Posts
-
AI Will Not Make Your Job Chill
CommentsPeople keep talking about how AI will make their job easy, and I don’t really understand why.
In the Industrial Revolution, textiles were broadly automated. A single person’s labor could now produce much more cloth than before. It turned out people like having nice clothes, demand for shirts went up, and now I own several novelty T-shirts that I wear once a year. I assume the factory job producing this was still hard work.
Richard Gatling, inventor of the gatling gun, invented the first machine gun. According to a letter he wrote to a friend, he was motivated by reducing the size of armies.
It occurred to me that if I could invent a machine—a gun—which could by rapidity of fire, enable one man to do as much battle duty as a hundred, that it would, to a great extent, supersede the necessity of large armies, and consequently, exposure to battle and disease be greatly diminished.
In practice, the appetite for war was quite big (war being zero-sum), so armies were still big during WW1 and WW2. Soldiers in those wars did not have an easy time despite their better tech.
The thing I’m gesturing to here is that something being easier to produce doesn’t lead to people doing the same work in less time. There is instead a complicated relationship of how much new demand is unlocked, the best ways to get people to fill that new demand, and the resulting equilibrium typically still involves hard work.
With the rise of coding agents in particular, I find I have less downtime than before. It feels like if I am not sending an agent on an adventure, I’m not doing all that I could. And, this is not an unfamiliar feeling. ML work was like this too. If you aren’t running an experiment training a model overnight, what are you doing?
As coding has become more commoditized, there is a growing divide between people who liked building software, and people who liked writing code. I was one of the weirdos who liked the latter, who got into coding via algorithms and found tech interviews fun. Writing code was my downtime between conceptual work. Now this is gone, because it’s irresponsible to write code from scratch. Writing code from scratch is for free time now.
I don’t think AI has made my job chill, and I feel like I am front-line compared to much of the economy. My expectation is that although more slices of my job as a researcher will be automated, the remaining work will just expand to fill the remaining time, and there won’t be any top-level agreement that all AI researchers will agree to only work 20 hours a week. The pressures of competitive capitalism will push too hard on maximizing output.
Amazon warehouses are another good case study for this. If you had to pick a single company that speedruns capitalism, Amazon is top of the list. It’s not widely known, but transportation and warehousing has the highest rate of nonfatal work injuries in the US. Based on the Bureau of Labor Statistics, the 2024 rate was 4.4 injuries and illnesses per 100 full-time workers.
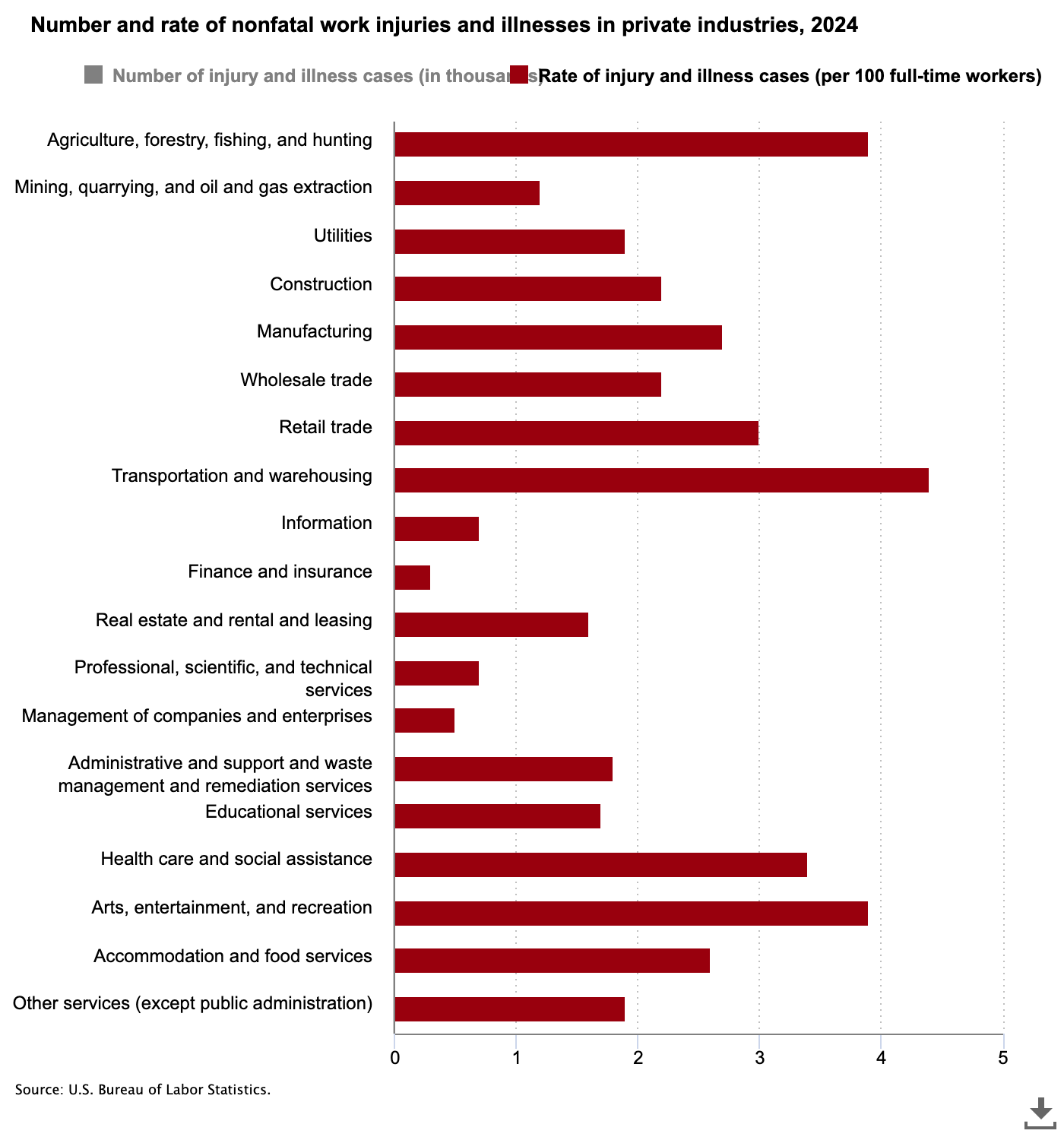
How do Amazon warehouses in particular compare? The results are not great. Based on reports from labor unions, Amazon warehouses were 7.7 injuries per 100 FTEs in 2021. For fulfillment centers, warehouses with robotic facilities see more injuries per worker, not fewer. This is attributed to two factors:
- Quotas at facilities with robots are set higher, increasing from 100 items per hour to 300-400 items per hour. This increased speed puts more pressure on workers.
- To satisfy the robot systems, workers do narrower ranges of motion more often, which increases RSI issues.
It’s hard to deny this works as a consumer. My Amazon packages arrive on time. Still, the automation sure didn’t make fulfillment center jobs be chill, safer, or more relaxing. Do LLM improvements make skilled labor more similar to fulfillment center work, or less?
Projecting the future is notoriously hard, but here is my best guess. LLMs will get better at an increasing range of skills. For a while, this will not lead to any job loss, because increasing abundance will lead to higher demand. But the nature of those jobs will become either more tiring, or more boring, or both. They will still be rewarding, or better than they were before if you’re a fan of high intensity work. It certainly won’t be chill.
And then, slowly then all at once, certain jobs will have 100% of their required skills be completable by LLMs, and those jobs won’t exist anymore.
P.S: Certain jobs disappearing doesn’t say anything about the overall labor market. It’s very possible employment stays the same as alternate kinds of jobs arise. However, I think it’s important that people typically argue that either employment will go down, or employment will stay the same. No one says employment will go up. I don’t feel informed about the question of employment, so my uninformed guess is to take the average and say it’d go down.
-
Why I Signed The Amicus Brief for Anthropic v Department of War
CommentsOn Monday, Anthropic filed a lawsuit against the Department of War, and an amicus brief in support of Anthropic was filed on behalf of a number of OpenAI and Google employees. See coverage here and the brief itself here. To emphasize, everyone who signed did so in a personal capacity. There’s also an amicus brief filed on behalf of Microsoft. That one is speaking for the company, focusing on a temporary restraining order of the supply chain risk designation.
I don’t plan to write more about this subject, but will briefly explain why I signed.
In many ways, I thought the fight between Anthropic and the government was one of the more important stories in the world. There’s conflicting reporting, but very broadly, Anthropic signed an agreement with the government to deploy Claude in classified, military contexts. There was then a falling out. According to some, this started because Anthropic asked questions about if their model was used in the Maduro raid. According to others, the conflict came from the government asking a hypothetical about automated defense missiles, and not liking Anthropic’s answers. The leaked Anthropic memo says the negotiations fell apart because Anthropic refused to delete a phrase about using AI in “analysis of bulk acquired data”, covering information obtained by third-party data brokers. Whatever the reality was, the relevant point is that the government no longer liked the deal with Anthropic, and tried to get Anthropic to agree to an updated contract with weaker red line protections. Anthropic said no, Pete Hegseth declared them a supply chain risk, and Anthropic filed a lawsuit against this.
Now, personally, I’m in favor of red lines on domestic surveillance and fully autonomous weapons. You may read the amicus brief if you’re curious why (it’s what I did before signing), but a short version is that I believe domestic surveillance is currently limited by the friction required to do a full collation of all info the US government has on a given citizen. AI tooling could heavily reduce this friction and create a trivially directable surveillance apparatus much stronger than the current one. I am personally okay with a less efficient government, when that loss of efficiency is in the name of preserving civil liberties, rather than dumb reasons like outdated software. As for fully autonomous weapons, I don’t want them to exist at all. But even if you assume they should exist (and this is a big assumption), the reliability of AI is not high enough for them. The only exception I can think of right now is situations where a missile is already in the air, and your options are to autonomously shoot it down or fail to react in time at all.
Separate from the debate you can have over how AI should be used, I also understand that the US government has the right to decide the contracts it agrees to, drop them if they no longer fit, and that usage restrictions which could hypothetically cede operational control may not be something the government wants. See Dean Ball’s thoughts on the subject here, the relevant point being:
The Department of War’s rational response here would have been to cancel Anthropic’s contract and make clear, in public, that such policy limitations are unacceptable.
Exiting the contract was fine, but the step of declaring Anthropic a supply chain risk was irrational and way too big of an overreach. It’s just an exceptionally retributive action which helps nobody. Not the military, not Anthropic, and not the people. By making this move, the Department of War claims the power to attack a US tech company’s business and force the tech industry to divest from said company, just because the government doesn’t like them. It’s incoherent and baffling for the US government to promote AI on one hand, and meddle in the free market against a US AI company on the other.
Generally, I’m not wired for political debates. I don’t relish it in the way that Twitter people do. I’m also aware this could have repercussions on either my career or the potential future paths open to me. (To be clear, I don’t expect it to affect much of either, but it was something I considered.) In general, I am a fan of building career capital and preserving optionality. But if you never spend it on things you believe in, what’s the point?
The amicus brief was broadly aligned with my thoughts on the matter, so I signed.
-
MIT Mystery Hunt 2026
CommentsThis has spoilers for MIT Mystery Hunt 2026. Spoilers are not labeled or hidden.
Mystery Hunt is a funny time of year. Your friends and family know you’re traveling to Boston in the middle of winter, and that it’s a big event of some kind, but they don’t quite understand how big it is, how much people plan for it, and how much time goes into creating it. Although Hunt ostensibly takes place over a weekend, I find it takes up mindshare for more like 2-3 weeks instead.
I tried to write this post quickly, so that I could stop thinking about Hunt and start thinking about work. Like always, this post kept growing longer, and that didn’t go to plan.
Pre-Hunt
The time running up to Hunt was more stressful than usual…very briefly, I typically hunt with teammate. This year, some people on teammate were interested in splitting off for a new team. There were different reasons for this, but enough people wanted to split to make it happen for real. I joined the split, and here we are.
The new team, christened Level 1 Spicy, was 32 people, mostly in-person. It was 32 experienced + strong solvers who were all planning to go hard for Hunt, so I thought we had a chance of finishing Hunt, but I had little expectation of actually doing so.
Those of you who watched wrap-up know that we did, which surprised me as much as anyone. This wasn’t the hardest Mystery Hunt I’ve ever done, but it was pretty chonky (like Big Garff). When Cardinality visited our HQ Saturday afternoon to tell us we had a shot at finishing, I did not believe them. We persevered and made it thanks to aggressive endgame hints (more on that later).
Why is the Team Named Level 1 Spicy?
Uhhhhhhhhhhhhhh
People split off from teammate before deciding on a team name. Initially, we had a team name proposing process, run with approval voting, followed by a final poll among top entries. This completely failed to generate consensus. The entries with most support also had a few very strong haters, which was bad for a team name that was supposed to unify the team. Team name got punted to a TBD, and then little progress happened for 6 weeks.
In the name of pushing something through, I self-appointed myself as voting commissioner. This, in practice, is how I’ve ended up in most leadership positions I’ve held, by running unopposed when no one else wants to do the paperwork.
No one should have let me do this, because it eventually led to me running a pretty overcooked 3 stage voting process. The first stage was identical to what we tried the first time (approval voting on open submission), except with the addition of unilateral vetos. If any 1 person was willing to face the crowd and say “no, the team name you like cannot go forward”, then that name would be totally disqualified.

This was followed by an instant runoff vote among the top 5 entries, which selected Level X Spicy by literally 1 vote. The last stage was to decide what X was, and X = 1 won by a heavy margin.
I wrote a two page document analyzing why the properties of this voting system were better than the alternatives, and no, none of you get to read it.
In my doc resolving the instant-runoff, I had to flip a coin to choose who would be eliminated between the last and second-last candidates, as both had a completely identical number of votes for 1st, 2nd, 3rd, 4th, and 5th. This coin flip had absolutely no bearing on the winner of the election, it only decided who was last place, but I was still briefly accused of impropriety, despite including timestamp logs and a link where you could request an audit from the online service I used to flip the coin. Am I going to have to pull out the secure computation and verifiable randomness protocols I learned in my theoretical cryptography class? I will do this if I have to, don’t test me. I literally wrote a post about them 10 years ago. We can drown in commitment schemes together.
I procrastinated booking my flights into Boston, such that it was cheaper to fly in earlier and stay an extra night. I spent the days before Hunt doing two very important things. The first was to eat sushi. You see, there’s this restaurant chain called Kura Revolving Sushi, which does conveyor belt sushi. They do collabs to give away items, and the on-going one is…

The Wednesday before Hunt, they started giving away Kirby blankets (1 per $85 spent, up to 3 per party). So that day, a few people from original teammate and I did a run to Kura Sushi in Watertown. Every group there was talking about the Kirby blankets, so I’m glad I went Day 1 rather than trying to go after Hunt. This is how they get you, with monetized cuteness.

The group across from us had brought a Rainbow Dash plushie to sushi. I considered complimenting them, but unfortunately I am not socially brave enough to walk up to strangers in a restaurant. Alas, so it goes. We stuffed ourselves with the exact number of plates needed to get 3 blankets, and left with our rewards.

After dinner, I was pinged about Mystery Hunt Bingo this year. I didn’t see any reason not to do Bingo, so I pushed some edits to the phrase list to swap D&M entries for Cardinality entries. Along the way, I noticed someone had filed a pull request to add “Puzzle about 6 7” to the phrase list. I, a man of the people, obviously accepted this PR.
Having decided on a team name of Level 1 Spicy, it was also clearly on brand to visit Level99, which we did on Thursday, and meet Level 51 IRL, which we did Thursday evening. Gotta hit the entire range. I’m glad we finished some of the new rooms at Level99, even if I am now 0 for 15 at getting a clear of Magician’s Assistant.
I also did one of the Boxaroo live events. Definitely fun, even if we rushed through it pretty fast. For dinner, we went to Yume Wo Katare, where the cook was offering a Carolina Reaper challenge. Finish one Carolina Reaper over the course of dinner, and your next 5 bowls of ramen would be free. We did not take this challenge, but one guest did. Little did we know this would not be our last encounter with hot peppers this weekend.
Friday
I started my Friday by getting breakfast at Verveine. This was breakfast at 8am, so it was long before any crowds came in. On the walk to MIT, Ivan asked me if I had a spare server to host a meme. I did not, but he eventually found one to deploy levelxspicy.cooking. This site was connected to a Discord bot in our server, where anyone could
/cookor/uncookto toggle if we were cooking🧑🍳🌶️ or cooked🔥. We used it a lot, a worthwhile use of $30 to register the domain.We got to 10-250 early to make sure we got seats, but someone from Cardinality said a seminar (?) was going on, and we wouldn’t be allowed in until close to Hunt start. Only as I write this do I realize that maybe this was just an in-universe justification for Cardinality to prepare the room. I did do the pre-Hunt, but it was so long ago I’d completely forgotten the theme.
I had high hopes for Cardinality’s Mystery Hunt, because I know I’m in the same generation of Internet culture, and I was not disappointed by PuzzMon. Our room was pretty close to kick-off, so we had plenty of time to browse the site and try to solve the badges puzzle. It was interesting to hunt on a team that fit in a single classroom, rather than splitting people across two rooms like teammate normally needs to. It made coordination a bit easier, but the most notable change was that you always got to hear every solve that was going on.
Several of us were curious what Cardinality meant by team coordination over limited resources being important (the leading team meme was that we’d be playing Farmville). This was revealed to be the Research Points (RP) and choose-your-own-unlock systems. Small scavenger hunt style tasks would give RP, which could be spent to unlock puzzles or rounds. In the early round (the Kingdom), RP was the only way to unlock puzzles, with a hard cap on the number of open puzzles at once. Later, we would unlock Dimensions rounds, which had more typical Hunt unlocks where new puzzles were driven by round progression.
The RP system was pretty complex, but I think all the pieces worked. I liked the way it distributed scavenger hunt tasks over the entire weekend, rather than one big concentrated chore. The way it was phrased made it feel like we needed to be really aggressive on earning RP, and we didn’t realize how generous the RP was until Friday evening, when we saw we had way more RP than we’d need given how much we were unlocking. Still, it’s better for teams to be too rich rather than too poor.
I could see the RP system being especially good at giving newer solvers a thing to do if they were intimidated by the puzzles, but for our team in particular, it was very hard to justify sending a marginal person off on a long Research Task, so we gradually shifted to only doing the tasks that seemed super fast and ignored the rest. I think this is the same as how we’d approach a typical scavenger hunt, where you aren’t going to do every entry in the list, but it felt different when the tasks were unlocked in stages rather than appearing all at once - the later tasks were just less likely to get done at all.
Speaking of Research Tasks, there was also MonQuest, an interactive overworld where you could find PuzzMon and solve small puzzles for RP. I tried doing this for a bit, before realizing I was only discovering things that had already been discovered. I ended up doing zero MonQuest after the opening round. Though, I did work on…
Feather Forecast: A puzzle that worked the way we thought it would, although I submitted RETURN first despite that being impossible from the givens. In my defense, I had Pokemon on my mind, and was thinking of Return the attacking move.
Mountain Cave: I found where this was, transcribed the data, and then must have messed up something because it didn’t work for me. Got solved by others later.
Jumping to Conclusions: The first puzzle I did this Hunt, and one of the few I did in Kingdom, before getting sucked into Dimensions puzzles. This was a bunch of fun. I’m a big fan of trying to cheese puzzles, and I think the “intended” solve path of each is signposted well enough if you’ve done enough puzzles from past hunts. Probably not friendly for newer solvers but Hunt is big enough for that to be okay. I wrote a script to bash Skyscrapers, then worked on a script to bash the final extraction. Scanning the output, I saw OMI???D as an option, and suggested a thematic answer that could be correct. I explained that I wasn’t sure we should submit it, given this letter pattern was one of hundreds of possibilities from 4/7 known feeders, and then someone else decided to submit anyways and solved.
Somebody: Our solve of this was pretty smooth once we found the right site to look up historical playlists. Got most of the songs, figured out the a-ha via searching a bunch at once, then finally realized why somebody told us these things.
Bringing Up Baby Shark (Capstone): To be honest, I did not notice the descriptions were labeled “Herring description” rather than “Red herring description”. The text was just clearly puzzly enough for it to override my “is this a red herring” detectors.
The way capstones in this round worked was that every puzzle solve unlocked information about PuzzMon in your PokeDex (sorry, MonArch), and each capstone could be solved independent of puzzle answers. All answers in Kingdom then went into one big meta matching pool at the end. I thought the capstones were pretty clever. By not depending on feeder contents, it allowed Cardinality to order all Kingdom puzzles arbitrarily by difficulty, while still providing milestones for partial progress before you hit the critical threshold needed for meta matching. I’m curious if smaller teams felt accomplishment from capstones, or if they really needed metas using feeders to get that accomplishment.
I do think capstones felt lesser in a way that had repercussions later. As we unlocked Dimensions and Artifacts, we worked on capstones less. We understood they needed to be solved, and noted rounds tended to open based on capstones, but didn’t fully understand the level of importance they had on unlock structure.
Solving Baby Shark unlocked Land of No Name. The Land of No Name was a gimmicked round of 26 puzzles. Each puzzle started with all letters redacted, and solving a puzzle would un-redact a specific letter across the entire round. After you solved 2-3 of them, you could be confident about what letter each puzzle would unlock, which turned the solve process into one big prioritization game of deciding when you had enough info to solve a puzzle, and which puzzles would be ideal to solve earlier.
This round was super cool, especially in what kind of puzzles could be included by allowing redaction to play most of the role in difficulty.
🍓🏔️🎮: I have 160 hours of play time across Celeste and Strawberry Jam. Of course I was doing the Celeste puzzle. No idea how accessible it was for people who didn’t play Celeste, but I appreciated getting rewarded for knowing deep Celeste lore. I was especially proud of casually breaking in on the 👩🏻🦰💀 section, although I was more impressed with teammates that broke in on the meaning of #1👣[3] and why #9§⊃(🚦■’🌈=💙🌈) needed to be clarified.
This was our second Land of No Name solve (our solve order was ZMJQAOFNIXUHYSCKWDVRBTELPGmeta), and funnily enough the Z solve was actually useful to our M solve. By giving us �-Z↑, we were able to guess A-Z↑ and realize that section’s header was cluing alpha order. It’s not every day where getting Z is helpful.
🍳 Emoji Kitchen: After finishing Celeste, our group rotated to other puzzles in the round, to see what was tractable. Emoji Kitchen had 3/5 nonograms done, so we started looking at extraction while the last 2 nonograms were finished. We didn’t really know what to do with the base emojis, but eventually went with the time-honored strategy of “just color everything relevant in the sheet and trust it’ll work out”. And it did! Always nice when that happens. I’m certainly glad we didn’t need to decompose the entire grid.
Nine Lives (Capstone): I am still upset I didn’t get the Aladdin character, but not as upset as the people who figured out who the rest of the “blue people” were.
Game, ???, Match: The people working on this had IDed most games, and made an open call for people good at SET. I’d say I’m around 70th percentile within the team on that, so I helped find a few, enough to get the cluephrase. Seeing the conditions of “trains, uses dice, 8 letters”, I said “Monopoly?” This was shot down for not being sufficiently about trains, but the Monopoly believers pointed out the answer it would suggest. It wasn’t like we had another game in mind anyways, so we submitted it and it was right.
Almost: I broke in on THE QUICK BROWN … off the enum + the 3 letters we had, and then it was a struggle to the finish, where we’d come back every letter solve to try to squeeze out another clue. I liked that the pangrams were based on real searchable pangrams, but slightly altered to still require some reasoning about letters. No idea what possessed someone to write a Genshin clue though. Everything I know about Genshin has been learned against my will.
Continuing the theme of the previous puzzle, I solved the second clue to B, and it got shot down because they didn’t want the cluephrase to start UBE*. I didn’t disagree, but was really confident B was the only good extract. We resolved it by splitting into “find a way to continue UBE*” vs “find a better answer to the 2nd clue”. I won >:)
Stray Child: This was a starting puzzle in the Hyperbolic Space round, and it completely wrecked us. Over Hunt, we noticed the general unlock format was to start each Dimensions round with difficult puzzles, and ease up on difficulty as you progressed. I think there are merits to this. Dimensions round unlocks cause your team’s puzzle width to increase, and starting with harder puzzles can help temper this. Putting the hard puzzles at the end means they mostly get skipped. If you want the Hunt winner to be decided by how teams perform on the hardest content, and want to avoid difficult metas, then it’s fine to frontload hard feeders and force teams to engage with them.
I’d say this difficulty ordering was a reasonable choice, but the effect on our team was to get stuck on all starting Hyperbolic puzzles and become deathly afraid of what this meant for future Dimensions rounds. Between Land of No Name and Hyperbolic Space, we started running the Kingdom with only 5-6 PuzzMon unlocked, because we just did not have the manpower to run Kingdom at 8 PuzzMon if we wanted to progress on Dimensions.
Back to Stray Child. I clocked the puzzle as being about
weebJapanese culture pretty quickly, and worked on the initial grid fill with others. We never resolved the weird, puzzly parts of the grid fill, and backsolved it in the end. I think we were circling the correct idea for a long time, but didn’t push it enough to make it work.Pursuit of Liberty: I proposed a puzzle that would have worked exactly like this one in 2023. Same extraction and everything. I didn’t go forward with it because I don’t actually play Go, I just know the rules, which isn’t great for constructing a satisfying puzzle. During Hunt I looked at this briefly, then failed to solve a Go problem, then left until it got backsolved. Really, it’s for the best that I didn’t write this puzzle.
Nominative Determinism: I didn’t solve this during Hunt, I just think everyone should try it. We postsolved it with a council of four and it was magical to get a perfect score on our first try.
Odd One Out: I can only describe this puzzle as a complete shitpost in the best way, and am proud to announce I found 1/3 of the extract letters.
Imaginary Factorizations: We did the first step of the puzzle, got completely hardstuck on noticing the \(\lfloor b/100 \rfloor\) step, and eventually backsolved the puzzle.
Before Hunt, there was some speculation about how much people would try using AI to solve the puzzles. We used LLMs a bit, mostly as another thing to try after dumping everything into Google. If you know what you’re doing, verify you aren’t getting hallucinated, and focus on things LLMs are good at, they are helpful. I don’t think they had a major impact on our solve time, but the impact was definitely non-zero.
On Manifold, people tried a few text-only puzzles after the fact, and GPT 5.2 Pro managed to zero-shot both this puzzle (https://chatgpt.com/share/696aebb1-2a48-8000-a2e0-3575d9998bc8) and Six Shifts given 5 letters (https://chatgpt.com/share/696afc2f-d1f4-8000-b520-3e2195ea032c). Sure, it took 41 minutes and 16 minutes respectively, and they were asked on questions close to math and coding, and it probably cost $20 in API credits, but it worked and could have given us a forward solve we missed.
I personally would prefer LLMs be banned from puzzlehunts, and don’t reach for them unless I’m not having fun, but so far this hasn’t really mattered because they weren’t helpful enough. I’ll just say the landscape is starting to shift and leave it at that.
Puzzmon: The Card Game (Capstone): Our team has a few card game sickos and I am one of them. Viewing it just as a game, all of us agreed the rules looked super snowbally. We did not try playing the game for real, but our read is that the winner is really advantaged the next round, since you get to keep your PuzzMons and Stat-Ups, while your opponent has to lose one. Maybe in practice, the effects of individual cards are swingy enough to overcome the snowball, and it is a game of deciding when to deploy your haymakers and when to sandbag, but we did not try playing it enough to feel out the metagame.
As a puzzle, I primarily did quote look-up, then rule look-up. We got around 75% of the way through without knowing how to extract, which made it hard to decide what to record each round. After about an hour, I finally noticed first letters, and this caused the card game players to ragequit the puzzle. This was around Friday night, and the capstone wasn’t picked up again until Saturday morning. In retrospect, I should have pushed harder for just doing the extraction, but I was getting baited by new puzzle unlocks.
Triple Threat: Earlier, I had identified some of the horse Triple Crowns from 3-4 letters (I know that dataset way too well). By the time we came back from the card game, we had enough letters to get all the baseball Triple Crowns. As intended, I noticed the hyphen could be a minus sign, added a column for the extract, and read out “INKIGAYO”. This near-instantly triggered a lecture from the K-pop fans on our team on what Inkigayo was. I was so thankful the Wikipedia entries for this show were so organized, and we finished the puzzle pretty quickly, with one last request for the K-pop fans to read our extraction.
Said fans pointed out that this was the 3rd Mystery Hunt puzzle about K-pop which extracted by drawing Hangul to clue a word related to rain, after Fountain from MITMH 2023 and Fountain Show from MITMH 2020. Keep an eye out for 2029, K-pop fans.
Mass Confusion: Opened the puzzle, identified MEYER, added MAYOR to the sheet before we’d broken in on the a-ha, left without understanding the puzzle, but all my contributions were still in the sheet at time of solve. I’m helping!
We came up to the Saturday 1 AM boundary, and went back to hotels and AirBnBs. This year, most of Level 1 Spicy was at the Marriott rather than Le Meridien, but a few people were around to gather in my hotel room, as I planned to stay up for at least another hour. Or two, or three…
Skilldrasil: I had solo-started this puzzle before leaving campus, identifying 6/8 skills and believing the puzzle was basically solved. I then got completely stuck, roped someone else into checking my data, and got them completely stuck too. I’m not sure why I didn’t search all the colored skills together, or put them all into a cleaner list to read first letters, or search the puzzle title once we’d parsed what it would be. Any of those would have worked. Fresh eyes solved it on Saturday afternoon.
Word Compression: The overnight guidance from our Hunt ops team was to either work on Hyperbolic Space puzzles, or spend unlocks in Eland Islands, our newest Kingdom region. People tried to get me to solve Multidimensional Crossword, given that I’d written 5D Barred Diagramless, but I was like, “that’s bait at 1 AM, I need a win after failing to do Skilldrasil, I’m doing Kingdom puzzles”. I unlocked Word Compression and pair-solved it in 12 minutes. Not much to say, puzzle just worked.
The Quaking Earth: We next opened The Quaking Earth, which looked like a standard Mangled Clues puzzle. Some people from the Marriott joined our VC, saying they were here to turn our 1 hour solve into a 15 minute solve. Our combined group then took over 1 hour to finish.
After solving Quaking Earth, I planned to sleep, so I kicked people out of my room to go to bed. The clock read 4 AM.
okay the ansewr [sic] is stop and I just guessed it - jerry
wut
insane
AHAHAHAHAA
god tier
I just wanted to stop and I guess it worked…
loading puzzle all over again
Saturday
Waking up at 9 AM, I groggily looked at Hidden Numbers, which really did not need my help, but I did one token Google search for the final extract. Having solved this, I got ready to head back to campus.
Devilish Devilries: This was the perfect puzzle to solve just after waking up, because it involved shouting sus phrases across the room and getting people to wonder just what kind of puzzle we were working on. The innocent person who asked what some of the phrases meant will be kept anonymous for their protection.
MIT Dropquotes: We were close to the end of the Alphabet round, and focusing on unlocking the meta. By this point of the round, we’d solved enough puzzles to make the unknown letters pretty constrained, and solvable in the standard way you use nutrimatic on dropquotes. Well, assuming no user error…
why did I just type my nutrimatic query into WolframAlpha
The Alphabet (meta), part 1: The Dropquotes solve gave us enough letters to look at the meta, which immediately looked programming-y. The usual suspects took a look. Parsing the flavor text as “Rewrite L-system to depth five”, our theory was that we would need to take the string LSYSTEM, and rewrite it with our letter -> word mapping. There were 26 given numbers, and we theorized they were a checksum on the indices where letters A to Z existed in the expanded version of LSYSTEM, to give a way to solve the puzzle from partial info. Given how many letters we were missing, and the way they recursed on themselves, we all concluded we needed to solve more feeders to make the meta tractable, and decamped for that.
Da’ Bomb: 🌶️ PEPPER ALERT 🌶️ PEPPER ALERT 🌶️ PEPPER ALERT 🌶️ It was mandatory for our team to work on this puzzle. Cardinality was aware of the levelxspicy.cooking website, so they requested we increase our cooking level to 10 while solving the puzzle. I did ID of the guests being interviewed and words bleeped out. Our first instinct was the ID the hot sauce used in the part of the episode the clip was from. This wasn’t super defined for some clips that came from the introduction, but we rounded it to using the first hot sauce.
We had the right idea of “identify the ingredients in each hot sauce”, but the first group failed to realize we should actually, uh, ID the hot sauces Cardinality gave us. Oops. Once we fixed this, I tried the chili oil (“yep, that’s chili oil”), then the one labeled 10 (“yep, I can’t tell what I’m tasting besides heat”).
I realized that I was no help on actually solving the puzzle, and was just tasting hot sauce for the fun of it, so I left for something else. I never ended up tasting Da’ Bomb and regret it (we threw out the samples overnight after finishing the puzzle).
There are scientific studies showing that people would rather electrically shock themselves than sit in a room doing nothing. This is the puzzle made for those people.
Atlas of Mosaics: This round was so hype and also so insane tech-wise. I don’t want to think about how long it took to set this up. This unlocked while we were stuck on Alphabet meta, and as much as I tried to keep thinking about alphabets, I decided it’d be better to take a break on a collaborative crossword instead, Crossing the Unknown.
Within Crossing the Unknown, I worked on the first Orientation grid, then Valuation, Interpretation, and Integration. Still can’t believe that clue solved to HIGH CARDINALITY. Within Interpretation, I was pretty happy with figuring out the 🤖🚕 and 🪶🖊️ parts of the grid. This was a nice, casual introduction to the rest of the round.
After Crossing was done, I did the starting jigsaws for Case of the Superhero Dinner Party and the initial placement of Pokemon tiles in Inconsequential Chase, before moving back to Alphabet. I regret spoiling myself on Dinner Party, it looks fun to forward solve.
The Alphabet (meta), part 2: We now had 24/26 letters, thanks to a solve of SPLIT!. I had brought a copy of Bananagrams to Hunt in case we ended up playing board games. We didn’t but I’m glad it came in clutch. Noticing the first and last letter constraints, Brian wrote some Sheets formula magic to derive backsolve constraints for our missing feeders, based on our indexing checksum idea. The rest of us were working on implementing the expansion and turtle movements in code.
Brian successfully got a backsolve out of his sheets constraints, and at this point I should clarify that our idea for how the given numbers worked was completely fake. The numbers were not indices in one long string, they were lengths of single letters when expanded out. So somehow, we just got super lucky on the constraints the sheet was giving. The fake backsolve got us to 25/26 letters, at which point we broke in on the real meaning of the numbers, and I wrote a script to do a bruteforce dictionary search and backsolved our last feeder.
Each number now mapped to a specific letter. If we treated the first number as originally corresponding to A, and the last number as corresponding to Z, the lengths we’d IDed gave a substitution cipher we could apply. Or alternatively, we could treat it as a cycle. The given letter order started WFETUR, and if you follow the chain of edges formed by A->W, B->F, C->E, …, it forms one big cycle rather than multiple small ones. Given a random permutation, this was a 1/26 = 3.8% probability, which made it seem important. Our broad suspicion was that we would build one long series of instructions, and extract based on when the turtle visited regions indicated by the letters on the grid.
Neither of those was how the puzzle worked either. We continued brainstorming along those lines, didn’t get anywhere, and decided to work on other things and come back later.
Fate’s Thread Casino: I don’t play gacha games. However, I have played my share of games that use gacha tactics of daily quests, random drops with pity systems, etc. Maybe this makes me a gacha player in spirit, but I would argue that I’m not a gacha player by choice. Rather, the effectiveness of gacha mechanics has creeped into video game design as a whole and imposed its will on me. Although we can carve out our own pockets of sanity, at some time we must all weather the storm and become gacha players.
Sorry, what was I talking about? Right, puzzles. The structure of the unlocks was pretty cool - all puzzles had unlocks from one shared pool of chips. Chips could be spent to pull individual clues for the banner of your choice, which would help you solve Quests, which would give you more chips. It was possible to pull clues you’ve already seen, which added randomness in deciding what to pull.
Although we (correctly) suspected the unlocks were fully rigged, this did not stop us from coping about which banners to pull to open up quests. At one point, the people working on Charts had their quest pulls siphoned to Characters, and demanded getting paid back with interest. All very funny. The puzzles in this round were all really big (30+ clues for each one), but since the clues were drip-fed one at a time, it made it feel more manageable than one big puzzle page would be. The pull system also created incentive to solve puzzles from partial info if possible, as it got increasingly hard to get the last few clues for each one.
My introduction to the round was solving cryptics for As the Fly Crows. I contributed to the gimmick a-ha, although we incorrectly assumed the cryptics for the other puzzle were fully ungimmicked. I don’t consider myself the biggest cryptic fan, so I left the bulk of those puzzles for others.
Atlas of Mosaics, part 2: Looking back at the Atlas, I saw that Inconsequential Chase had gotten stuck on Years. Every tile was placed, but the grid wasn’t solving, so an unknown region of the 45 hexagons were in the wrong spot. People understandably did not want to fact check this, and were trying to solve around it by solving every other grid instead. I briefly tried to factcheck Years, then gave up to look at The Tortured Programmers Department instead.
All the programming people had abandoned Alphabet, so we were free to take a look at this puzzle. We quickly clocked it as some variant of Befunge that worked on hex grids. I found the documentation for Hexagony, and then played the moral support side of pair programming, saying “that looks good” or “that looks bad” to those actually working on the control flow. I appreciated that you could really handwave (vibe-hex?) your way to the exact program, by placing the high-level mirrors and then shuffling the last few pieces until it solved.
Cardinality came to visit our HQ shortly after we’d solved MEAN and MIRRORBALL. This was Saturday evening, and they said we were potentially on track to finish and could give hints on majorly stuck puzzles to help us get there.
The Alphabet (meta), part 3: We gave Cardinality our information so far, and they said all the substitution cipher and cycle stuff should be ignored. Instead, we should treat it as just an ordering of the letter. They told us to look at the turtle path and grid at once, and this got us to finish the meta.
I talked about it with people after the Hunt, and I think the main issue is a big lack of checks after you get the original letter ordering. On top of the cycle things we were stuck on, we had ambiguities on:
- Whether to follow the WFETUR… directions one after the other, or reset after each letter.
- Multiple ideas based on extracting when the turtle wandered in the region each letter labeled, rather than the intended mechanic.
- In our long string, whether to convert single letters to directions or replace entire words to directions (effectively off-by-one on how to convert the depth 5 string).
- Similarly, whether to treat a word like FIREBRAND as one FD, or nine FD (length of the answer), or seven FD (length of the gap between F and D).
I don’t think all of those ideas were justified, but they were plausible enough for us to try implementing. The compounding nature of the 50-50 interpretations made it hard to conclude given solve paths wouldn’t work. We had independently tried visualizing the turtle paths without the grid, and checked if the translation offsets of single letters matched offsets between letters in the grid, but never combined the two until hinted that way.
I actually think both Land of No Name and Hyperbolic Space would have been fine to have a token meta, or not have a meta at all. Just mark themselves as complete when you got all their answers. But Mystery Hunters aren’t ready for that conversation.
Atlas of Mosaics, part 3: We finished up the rest of Tortured Programmer’s Department without too much issue, with me doing the shell just in time to plug into the programming output that’d been done in parallel. We finished a bit before the Sunday 1 AM boundary kicking us out of our room.
This time there’d be no late night solving party from my hotel, which I was secretly thankful for. I was aiming to sleep earlier that night, after a bit more Casino grinding.
Charts: In theory, I like Charts. In practice, we made some progress but didn’t get to the finish due to how many images there were, and the minimal footholds on searching images if you did not catch the reference. This is a kind of fake criticism though - the point of the puzzle is how abstractly it clues its ideas, and you can’t really design around it.
I was pretty happy at breaking in on the nested stories and alternate timeline formats. As for US presidents, I have to admit an LLM helped me. I tried to search the answer to Quest 14, failed to get anywhere, and tried tossing it into Gemini 3 out of exasperation.
To my surprise, Gemini figured it out and that let us break in on two other quests. I identified a few more graphs, then idly poked at our Casino answers so far and noticed the interleaving property that was used in the meta. I shared it in the chat in hopes it would enable backsolves, but my understanding is that it only helped a bit to know this before meta unlock.
While I was bumbling around Atlas and the Casino, the rest of the team had finished all the Kingdom capstones, unlocking Connect the Clans at 2 AM. That would be a tomorrow morning problem.
Sunday
When I woke up, the coin hadn’t been found yet. This was concerning for us: based on our estimation of team strength, if the first place team hadn’t finished yet, it’d be hard for us to finish.
I was recruited to take a look at Meme Scenes, which had the most ID work and was stuck on extraction. My first instinct for how to solve the puzzle was identical to what was in our sheet, with the small problem of not actually working. Without other ideas, we sent in a hint. The hint told us we had the right idea and just needed to fix our data.
Our guess was that we’d open the Casino meta at 7/10 solves, so with 6 solves , we needed to pick between meme art, cultured art, or graphs. Both Meme Scenes and Common Scenes had all the a-has and needed grinding, while Graphs was making more progress but had an unknown number of a-has ahead. Based on that, and assurance from Common Scenes that they’d finish it soon, we abandoned the rest to focus on other parts of Hunt progression.
That ended up being Atlas for me, and Connect the Clans for others. There was some Penny Park related trauma to Connect the Clans…in 2020, teammate infamously got stuck on the Penny Park pennies for 6 hours, and the tokens just looked too much like the pennies. We broke in on the mechanics, and did everything correct, except for rotating the tokens such that the arrow pointed to the next seat rather than pointing due north. So that puzzle also got stuck, until we got rescued by a hint.
Overnight, Hunt ops speculated that there were only 4 Dimensions rounds, and the missing Keepers could be explained by endgame capstones, and the bottom part of the round art would just not be filled out. I still think this argument was cope, compared to the simpler one of having 2 more rounds to finish.
In defense of Hunt ops, it wasn’t clear to us that Connect the Clans in Kingdom could be acting as an unlock bottleneck on Dimensions. There is a difference between noting that Dimensions often unlocked after capstones were solved, and fully believing in this enough to roll out the implications on Hunt strategy while all sorts of other puzzles are flying. This does seem to be a common theme in comments I’ve been reading: parts of unlock logic were signposted, but unlocks as a whole were a bit opaque, due to the complexity of the systems.
Terminus: My experience with this round was incredibly bizarre. I opened the round, tried exploring different universes, and immediately understood it would be top priority to understand the Terminus black box to do later parts of the round. So, a small crew including me worked solely on exploring the black box, while the minipuzzles were unlocked and solved under us. Poking the universe box was a full-time job, so I went from round start to Terminus metameta unlock knowing almost nothing about the rest of the round. We were just telling people to go work on metas we’d opened and moving to the next unlock.
We broke in on Layers unlocks first, with a clutch a-ha of “what if it’s this poem” very early on. (I tried to one-shot it with I HAVE EATEN THE PLUMS IN THE ICEBOX, which got me some strange looks.) The travel log was very helpful, with a lot of features that matched what we needed at different stages of solving. In case it wasn’t clear, I found the tech UX impressive throughout the Hunt.
The first “full star” we opened was Dichotomies, followed by Crossword (this was shortly after understanding what conversion meant, with those two being the easiest ones to directly query). As for Layers, we needed a hint. I do have a complaint there. We understood the logic that single puzzles were unlocked based on the number of matching words, but weren’t sure how to turn that into a meta unlock. Three people independently tried the intended solution, found it didn’t work, and moved on. When the hint told us to try again, we persevered enough to learn we’d all failed to strip punctuation as expected. My attempt would have worked if I’d noticed THERE’S had been changed to THERE S in my code instead of THERES. And like…man. I think the intended solution is already not a great fit for the mechanic, given that it’s technically a special case of the 6+ category. Fair’s fair, three of us tried it, so it was definitely fine. The checking just needed to be more lenient. I have a similar but lesser complaint on RGBA inputs being disjoint from Dichotomies and Crossword, rather than overlapping. I’d tried both 000000 and FFFFFF and stopped trying more based on the conversion messages.
While we were puzzling over Psychology options, Providence found the Coin, and we unlocked our last Dimensions round, The Glitch. I had a brief moment of fear that we’d need to redo the entire Kingdom, before reading the map more closely and seeing it’d “just” be 9 puzzles.
Cardinality contacted our HQ to let us know hints would be more open if we wanted them. This prompted an impromptu team vote on whether to try to rush for a Sunday 8 PM finish to guarantee a runaround slot, or take it more chill. Hunt ops estimates were that we’d finish if we took it chill, but would likely miss runaround, whereas if we rushed we’d maybe make 8 PM. Somehow all vote decisions on Level 1 Spicy are close to 50-50, but rushing won by a small margin.
In Dan Katz’s post for the year, he speculated that maybe finishing teams are succeeding because they are more willing to take hints. This year, that was definitely true for us. But, I mean, we had 32 people, cut us some slack. The word of the day was timeboxing, where we committed to taking hints if we didn’t make progress for 30-60 minutes.
Psychology: This is the one Terminus feeder I looked at during Hunt. I don’t know how, but Terminus meta crew decided it’d be faster to reconstruct the minipuzzle solutions from sheets rather than find and ask the people who worked on them. More surprisingly, this was correct.
Mixed Media: We made partial progress in our first hour on the puzzle, but didn’t get anything solid. A hint pointed us to our first ??? entry, and we finished with no hints from there. We proooooobably would have gotten there hintless, but I think it would have taken an 2 extra hours of staring to break in. I still don’t understand why this theme was picked in particular, but liked the puzzle outside of that.
With a Terminus solve, we were down to Glitch as our last round. I figured it would not help to join any on-going Glitch solve, so I instead marshalled a group to gather meta information about the glitches until a new feeder unlocked. (Sportsball would have been a fresh feeder, but we’d asked Cardinality on what we should focus on to finish Hunt, and they warned us Sportsball was long and scary.)
Find M(at)e: Man, I suck at chess puzzles. I was totally useless at doing chess. You know what I’m not useless at? Setting up extraction spreadsheet formulas. We did have a pretty tragic guess log, fueled by me trying to snipe the puzzle.
This made our guess timeout…pretty long. At the end, we were confident on every letter except the last one, but just couldn’t figure out the board, and ended up asking for a confirm on our last letter from Cardinality to avoid a 10+ minute lockout on failure. (I want it on the record that we were unanimous on what our YOLO guess would have been, and it would have been correct, it just wasn’t worth the risk.)
At least that’s the last time guess timeouts can burn us this Hunt!
snalC ehT tcennoC: Can you have too many cooks on a puzzle? Absolutely. But at least half the cooks could be distracted by pushing our “Are we cooking?” meter to 10+.
My contribution was pulling up our Connect the Clans map and reading out letter locations. I was completely blindsided by the revelation that we weren’t finished with MonQuest yet, and thought it was a cute finale that called back nicely to how capstones used MonArch and metas used feeders. Just really neat design. Our snalC ehT tcennoC solve came in at Sunday 9 PM, and Cardinality said they could schedule us for an 11:30 PM run. We spent the intervening time cleaning up our room, raising our “are we cooking?” level even higher, and eating Chipotle. (Chipotle was less for team theme and more for “what is still open.”)
Runaround!
As To The Edge indicates, the runaround started in the Borderline tunnels. I downloaded Artivive as recommended, then got the Dactylinion feeder…which used no AR information. Oh well.
We were then led to a classroom for At the Close, which was “a real puzzle”, to quote people working on the hyperbolic path. I helped on the Dactylinion and Pointdexter feeder, did my pulls, solved some of the crossword clues, then sat back and watched. There was a limit to how many people could crowd around our tiles, so we found other ways to amuse ourselves.
We’d only brought one laptop, zoomed in far enough to make clues readable from the back of the room. Unfortunately this meant the glitchy flavortext was off screen for most of the solve, and Cardinality needed to hint us to get back on track. Some of the shitposting extended to the guess log, which once again caused our answer timeout to rise pretty quickly. In the name of speed, Cardinality offered to let us check our answer with them before submitting, to make sure we didn’t get timed out on the puzzle.
Unfortunately, some people got very excited at a good looking phrase and submitted before Cardinality could stop them…

This blocked us from submitting for the next 5 minutes, and the room immediately uncooked from the highs of 🌶️🌶️🌶️ to the lows of 🔥🔥🔥. I’d say the best way to describe the vibes is that poor Cardinality is in this classroom at 1 AM, running one last runaround tonight out of the goodness of their hearts, and we replied with “You’re not cooking us, we’re cooking you”. Luckily they were able to reset our rate limit and we could finish and let them go to bed.
On Monday, I did the now traditional go to wrap-up -> loiter catching up with other teams -> eat late lunch -> get on a plane journey. I told my parents we’d finished 11th, to which my dad’s first reaction was “what a disaster”, since I hadn’t explained the team split and that it was great we’d finished at all.
Unfortunately, this year my plane was delayed by 3 hours, meaning I didn’t get land until 2 AM West Coast time, which, chronologically, was later than I’d stayed up during any day of this year’s Mystery Hunt. But JetBlue did at least give me a $12 voucher, so I got a free milkshake to drink while reading solutions.
Spicy Takes
I would normally put this at the start of my Hunt post, but decided to put it at the end, as it is both pretty disorganized and not interesting except for people who are insanely invested.
I, at broad strokes, agree with Dan Katz that hinting has gotten very effective if you are trying to finish Hunt after the Coin is found. Our vibes-based guess is that our aggressive hint posture cut 8 hours off our finish time. However, I don’t think I would characterize it as a test of talking your way to the right information. In all of 2024, 2025, and 2026, the organizing team just asked us “what would make Hunt more fun for you, now that the Coin is found?”, and we chose what we wanted. It was less a speech skill check and more picking what we wanted out of an offered buffet. Hints are pretty clearly a net fun thing and I don’t think it makes sense to try to roll them back, compared to just making Hunt easier.
More often than not, I’ve been on a team that finishes Hunt. I consider finishing Hunt to be a privilege rather than a right. I’m pretty glad we got there, but I continue to think a lot of people’s disappointments around Hunt are tied to targeting milestones that can vary wildly each year. The difficulty of Hunt, where the first meta is, where the first major HQ interaction is - these are all things that drift each year, and it’s near impossible to predict which will be in range of your team’s solving abilities. You can hope, and you can try, but it just isn’t always going to happen.
Culture evolves faster these days (I blame social media), and in puzzles this has manifested itself as the rise of online hunts and escalating puzzle complexity. There’s always been online hunts, but before there were like, 1-2 noteworthy events per year. Now there are enough that I can’t do all of them. Just last year, I did GPH 2025, LN Hunt, Teammate Hunt 2025, Microsoft Hunt 2025, and Silph Puzzle Hunt 2025, all of which had significant 3+ hour solve puzzles that would not be out of place in Mystery Hunt. Not to mention smaller hunts like Advent Hunt, and then I didn’t even do Brown Puzzlehunt or Vertex Hunt or the fall CMU Hunt. There’s just a lot out there these days. There is a real divide between people who only do Mystery Hunt each year, and people who grind all the puzzles available to them. The 18 year old crack solvers who’ve spent formative years reading devjoe’s archive are now finding each other on Discord and shitposting their way to victory. I can only imagine how weird this must be for people less online.
There is this longstanding myth where people believe teams of 100-150+ are needed to win, or becoming more common, and the stats suggest leading team sizes really haven’t changed much between 2016 to now. People regularize on their own. There are just twice as many teams, so the 10th best team is a lot better than it used to be. The competition of Hunt intrinsically favors teams that can no-life it.
To me, the crux is whether Mystery Hunt is broken, or Mystery Hunt is fine. I think it’s fine, but I suspect people’s answers depend on whether they feel they are in the in-group or the out-group. I am still on the train for general puzzles, but decidedly fell off the train for subgenres like logic puzzles, where I feel like even intro round logic puzzles can kill me these days. And this is even when I do a few logic puzzles in spare time! There’s levels to this.
Despite it all, despite thinking that the length of Hunt is fine, and hints are fine, and online teams are fine, and the MITness of Mystery Hunt is not in danger of disappearing - despite all of it, I’d be okay with a shorter Hunt. I said this last year too. While working on this post, I was reminded that I’m becoming one of the old-timers. I’ve participated in Hunt every year in one way or another since 2012, I’ve actually seen a lot. Now I’m in my 30s, trying to keep up with the youth online and only partly succeeding. I’ve crossed that threshold where a lot of Hunt is about solving with friends rather than solving many puzzles. I no longer need an extremely intense experience. A normal intense experience would be fine.

I suspect a shorter Hunt where 10 teams finish without hints would have something like 30+ teams finish in total, and people would complain about that too, that Mystery Hunt was not the Mount Everest it could have been. But you really can’t please everyone in an event this big. You just have to pick what to aim for and what you’d be proud of. I’m looking forward to seeing the choices Providence makes.