. A policy in a deterministic environment will prefer the tiny bullseye. A policy in a noisy environment will prefer the wider bullseye. But this robustification paradigm could force the impossible problem of hitting a tiny bullseye when there’s massive amounts of unpredictable wind.
This is the main reason I’m less happy than the press release wants me to be. Yes, there are contributions here. Yes, for some definition of the Montezuma’s Revenge benchmark, the benchmark is solved. But the details of the solution have left me disillusioned about its applicability, and the benchmark that I wanted to see solved is different from the one that was actually solved. It makes me feel like I got clickbaited.
Is the benchmark the problem, or are my expectations the problem? I’m sure others were disappointed when Chess was beaten with carefully designed tree search algorithms, rather than “intelligence”. I’m going to claim the benchmark is the problem, because Montezuma’s Revenge should be a simple problem, and it has analogues whose solution should be a lot more interesting. I believe a solution that uses sticky actions at all points of the training process will produce qualitatively different algorithms, and a solution that combines this with no control over initial state will be worth paying attention to.
In many ways, Go-Explore reminds me of the post for Hybrid Reward Architecture paper (van Seijen et al, 2017). This post also advertised a superhuman result on Atari: achieving 1 million points on Ms. Pac-Man, compared to a human high score of 266,330 points. It also did so in a way relying on trajectory memorization. Whenever the agent completes a Pacman level, the trajectory it executed is saved, then replayed whenever it revisits that level. Due to determinism, this guarantees the RL algorithm only needs to solve each level once. As shown in their plots, the trick is the difference between 1 million points and 25,000 points.
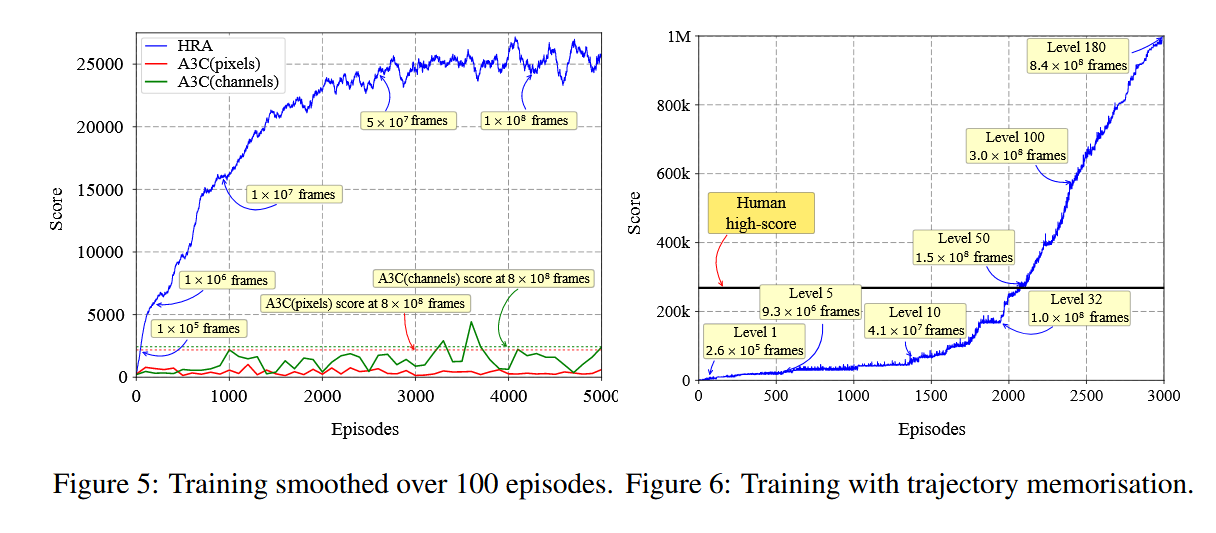
Like Go-Explore, this post had interesting ideas that I hadn’t seen before, which is everything you could want out of research. And like Go-Explore, I was sour on the results themselves, because they smelled too much like PR, like a result that was shaped by PR, warped in a way that preferred flashy numbers too much and applicability too little.